标签:int lse __name__ 详细 ada img 支持 from att
最近为了实现HR-net在学习pytorch,然后突然发现这个框架简直比tensorflow要方便太多太多啊,我本来其实不太喜欢python,但是这个框架使用的流畅性真的让我非常的喜欢,下面我就开始介绍从0开始编写一个Lenet并用它来训练cifar10。
1.首先需要先找到Lenet的结构图再考虑怎么去实现它,在网上找了一个供参考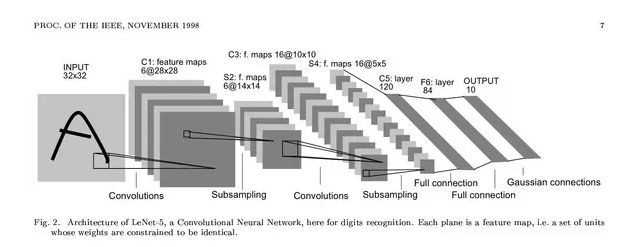
2.需要下载好cifar-10的数据集,在pytorch下默认的是下载cifar-10-python版本的,由于官网速度较慢,我直接提供度娘网盘的链接:链接:https://pan.baidu.com/s/18LNEZmGVkzEwf3SgOrO2rw 密码:n1h7
3.下载好数据集后,需要定义网络的结构,根据图我们可以看出,整个lenet只有两个卷积层,两个池化层(其实应该叫降采样层,那个时候还没有池化),三个全连接层。
pytorch中有一个容器,叫做Sequential,你可以在这个容器里添加你需要使用的卷积,池化,全连接操作,但是,这个Sequential它只能包含类方法定义的层,而不能包含像torch.Functional里面的函数方法(可能我说的不专业,见谅),所以如果当你想自己定义某个层的话,例如在输入全连接层之前,需要将形如[batch_size,channel,higth,width]的tensor转化成[batch_size,channel*higth*width]这种形式,那我如果想在Sequential这个容器里加入这一个操作该怎么办呢,这时候就需要我们继承nn.Module这个类来实现,具体的方法如下
import torch import torch.nn as nn class Flatten(nn.Module): def __init__(self): super(Flatten, self).__init__() def forward(self,input): out=input.view(input.size(0),-1) return out
好了,介绍完Sequential我们就开始实现这个网络的结构吧
#文件名是Lenet5.py import torch import torch.nn as nn from pytorch__lesson.pytorch_mnist.main import Flatten class Lenet(nn.Module): def __init__(self): super(Lenet, self).__init__() self.net=nn.Sequential( nn.Conv2d(3,6,5,stride=1,padding=0), nn.MaxPool2d(kernel_size=2,stride=2,padding=0), nn.Conv2d(6,16,5,stride=1,padding=0), nn.MaxPool2d(kernel_size=2,stride=2,padding=0), Flatten(), nn.Linear(400,120), nn.ReLU(inplace=True), nn.Linear(120,84), nn.ReLU(inplace=True), nn.Linear(84,10), nn.ReLU(inplace=True) ) # self.criteon=nn.CrossEntropyLoss() def forward(self,x): logits= self.net(x) # pred=nn.Softmax(logits,dim=1),这一行不需要写,因为在CrossEntropyLoss这一步包含了softmax的操作 return logits # net=Lenet() # input=torch.randn(2,3,32,32) # out=net(input) # print(out.shape)
其中这里面的Flatten就是上面代码的Flatten类。因为它继承了nn.Module因此可以直接将其放在Sequential里面了,以后定义任何网络,我们都可以使用这个类来进行tensor的展平操作。
4.接下来就可以定义训练部分的代码了
import torch from torchvision import datasets,transforms from torch.utils.data import DataLoader import torch.nn as nn import torch.optim as optim import torch.functional as F from pytorch__lesson.pytorch_mnist.Lenet5 import Lenet batch_size=32 def main(): # cifar表示的是在当前的目录下新建一个叫cifar的文件夹,这个方法一次只能加载一张 cifar_train=datasets.CIFAR10(‘cifar‘,train=True,transform=transforms.Compose([ transforms.Resize((32,32)), transforms.ToTensor() ]),download=True) # 这个方法才能保证一次读取进来的是一个batch_size大小的数据 cifar_train_loader=DataLoader(cifar_train,batch_size=batch_size,shuffle=True) cifar_test=datasets.CIFAR10(‘cifar‘,train=False,transform=transforms.Compose([ transforms.Resize((32,32)), transforms.ToTensor() ])) cifar_test_loader=DataLoader(cifar_test,batch_size=batch_size,shuffle=False) x,label=iter(cifar_train_loader).next() print(‘x shapex:‘,x.shape,‘label shape:‘,label.shape) # use CrossEntropy as the loss function criteon=nn.CrossEntropyLoss() # use Lenet() function to build a model # net=Lenet().to(device) 将模型放入cuda上进行加速 net=Lenet() optimizer=optim.Adam(net.parameters(),lr=1e-3) # device=torch.device(‘cuda‘) # net=Lenet().to(device) 将模型放入cuda上进行加速 print(net) for epoch in range(1000): for batchidx,(x,label) in enumerate(cifar_train_loader): # 生成软对数 # 将网络转化成train的模式 net.train() logits=net(x) # x,label=x.to(device),label.to(device) # 使用crossentropyloss的就不需要将logits放入到softmax中了,直接就可以计算出loss loss=criteon(logits,label) #接下来进行反向的传播,先是将梯度清零,再进行反向传播,再进行梯度更新 optimizer.zero_grad() loss.backward() optimizer.step() # loss是一个tensor scalor 是一个长度为0的标量 print(epoch,loss.item()) net.eval() with torch.no_grad(): # 将整个网络转换成test模式或者validation模式 # test这一部分不需要构造计算图也不需要统计梯度,因此将这部分放在函数torch.no_grad() total_correct=0 total_num=0 for x,label in cifar_test_loader: # 如果有gpu的话先将x和label放入gup进行加速 # [batch_size,10] logits=net(x) # 取出最大下标的索引[b] pred=logits.argmax(dim=1) # eq函数调用后会返回一个byte,true或者false估计,然后需要将其转换成float类型再通过item()函数来提取它的值 total_correct+=torch.eq(label,pred).float().sum() total_num+=x.size(0) acc=total_correct/total_num print(epoch,‘the acc of the test is :‘,(acc*100)) if __name__==‘__main__‘: main()
因为我的电脑没有英伟达的显卡,不支持cuda加速,因此的话没办法都训练出来截图,如果有N卡的,可以自己试试,注释写的比较详细,我就不再赘述了,不是很难。
ps:我太唠叨了吧??
标签:int lse __name__ 详细 ada img 支持 from att
原文地址:https://www.cnblogs.com/daremosiranaihana/p/12564245.html