标签:软件 特点 编程 假设 原来 http 依次 编号 alt
关注公众号 MageByte,设置星标点「在看」是我们创造好文的动力。后台回复 “加群” 进入技术交流群获更多技术成长。
数组对于每一门编程语言来说都是重要的数据结构之一,当然不同语言对数组的实现及处理也不尽相同。Java 语言中提供的数组是用来存储固定大小的同类型元素。
你一定会说数组这么简单,有啥说的。嘿嘿嘿,里面包含的玄机可不一定每个人都知道。

今天的疑惑来了…..
数组几乎都是从 0 开始编号的,有没有想过 为啥数组从 0 开始编号,而不是从 1 开始呢? 使用 1 不是更符合人类的思维么?
数组是一种线性表数据结构,用一组连续的内存空间来存储一组具有相同类型的数据。
里面出现了几个重要关键字,线性表、连续内存空间和相同类型数据,这里解释下每个关键词的含义。
就是数据排成像线一样的结构,就像我们的高铁 G1024 号,每节车厢首尾相连,数据最多只有「前」和「后」两个方向。除了数组,链表,队列,栈都是线性结构。
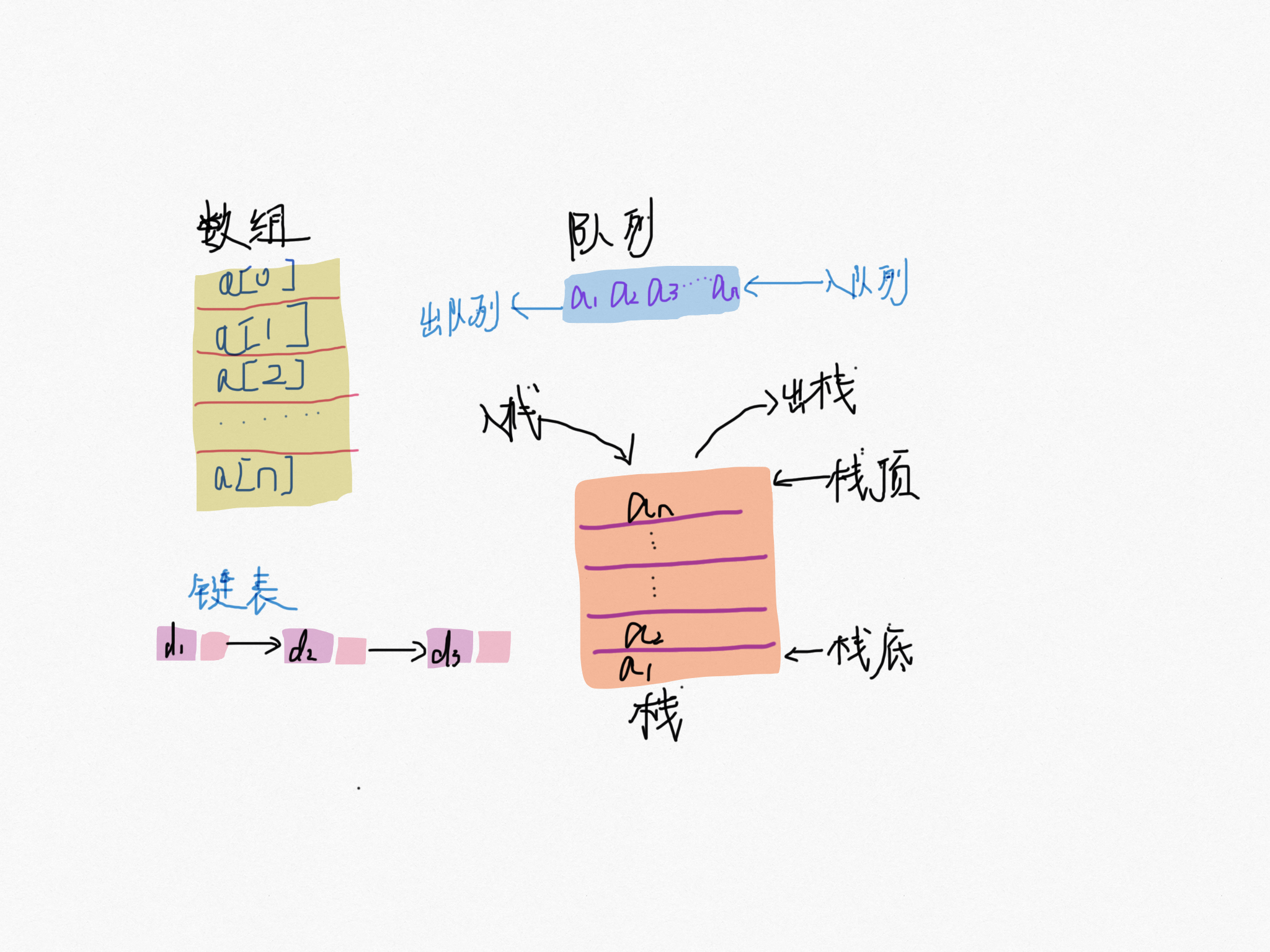
比如二叉树、堆、图等。之所以叫非线性,是因为,在非线性表中,数据之间并不是简单的前后关系。
正式由于它具有连续的内存空间和相同的数据类型的数据。就有一个牛逼特性:「随机访问」。很多人面试的时候一定被问数组与链表有什么区别?多数会回答 “链表适合插入、删除,时间复杂度 O(1);数组适合查找,查找时间复杂度为 O(1)”。
这个回答并不严谨。适合查找,但是查找的时间复杂度并不是 O(1),即便是已经排序好的数据,你用二分法查找时间复杂度也是 O(logn)。正确的应该是,数组支持随机访问,根据下表随机访问的时间复杂度为 O(1)。
我们都知道数组是根据下表访问数据的,它是如何实现随机访问呢?
