<!–…–>:定义注释
<!DOCTYPE> :定义文档类型
<html>:html文档的总标签
<head>:定义头部
<body>:定义网页内容
<script>:定义脚本
<div>:division,定义分区,容器标签
<p>:paragraph,定义段落
<a>:定义超链接
<span>:定义文本容器
<br>:换行
<form>:定义表单
<table>:定义表格
<th>:定义表头
<tr>:表的行
<td>:表的列
<b>:定义粗体字
<img>:定义图片
标签:查找 环境配置 height win 管理 观察 变量 orm art
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
你可以简单地想象:每个爬虫都是你的“分身”。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样。
你每天使用的百度,其实就是利用了这种爬虫技术:每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。
抢票软件,就相当于撒出去无数个分身,每一个分身都帮助你不断刷新 12306 网站的火车余票。一旦发现有票,就马上拍下来,然后对你喊:土豪快来付款。--摘自知乎用户 史中
<!–…–>:定义注释
<!DOCTYPE> :定义文档类型
<html>:html文档的总标签
<head>:定义头部
<body>:定义网页内容
<script>:定义脚本
<div>:division,定义分区,容器标签
<p>:paragraph,定义段落
<a>:定义超链接
<span>:定义文本容器
<br>:换行
<form>:定义表单
<table>:定义表格
<th>:定义表头
<tr>:表的行
<td>:表的列
<b>:定义粗体字
<img>:定义图片
import re import urllib.request import chardet response=urllib.request.urlopen("http://news.hit.edu.cn/")#输入参数为你想爬取的网页URL html=response.read() #读取到html变量中 chardet1=chardet.detect(html) #获取编码方式 html=html.decode(chardet1[‘encoding‘]) #按照获取到的编码方式进行处理
这里我们以某高校的官方新闻网站为例演示来进行python爬虫操作,上面短短的几行代码就实现了将网页内容爬取到本地的操作。
接着就是对爬取到的内容进行正则表达式处理,得到我们想要获取的内容,观察网页源代码:

我们希望对其中的外部链接进行匹配,由之前了解到的正则表达式知识,实现如下:
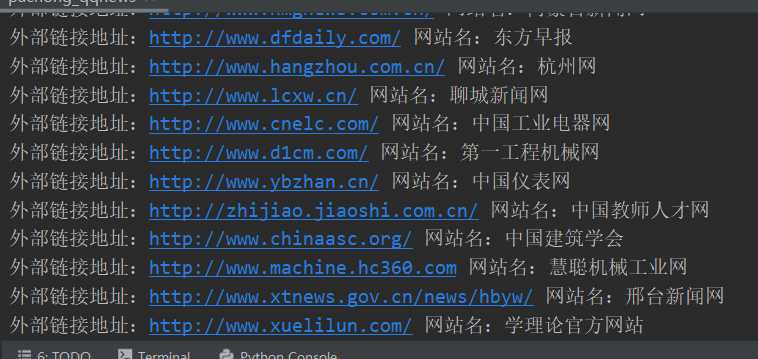
mypatten="<li class=\"link-item\"><a href=\"(.*)\"><span>(.*)</span></a></li>" mylist=re.findall(mypatten,html) for i in mylist: print("外部链接地址:%s 网站名:%s" %(i[0],i[1]))
最后得到的效果是:
除了用正则表达式处理得到的网页文档之外,我们还可以考虑网页自身的架构。
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在XML文档中查找信息的语言。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于 HTML 文档的搜索。
nodename选取此节点的所有子节点
/从当前节点选取直接子节点
//从当前节点选取子孙节点
.选取当前节点
..选取当前节点的父节点
@选取属性
在这里列出了XPath的常用匹配规则,例如 / 代表选取直接子节点,// 代表选择所有子孙节点,. 代表选取当前节点,.. 代表选取当前节点的父节点,@ 则是加了属性的限定,选取匹配属性的特定节点。
from lxml import etree import urllib.request import chardet response=urllib.request.urlopen("https://www.dahe.cn") html=response.read() chardet1=chardet.detect(html) html=html.decode(chardet1[‘encoding‘]) etreehtml=etree.HTML(html) mylist=etreehtml.xpath("/html/body/div/div/div/div/div/ul/div/li")
BeautifulSoup4是爬虫必学的技能。BeautifulSoup最主要的功能是从网页抓取数据,Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
from bs4 import BeautifulSoup file = open(‘./aa.html‘, ‘rb‘) html = file.read() bs = BeautifulSoup(html,"html.parser") # 缩进格式 print(bs.prettify()) # 格式化html结构 print(bs.title) # 获取title标签的名称 print(bs.title.name) # 获取title标签的文本内容 print(bs.title.string) # 获取head标签的所有内容 print(bs.head) # 获取第一个div标签中的所有内容 print(bs.div) # 获取第一个div标签的id的值 print(bs.div["id"]) # 获取第一个a标签中的所有内容 print(bs.a) # 获取所有的a标签中的所有内容 print(bs.find_all("a")) # 获取id="u1" print(bs.find(id="u1")) # 获取所有的a标签,并遍历打印a标签中的href的值 for item in bs.find_all("a"): print(item.get("href")) # 获取所有的a标签,并遍历打印a标签的文本值 for item in bs.find_all("a"): print(item.get_text())
标签:查找 环境配置 height win 管理 观察 变量 orm art
原文地址:https://www.cnblogs.com/upuphe/p/12556357.html