标签:ble 写入 自动提交 mode detail mysql 复制 strcmp 读取 字段名

tinyint, # 占1字节,有符号:-128~127,无符号位:0~255 smallint, # 占2字节,有符号:-32768~32767,无符号位:0~65535 mediumint,# 占3字节,有符号:-8388608~8388607,无符位:0~16777215 int, # 占4字节,有符号:-2147483648~2147483647,无符号位:0~4284967295 bigint,# 占8字节 bool 等价于tinyint(1) 布尔型
float([m[,d]]) # 占4字节,1.17E-38~3.4E+38 double([m[,d]]) # 占8字节 decimal([m[,d]]) # 以字符串形式表示的浮点数
char([m]): # 固定长度的字符,占用m字节 varchar[(m)]: # 可变长度的字符,占用m+1字节,大于255个字符:占用m+2 tinytext, # 255个字符(2的8次方) text, # 65535个字符(2的16次方) mediumtext, # 16777215字符(2的24次方) longtext, # (2的32次方) enum(value,value,...) # 占1/2个字节 最多可以有65535个成员 set(value,value,...) # 占1/2/3/4/8个字节,最多可以有64个成员
# 使用select命令查看mysql数据库系统信息: #-- 打印当前的日期和时间 select now(); #-- 打印当前的日期 select curdate(); # -- 打印当前的时间 select curtime(); # -- 打印当前数据库 select database(); # -- 打印MySQL版本 select version(); #-- 打印当前用户 select user(); # --查看系统信息 show variables; show global variables; show global variables like ‘%version%‘; show variables like ‘%storage_engine%‘; # 默认的存储引擎 # like模糊搜索还可用户where字句,例如 select * from students where stname like ‘%l%1%2%3%‘; # 除了like 还有not like show engines; # 查看支持哪些存储引擎 # --查看系统运行状态信息 show status; show global status like ‘Thread%‘;
语法
# SELECT field1, field2,...fieldN FROM table_name1, table_name2... # ORDER BY field1 [ASC [DESC][默认 ASC]], [field2...] [ASC [DESC][默认 ASC]]
案例
# 查询年龄在18到34岁之间的男性,按照年龄从小到大到排序 # select * from students where (age between 18 and 34) and gender = 1 order by age asc; # 查询年龄在18到34岁之间的女性,身高从高到矮排序 # select * from students where (age between 18 and 34) and gender = 2 order by height desc;
# 查询年龄在18到34岁之间的女性,身高从高到矮排序, 如果身高相同的情况下按照年龄从小到大排序 # select * from students where (age between 18 and 34) and gender = 2 order by height desc,age asc; # 查询年龄在18到34岁之间的女性,身高从高到矮排序, 如果身高相同的情况下按照年龄从小到大排序,如果年龄也相同那么按照id从大到小排序 # select * from students where (age between 18 and 34) and gender = 2 order by height desc,age asc,id desc;

# mysql> select bName,price from books where price in (50,60,70) order by price asc; +--------------------------------------+-------+ | bName | price | +--------------------------------------+-------+ | Illustrator 10完全手册 | 50 | | FreeHand 10基础教程 | 50 | | 网站设计全程教程 | 50 | | ASP数据库系统开发实例导航 | 60 | | Delphi 5程序设计与控件参考 | 60 | | ASP数据库系统开发实例导航 | 60 |
# mysql> select bName,price from books where price in (50,60,70) order by price desc; +--------------------------------+-----------------+ | bName | price | +--------------------------------+-----------------+ | ASP数据库系统开发实例导航 | 60 | | Delphi 5程序设计与控件参考 | 60 | | ASP数据库系统开发实例导航 | 60 | | Illustrator 10完全手册 | 50 | | FreeHand 10基础教程 | 50 | | 网站设计全程教程 | 50 |
select bName,price from books where price in (50,60,70) order by price desc,bName desc;
MySQL GROUP BY 语句
GROUP BY 语法
# SELECT column_name, function(column_name) # FROM table_name # WHERE column_name operator value # GROUP BY column_name;
实例演示
SET NAMES utf8; SET FOREIGN_KEY_CHECKS =0; -- ---------------------------- -- Table structure for`employee_tbl` -- ---------------------------- DROP TABLE IF EXISTS `employee_tbl`; CREATE TABLE `employee_tbl`( `id`int(11) NOT NULL, `name`char(10) NOT NULL DEFAULT ‘‘, `date` datetime NOT NULL, `singin` tinyint(4) NOT NULL DEFAULT ‘0‘ COMMENT ‘登录次数‘, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of `employee_tbl` -- ----------------------------BEGIN; INSERT INTO `employee_tbl` VALUES (‘1‘,‘小明‘,‘2016-04-22 15:25:33‘,‘1‘), (‘2‘,‘小王‘,‘2016-04-20 15:25:47‘,‘3‘),(‘3‘,‘小丽‘,‘2016-04-19 15:26:02‘,‘2‘), (‘4‘,‘小王‘,‘2016-04-07 15:26:14‘,‘4‘),(‘5‘,‘小明‘,‘2016-04-11 15:26:40‘,‘4‘), (‘6‘,‘小明‘,‘2016-04-04 15:26:54‘,‘2‘); COMMIT; SET FOREIGN_KEY_CHECKS =1;