用一个长度 4 的 int 类型的数组 int[] a = new int[4] 举例,首先计算机给数组 a 分配了一块连续内存空间 1000~1015。int 类型占 4 个字节,所以一共占有 4*4字节。内存块的首地址 base_address = 1000。当程序随机访问数组中的第 i 个元素,计算机通过以下寻址公式计算出内存地址。
targetAddress = base_address + i * data_type_size首地址就像高铁 G1024 编号,每节车厢就是数组的的下标位置,每节车厢的座位就像一个个字节长度。
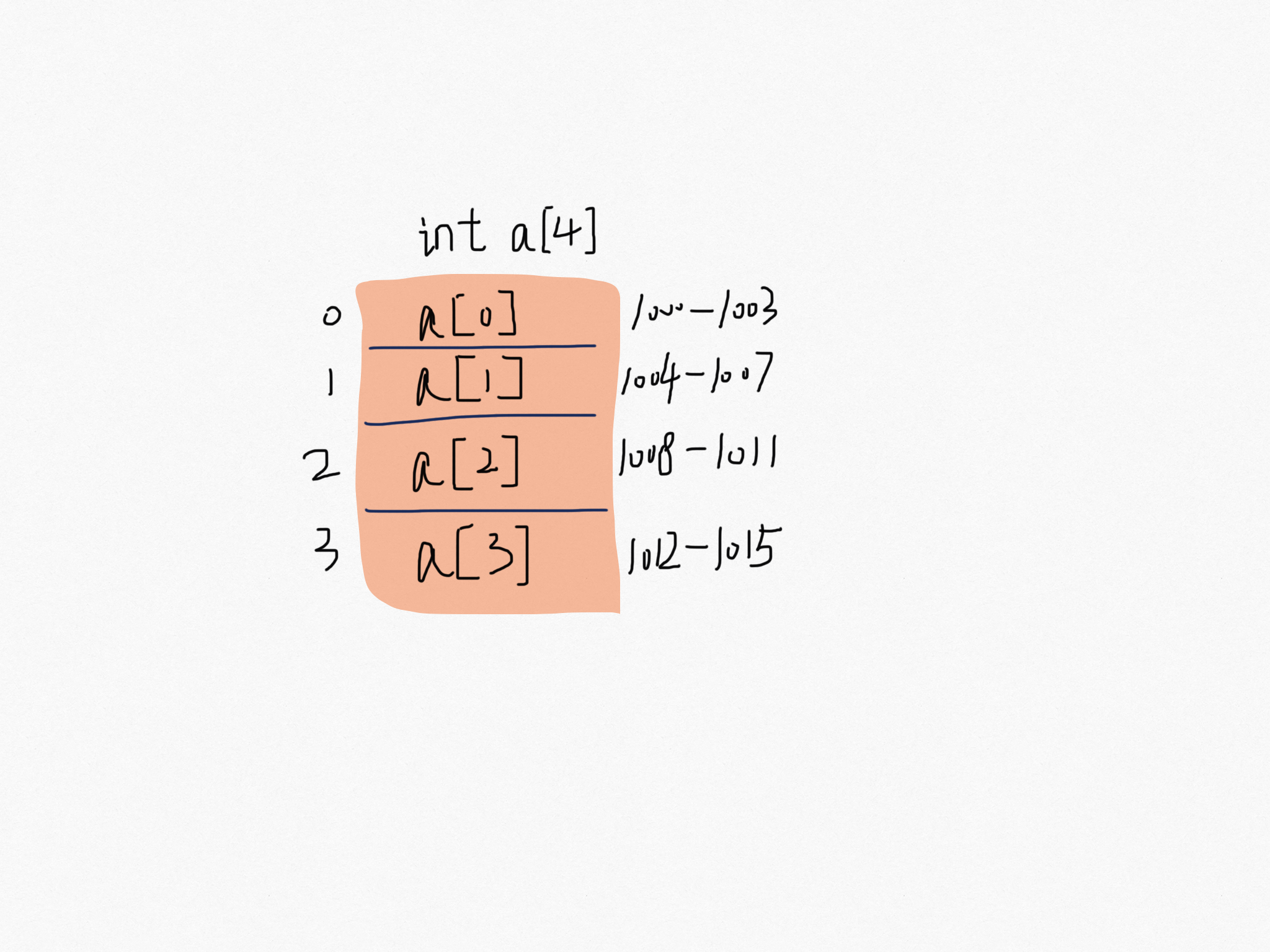
敲黑板了:同学们,数组寻址公式就是这儿回事。这个公式也是最后解释为何 下标从 0 开始的铺垫。
“下标”最确切的定义应该是“偏移(offset)”。前面也讲到,如果用 base_address 来表示数组的首地址,a[0] 就是偏移为 0 的位置,也就是首地址,a[i] 就表示偏移 i 个 data_type_size 的位置,所以计算 a[i] 的内存地址只需要用这个公式:
targetAddress[i] = base_address + i * data_type_size现在问题来了,假如数组下标从 1 开始,计算 a[i] 的内存地址公式就需要改成:
targetAddress[i] = base_address + (i - 1) * data_type_size重点来了,对比两个公式,从 1 开始每次随机访问数组元素都多了一次减法运算,相当于多执行了一次减法指令。
数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。
当然这不能说是绝对,也可能是历史原因,C 语言设计是从 0 开始,后面的高级语言都效仿,也方便程序猿很快的适应,减少学习成本。
有利有弊,这个限制也导致数组的删除、插入这种操作变得低效,为了保证内存连续性,就需要做数据移动工作。
那有没有什么改进方式呢?
数组长度为 n,将一个元素插入到数组的第 k 个位置。为了满足连续性我们需要把 k 这个位置腾出来,给新插入的数据占坑,然后把 k 到 n 这部分的数据都往后移动一位。这个插入的时间复杂度是多少呢?我们来分析下,顺便学习下时间与空间复杂度分析。
