标签:情况 string sys 原因 学习 alt and rank 程序
本系列文章记录笔者关于c语言多线程编程的学习过程
平台及相关环境:Windows;MinGW64;DevC++;cmd命令行;4 CPUs
(硬件原因,没有选择Linux,原理应该差不多)
参考书籍:《并行程序设计导论》Peter S.Pacheco 著 邓倩妮 等译
以下程序理解不难,大部分不作注释
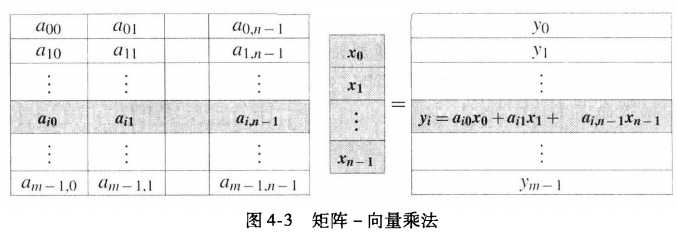
如果\(A=(a_{ij})\)是一个m*n的矩阵,\(x=(x_0,x_1,...,x_{n-1})^T\)是一个n维列向量,矩阵-向量的乘积\(Ax=y\) 是个m维的列向量。\(y=(y_0,y_1,...,y_{n-1})^T\)中的第i个元素\(y_i\)是矩阵A的第i行与x的点积:
为了与后面并行程序产生对比,利用随机数生成大量数据进行计算。为了简便,矩阵中的元素为整型,范围为[0,9]。
//generate_data.c
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define random(a,b) (rand()%(b-a+1)+a) //[a,b]
const int m = 20;
const int n = 20;
const int NUM_OF_MATRIX = 1000;
int main() {
srand((unsigned)time(NULL));
FILE *mA = fopen("matrix_A","w");
for(int i=0; i<NUM_OF_MATRIX; ++i) {
for(int j=0; j<m*n; ++j) {
fprintf(mA,"%d",(int)random(1,9));
}
fprintf(mA,"\n");
}
FILE *mx = fopen("matrix_x","w");
for(int i=0; i<NUM_OF_MATRIX; ++i) {
for(int j=0; j<n; ++j) {
fprintf(mx,"%d",(int)random(1,9));
}
fprintf(mx,"\n");
}
printf("Success");
}
得到matrix_A文件和matrix_x文件。(图中只显示部分)

《程序设计导论》给出了计算例题的矩阵-乘法 串行程序伪代码:

以下代码为笔者设计的代码:
//calculate.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<sys/time.h>
#include<stdint.h>
#define MAXL 100000005
const int m = 20;
const int n = 20;
const int DEBUG_MODE = 0;
int **A,*x,*y;
char bufferA[MAXL],bufferx[MAXL];
void init_storage() {
A = (int**) malloc(m*sizeof(int*));
for(int i=0; i<m; ++i) {
A[i] = (int*) malloc(n*sizeof(int));
}
x = (int*) malloc(n*sizeof(int));
y = (int*) malloc(m*sizeof(int));
}
void print_matrix() {
printf("Matrix A(%d rows and %d columns):\n",m,n);
for(int i=0; i<m; ++i) {
for(int j=0; j<n; ++j) {
printf("%d ",A[i][j]);
}
printf("\n");
}
printf("Matrix x(%d rows and one column):\n",n);
for(int i=0; i<n; ++i) {
printf("%d\n",x[i]);
}
printf("A*x:\n");
for(int i=0; i<m; ++i) {
printf("%d\n",y[i]);
}
}
void matrix_multi() {
for(int i=0; i<m; ++i) {
y[i]=0;
for(int j=0; j<n; ++j) {
y[i]+=A[i][j]*x[j];
}
}
}
int64_t now() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
void work(int argc, char* argv[]) {
FILE* mA = fopen(argv[1], "r");
FILE* mx = fopen(argv[2], "r");
FILE* result=fopen("result","w");
while(fgets(bufferA, sizeof bufferA, mA)!=NULL) {
if(DEBUG_MODE) printf("argv[1]:%s\n",bufferA);
int count = 0;
for(int i=0; i<m; ++i)
for(int j=0; j<n; ++j)
A[i][j]=bufferA[count++]-‘0‘;
fgets(bufferx, sizeof bufferx, mx);
if(DEBUG_MODE) printf("argv[2]:%s\n",bufferx);
count=0;
for(int i=0; i<n; ++i)
x[i]=bufferx[count++]-‘0‘;
matrix_multi();
if(DEBUG_MODE) print_matrix();
for(int i=0; i<m; ++i) {