# mysql>set names utf8; # mysql> SELECT * FROM employee_tbl; +----+--------+------------------+--------+ | id | name | date | singin | +----+--------+------------------+--------+ |1 |小明 |2016-04-2215:25:33 |1| |2 |小王 |2016-04-2015:25:47 |3| |3 |小丽 |2016-04-1915:26:02 |2| |4 |小王 |2016-04-0715:26:14 |4| |5 |小明 |2016-04-1115:26:40 |4| |6 |小明 |2016-04-0415:26:54 |2| +----+--------+------------------+--------+ 6 rows inset(0.00 sec)
# mysql> SELECT name, COUNT(*) FROM employee_tbl GROUP BY name; +--------+----------+ | name | COUNT(*)| +--------+----------+ |小丽 | 1| |小明 | 3| |小王 | 2| +--------+----------+ 3 rows inset(0.01 sec)
使用 WITH ROLLUP
# mysql> SELECT name, SUM(singin)as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP; +--------+--------------+ | name | singin_count | +--------+--------------+ |小丽 | 2| |小明 | 7| |小王 | 7| | NULL | 16| +--------+--------------+ 4 rows inset(0.00 sec)
# select coalesce(a,b,c);
# mysql> SELECT coalesce(name,‘总数‘), SUM(singin)as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP; +--------------------------+--------------+ | coalesce(name,‘总数‘)| singin_count | +--------------------------+--------------+ |小丽 | 2| |小明 | 7| |小王 | 7| |总数 | 16| +--------------------------+--------------+ 4 rows inset(0.01 sec)
JOIN 按照功能大致分为如下三类:
示例:
常用的连接:
内连接:
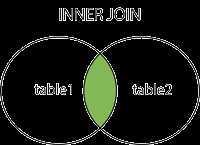
# select 字段 from 表1 inner join 表2 on 表1.字段=表2.字段
# 测试 select a.bname,a.price,b.btypename from books a inner join category b on a.btypeid=b.btypeid; # 实际使用中inner可省略掉 # 跟WHERE 子句结果一样 select a.bname,a.price,b.btypename from books a, category b where a.btypeid=b.btypeid;
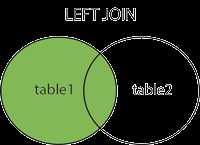
# 左连接: select 字段 from a表 left join b表 on 连接条件 # a表是主表,都显示。 # b表从表 # 主表内容全都有,从表内没有的显示null。 Select a.bname,a.price,b.btypename from books a left join category b on a.btypeid=b.btypeid;
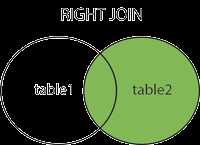
# 右连接:select 字段 from a表 right join b表 on 条件 # a表是从表, # b表主表,都显示。 Select a.bname,b.* from books a right join category b on a.btypeid=b.btypeid; # 右连接,可以多表连接
inner join ... on select ... from 表A inner join 表B; select * from students inner join classes; # 查询 有能够对应班级的学生以及班级信息 select * from students inner join classes on students.cls_id = classes.id; # 按照要求显示姓名、班级 select students.name,classes.name from students inner join classes on students.cls_id = classes.id; # 给数据表起名字 select s.name,c.name from students as s inner join classes as c on s.cls_id = c.id; # 查询 有能够对应班级的学生以及班级信息,显示学生的所有信息 students.*,只显示班级名称 classes.name. select s.*,c.name from students as s inner join classes as c on s.cls_id = c.id; # 在以上的查询中,将班级姓名显示在第1列 select c.name,s.* from students as s inner join classes as c on s.cls_id = c.id; # 查询 有能够对应班级的学生以及班级信息, 按照班级进行排序 select c.xxx s.xxx from students as s inner join clssses as c on .... order by ....; select c.name,s.* from students as s inner join classes as c on s.cls_id = c.id order by c.name; # 当时同一个班级的时候,按照学生的id进行从小到大排序 select c.name,s.* from students as s inner join classes as c on s.cls_id = c.id order by c.name,id asc; # left join # 查询每位学生对应的班级信息 select * from students left join classes on students.cls_id = classes.id; # right join select * from students right join classes on students.cls_id = classes.id; # 查询没有对应班级信息的学生 # 语句 select ... from xxx as s left join xxx as c on..... where ..... select ... from xxx as s left join xxx as c on..... having ..... # 列 select * from students left join classes on students.cls_id = classes.id where classes.name is null; #(注意)不建议使用 select * from students left join classes on students.cls_id=classes.id having classes.id is null; # right join on # 将数据表名字互换位置,用left join完成 应用示例