当在数组的末尾插入元素,那就不需要移动数据,所以「最好时间复杂度」为 O(1)。当插入的位置在数组的开头,那所有的数据都需要依次往后移动一位,所有最坏时间复杂度 O(n)。而我们在每个位置插入元素概率是一样的,所以平均时间复杂度 就是 $$\frac {(1+2+3+…+n)} {n} = O(n)$$。
优化思路-鸠占鹊巢
如果数组中的顺序是有序,我们就需要移动 k 之后的数据,假如数组中存放的数据无序,只是作为一个存放数据的集合,要将某个元素插入到数组 k 位置,我们可以把原来在 k 位置的元素放到数组的最后,把新插入的元素放入 k 这个位置,时间复杂度就降低到了 O(1)。
同理,假设我们要删除 第 k 个位置的数据,如果 k = n-1,那么最好时间复杂度就是 O(1)。若果 k = 0,最坏时间复杂度 O(n)。平均时间复杂度也是 O(n)。
优化思路-标记-批量执行
实际上,在某些场合并不需要非要追求数据的连续性。可以将多次的删除操作批量执行。
比如数组 number[6]中存储了 6 个 int 类型的元素:1、2、3、4、5、6。依次删除 1、2、3。三个元素。防止每次删除都需要移动数据,我们只要标记数据已经被删除,当达到删除阈值,比如是 3,才执行移动数据的操作,这个时候才执行移动操作,大大减少了数据搬移。
你会发现,这不就是 JVM 标记清除垃圾回收算法的核心思想吗?没错,数据结构和算法的魅力就在于此,很多时候我们并不是要去死记硬背某个数据结构或者算法,而是要学习它背后的思想和处理技巧,这些东西才是最有价值的。如果你细心留意,不管是在软件开发还是架构设计中,总能找到某些算法和数据结构的影子。
数组用一块连续的内存空间,来存储相同类型的一组数据,最大的特点就是支持随机访问,但插入、删除操作也因此变得比较低效,平均情况时间复杂度为 O(n)。在平时的业务开发中,我们可以直接使用编程语言提供的容器类,但是,如果是特别底层的开发,直接使用数组可能会更合适。
问题来了
基于数组删除操作我们提出一个优化思路:标记-批量清除思想,在 Java 的 JVM 中,垃圾回收的标记清除算法是什么么?欢迎加群分享你的想法或者后台回复 「标记清除」获取答案。
欢迎加群与我们讨论分享,我们第一时间反馈。
推荐阅读

标签:软件 特点 编程 假设 原来 http 依次 编号 alt
原文地址:https://blog.51cto.com/14745561/2481644