fprintf(result,"%d ",y[i]);
}
fprintf(result,"\n");
}
}
int main(int argc, char* argv[]) {
assert(argc==3);
init_storage();
int64_t start = now();
work(argc,argv);
int64_t end = now();
double sec = (end-start)/1000000.0;
printf("%f sec\n", sec);
}
可直接在DevC++软件中编译,将calculate.cpp编译生成calculate.exe,然后在cmd命令行传参数

在result文件中可查看结果:
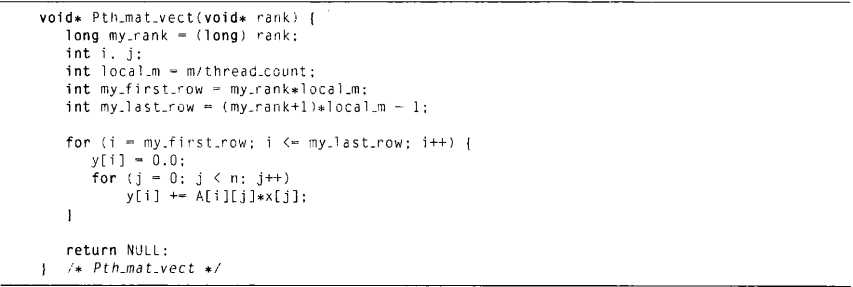
通过把工作分配给各个各个线程将程序并行化,一种分配方法是将线程外层的循环分块,每个线程计算y的一部分。
只需要编写每一个线程的代码,确定每个线程计算哪一部分的y。为了简化代码,假设m与n都能被t(线程数量)整除,每个线程能分配到m/t行的运算数据,线程0处理第一部分的m/t行,线程1处理第二部分的m/t行,以此类推。所以第q个线程处理的矩阵行是:
第一行:\(q*\frac{m}{t}\)
最后一行:\((q+1)*\frac{m}{t}-1\)
伪代码:
//thread_calculate.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<pthread.h>
#include<sys/time.h>
#include<stdint.h>
#define ll long long
#define MAXL 100000005
const int m = 1e3;
const int n = 1e3;
const int DEBUG_MODE = 0;
char bufferA[MAXL],bufferx[MAXL];
int **A,*x,*y;
int thread_count;
void init_storage() {
A = (int**) malloc(m*sizeof(int*));
for(int i=0; i<m; ++i) {
A[i] = (int*) malloc(n*sizeof(int));
}
x = (int*) malloc(n*sizeof(int));
y = (int*) malloc(m*sizeof(int));
}
void print_matrix() {
printf("Matrix A(%d rows and %d columns):\n",m,n);
for(int i=0; i<m; ++i) {
for(int j=0; j<n; ++j) {
printf("%d ",A[i][j]);
}
printf("\n");
}
printf("Matrix x(%d rows and one column):\n",n);
for(int i=0; i<n; ++i) {
printf("%d\n",x[i]);
}
printf("A*x:\n");
for(int i=0; i<m; ++i) {
printf("%d\n",y[i]);
}
}
int64_t now() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
void* Pth_mat_vect(void* rank) {
ll my_rank = (ll) rank;
int local_m = m/thread_count;
int my_first_row=my_rank*local_m;
int my_last_row = (my_rank+1)*local_m-1;
for(int i=my_first_row; i<=my_last_row; ++i) {
y[i]=0;
for(int j=0; j<n; ++j) {
y[i]+=A[i][j]*x[j];
}
}
return NULL;
}
void work(int argc, char* argv[]) {
FILE* mA = fopen(argv[1], "r");
FILE* mx = fopen(argv[2], "r");
FILE* result=fopen("result","w");
ll thread;
pthread_t* thread_handles;
thread_count = strtol(argv[3],NULL,10);
while(fgets(bufferA, sizeof bufferA, mA)!=NULL) {
if(DEBUG_MODE) printf("argv[1]:%s\n",bufferA);
int count = 0;
for(int i=0; i<m; ++i)
for(int j=0; j<n; ++j)
A[i][j]=bufferA[count++]-‘0‘;
fgets(bufferx, sizeof bufferx, mx);
if(DEBUG_MODE) printf("argv[2]:%s\n",bufferx);
count=0;
for(int i=0; i<n; ++i)
x[i]=bufferx[count++]-‘0‘;
thread_handles = (pthread_t *)malloc(thread_count*sizeof(pthread_t));
for(thread = 0; thread<thread_count; thread++) {
pthread_create(&thread_handles[thread],NULL,
Pth_mat_vect,(void*) thread);
}
// printf("Hello from the main thread\n");