为了处理这种情况,MySQL提供了三大运算符:
# 注意: select * , columnName1+ifnull(columnName2,0) from tableName; # columnName1,columnName2 为 int 型,当 columnName2 中,有值为 null 时,columnName1+columnName2=null, ifnull(columnName2,0) 把 columnName2 中 null 值转为 0
案例
# 查询身高为空的信息 select * from students where height is null; # 判非空is not null select * from students where height is not null;
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n‘ 或 ‘\r‘ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n‘ 或 ‘\r‘ 之前的位置。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 ‘\n‘ 在内的任何字符,请使用象 ‘[.\n]‘ 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]‘ 可以匹配 "plain" 中的 ‘a‘。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]‘ 可以匹配 "plain" 中的‘p‘。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,‘z|food‘ 能匹配 "z" 或 "food"。‘(z|f)ood‘ 则匹配 "zood" 或 "food"。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+‘ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}‘ 不能匹配 "Bob" 中的 ‘o‘,但是能匹配 "food" 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
示例
# 查找name字段中以‘st‘为开头的所有数据: mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘^st‘; # 查找name字段中以‘ok‘为结尾的所有数据: mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘ok$‘; # 查找name字段中包含‘mar‘字符串的所有数据: mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘mar‘; # 查找name字段中以元音字符开头或以‘ok‘字符串结尾的所有数据: mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘^[aeiou]|ok$‘;
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务,详细了解可以看一下这篇【常识与进阶】!
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
# 在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作。
因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION,或者执行命令 SETAUTOCOMMIT=0,
用来禁止使用当前会话的自动提交。
事务控制语句:
MYSQL 事务处理主要有两种方法:
# mysql> use RUNOOB; Database changed # mysql> CREATE TABLE runoob_transaction_test( id int(5)) engine=innodb; # 创建数据表 Query OK, 0 rows affected (0.04 sec) # mysql> select * from runoob_transaction_test; Empty set (0.01 sec) # mysql> begin; # 开始事务 Query OK, 0 rows affected (0.00 sec) # mysql> insert into runoob_transaction_test value(5); Query OK, 1 rows affected (0.01 sec) # mysql> insert into runoob_transaction_test value(6); Query OK, 1 rows affected (0.00 sec) # mysql> commit; # 提交事务 Query OK, 0 rows affected (0.01 sec) # mysql> select * from runoob_transaction_test; +------+ | id | +------+ | 5 | | 6 | +------+ rows in set (0.01 sec) # mysql> begin; # 开始事务 Query OK, 0 rows affected (0.00 sec) # mysql> insert into runoob_transaction_test values(7); Query OK, 1 rows affected (0.00 sec) # mysql> rollback; # 回滚 Query OK, 0 rows affected (0.00 sec) # mysql> select * from runoob_transaction_test; # 因为回滚所以数据没有插入 +------+ | id | +------+ | 5 | | 6 | +------+ rows in set (0.01 sec) # mysql> 事物测试
<?php $dbhost = ‘localhost:3306‘; // mysql服务器主机地址 $dbuser = ‘root‘; // mysql用户名 $dbpass = ‘123456‘; // mysql用户名密码 $conn = mysqli_connect($dbhost, $dbuser, $dbpass); if(! $conn ) { die(‘连接失败: ‘ . mysqli_error($conn)); } // 设置编码,防止中文乱码 mysqli_query($conn, "set names utf8"); mysqli_select_db( $conn, ‘RUNOOB‘ ); mysqli_query($conn, "SET AUTOCOMMIT=0"); // 设置为不自动提交,因为MYSQL默认立即执行 mysqli_begin_transaction($conn); // 开始事务定义 if(!mysqli_query($conn, "insert into runoob_transaction_test (id) values(8)")) { mysqli_query($conn, "ROLLBACK"); // 判断当执行失败时回滚 } if(!mysqli_query($conn, "insert into runoob_transaction_test (id) values(9)")) { mysqli_query($conn, "ROLLBACK"); // 判断执行失败时回滚 } mysqli_commit($conn); //执行事务 mysqli_close($conn); ?> PHP中使用事物示例