for(thread = 0; thread<thread_count; thread++) {
pthread_join(thread_handles[thread],NULL);
}
free(thread_handles);
if(DEBUG_MODE) print_matrix();
for(int i=0; i<m; ++i) {
fprintf(result,"%d ",y[i]);
}
fprintf(result,"\n");
}
}
int main(int argc, char* argv[]) {
assert(argc==4);
init_storage();
int64_t start = now();
work(argc,argv);
int64_t end = now();
double sec = (end-start)/1000000.0;
printf("%f sec\n", sec);
}
和2.3类似,这里多设置了一个参数即线程数量。
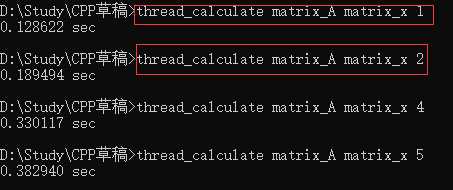
可以对比,使用多线程数量耗时竟然还长。笔者也有点慌。不急,先假设不是代码思路的锅,而是数据规模过小,导致创建多线程等所耗的时间要多得多。
因此,重新生成数据,扩大规模试一波:
测试到这一步,后知后觉的笔者知道了前面并行计算的设计一定出了问题。反反复复的创建、销毁多线程耗费了太多时间。
因此将矩阵数量设置为1,扩大矩阵规模,再进行测试:

终于让笔者看到了希望,多线程不是假的。
现在情况应该比较明朗了,创建一次多线程即可,每个线程函数要处理多个矩阵的某一部分计算。这也许需要预先保存多个矩阵。(可以理解为化在线为离线了吧)
同时,前面的代码测试的时间都包括了读数据、写数据等。为了更好的对比时间的花费,将上面的两份代码都转化为离线的并且仅测试矩阵乘法部分。
//calculate2.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<sys/time.h>
#include<stdint.h>
#define MAXL 100000005
const int m = 20;
const int n = 20;
const int num_of_matrix = 1e5;
int ***A,**x,**y;
char bufferA[MAXL],bufferx[MAXL];
void init_storage() {
A = (int***) malloc(num_of_matrix*sizeof(int**));
for(int i=0; i<num_of_matrix; ++i) {
A[i] = (int**) malloc(m*sizeof(int*));
for(int j=0; j<m; ++j) {
A[i][j] = (int*)malloc(n*sizeof(int));
}
}
x = (int**) malloc(num_of_matrix*sizeof(int*));
for(int i=0; i<num_of_matrix; ++i) {
x[i] = (int*) malloc(n*sizeof(int));
}
y = (int**) malloc(num_of_matrix*sizeof(int*));
for(int i=0; i<num_of_matrix; ++i) {
y[i] = (int*) malloc(m*sizeof(int));
}
}
void matrix_multi(int k) {
for(int i=0; i<m; ++i) {
y[k][i]=0;
for(int j=0; j<n; ++j) {
y[k][i]+=A[k][i][j]*x[k][j];
}
}
}
int64_t now() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
void work(int argc, char* argv[]) {
FILE* mA = fopen(argv[1], "r");
FILE* mx = fopen(argv[2], "r");
FILE* result=fopen("result","w");
int k = 0;
while(fgets(bufferA, sizeof bufferA, mA)!=NULL) {
int count = 0;
for(int i=0; i<m; ++i)
for(int j=0; j<n; ++j)
A[k][i][j]=bufferA[count++]-‘0‘;
fgets(bufferx, sizeof bufferx, mx);
count=0;
for(int i=0; i<n; ++i)
x[k][i]=bufferx[count++]-‘0‘;
k++;
}
int64_t start = now();
for(k=0;k<num_of_matrix;++k)
matrix_multi(k);
int64_t end = now();
double sec = (end-start)/1000000.0;
printf("%f ms\n", 1000*sec);
printf("k: %d\n",k);
for(k=0; k<num_of_matrix; ++k) {
for(int i=0; i<m; ++i) {
fprintf(result,"%d ",y[k][i]);
}
fprintf(result,"\n");
}
}
int main(int argc, char* argv[]) {
assert(argc==3);
init_storage();
work(argc,argv);
}
//thread_calculate.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
#include<pthread.h>
#include<sys/time.h>
#include<stdint.h>
#define ll long long
#define MAXL 100000005
const int m = 20;
const int n = 20;
const int num_of_matrix = 1e5;
char bufferA[MAXL],bufferx[MAXL];
int ***A,**x,**y;
int thread_count;
void init_storage() {
A = (int***) malloc(num_of_matrix*sizeof(int**));
for(int i=0; i<num_of_matrix; ++i) {
A[i] = (int**) malloc(m*sizeof(int*));
for(int j=0; j<m; ++j) {
A[i][j] = (int*)malloc(n*sizeof(int));
}
}
x = (int**) malloc(num_of_matrix*sizeof(int*));
for(int i=0; i<num_of_matrix; ++i) {
x[i] = (int*) malloc(n*sizeof(int));
}
y = (int**) malloc(num_of_matrix*sizeof(int*));
for(int i=0; i<num_of_matrix; ++i) {
y[i] = (int*) malloc(m*sizeof(int));
}
}
int64_t now() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000 + tv.tv_usec;
}
void* Pth_mat_vect(void* rank) {
ll my_rank = (ll) rank;
int local_m = m/thread_count;
int my_first_row=my_rank*local_m;
int my_last_row = (my_rank+1)*local_m-1;
for(int k=0; k<num_of_matrix; ++k) {
for(int i=my_first_row; i<=my_last_row; ++i) {
y[k][i]=0;
for(int j=0; j<n; ++j) {
y[k][i]+=A[k][i][j]*x[k][j];
}
}
}
return NULL;
}
void work(int argc, char* argv[]) {
FILE* mA = fopen(argv[1], "r");
FILE* mx = fopen(argv[2], "r");
FILE* result=fopen("result","w");
int k = 0;
while(fgets(bufferA, sizeof bufferA, mA)!=NULL) {
int count = 0;
for(int i=0; i<m; ++i)
for(int j=0; j<n; ++j)
A[k][i][j]=bufferA[count++]-‘0‘;
fgets(bufferx, sizeof bufferx, mx);
count=0;
for(int i=0; i<n; ++i)
x[k][i]=bufferx[count++]-‘0‘;
k++;
}
ll thread;
pthread_t* thread_handles;
thread_count = strtol(argv[3],NULL,10);
int64_t start = now();
thread_handles = (pthread_t *)malloc(thread_count*sizeof(pthread_t));
for(thread = 0; thread<thread_count; thread++) {
pthread_create(&thread_handles[thread],NULL,
Pth_mat_vect,(void*) thread);
}
for(thread = 0; thread<thread_count; thread++) {
pthread_join(thread_handles[thread],NULL);
}
int64_t end = now();
double sec = (end-start)/1000000.0;
printf("%f ms\n", 1000*sec);
free(thread_handles);
printf("k: %d\n",k);
for(int k=0; k<num_of_matrix; ++k) {
for(int i=0; i<m; ++i) {
fprintf(result,"%d ",y[k][i]);
}
fprintf(result,"\n");
}
}
int main(int argc, char* argv[]) {
assert(argc==4);
init_storage();
work(argc,argv);
}

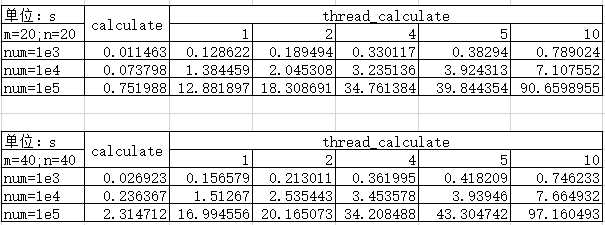
可以发现多线程不是开玩笑的(废话)。由于笔者电脑是有4个cpu,所以线程数为4的时候表现最好
以上数据均为测试多次取平均值(有时候嫌计算麻烦取了中位数)
初入并行程序设计,不当之处在所难免
标签:情况 string sys 原因 学习 alt and rank 程序
原文地址:https://www.cnblogs.com/wangzhebufangqi/p/12552837.html