# root@host# mysql -u root -p password; Enter password:******* # mysql> use RUNOOB; Database changed # mysql> create table testalter_tbl -> ( -> i INT, -> c CHAR(1) -> ); Query OK, 0 rows affected (0.05 sec) # mysql> SHOW COLUMNS FROM testalter_tbl; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | i | int(11) | YES | | NULL | | | c | char(1) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ 2 rows in set (0.00 sec)
删除,添加或修改表字段
# 如下命令使用了 ALTER 命令及 DROP 子句来删除以上创建表的 i 字段: mysql> ALTER TABLE testalter_tbl DROP i; # 如果数据表中只剩余一个字段则无法使用DROP来删除字段。 # MySQL 中使用 ADD 子句来向数据表中添加列,如下实例在表 testalter_tbl # 中添加 i 字段,并定义数据类型: mysql> ALTER TABLE testalter_tbl ADD i INT;
# mysql> SHOW COLUMNS FROM testalter_tbl; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | c | char(1) | YES | | NULL | | | i | int(11) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ 2 rows in set (0.00 sec) # 如果你需要指定新增字段的位置,可以使用MySQL提供的关键字 FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)。
ALTER TABLE testalter_tbl DROP i; ALTER TABLE testalter_tbl ADD i INT FIRST; ALTER TABLE testalter_tbl DROP i; ALTER TABLE testalter_tbl ADD i INT AFTER c; # FIRST 和 AFTER 关键字可用于 ADD 与 MODIFY 子句,所以如果你想重置数据表字段的位置就需要先使用 DROP 删除字段然后使用 ADD 来添加字段并设置位置。
修改字段类型及名称
# 例如,把字段 c 的类型从 CHAR(1) 改为 CHAR(10),可以执行以下命令: mysql> ALTER TABLE testalter_tbl MODIFY c CHAR(10); # 使用 CHANGE 子句, 语法有很大的不同。 在 CHANGE 关键字之后,紧跟着的是你要修改的字段名,然后指定新字段名及类型。尝试如下实例: mysql> ALTER TABLE testalter_tbl CHANGE i j BIGINT; mysql> ALTER TABLE testalter_tbl CHANGE j j INT;
ALTER TABLE 对 Null 值和默认值的影响
# 以下实例,指定字段 j 为 NOT NULL 且默认值为100 。 mysql> ALTER TABLE testalter_tbl -> MODIFY j BIGINT NOT NULL DEFAULT 100; # 如果你不设置默认值,MySQL会自动设置该字段默认为 NULL
修改字段默认值
# mysql> ALTER TABLE testalter_tbl ALTER i SET DEFAULT 1000; # mysql> SHOW COLUMNS FROM testalter_tbl; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | c | char(1) | YES | | NULL | | | i | int(11) | YES | | 1000 | | +-------+---------+------+-----+---------+-------+ rows in set (0.00 sec)
# mysql> ALTER TABLE testalter_tbl ALTER i DROP DEFAULT; # mysql> SHOW COLUMNS FROM testalter_tbl; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | c | char(1) | YES | | NULL | | | i | int(11) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ rows in set (0.00 sec) Changing a Table Type:
# mysql> ALTER TABLE testalter_tbl ENGINE = MYISAM; # mysql> SHOW TABLE STATUS LIKE ‘testalter_tbl‘\G # *************************** 1. row **************** Name: testalter_tbl Type: MyISAM Row_format: Fixed Rows: 0 Avg_row_length: 0 Data_length: 0 Max_data_length: 25769803775 Index_length: 1024 Data_free: 0 Auto_increment: NULL Create_time: 2007-06-03 08:04:36 Update_time: 2007-06-03 08:04:36 Check_time: NULL Create_options: Comment: 1 row in set (0.00 sec)
修改表名
# mysql> ALTER TABLE testalter_tbl RENAME TO alter_tbl;
创建普通索引
# 这是最基本的索引,它没有任何限制。它有以下几种创建方式: CREATE INDEX indexName ON mytable(username(length)); # 如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
修改表结构(添加索引)
# ALTER table tableName ADD INDEX indexName(columnName) # 创建表的时候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) ); # 删除索引的语法 DROP INDEX [indexName] ON mytable;
创建唯一索引
# CREATE UNIQUE INDEX indexName ON mytable(username(length)) # 修改表结构 ALTER table mytable ADD UNIQUE [indexName] (username(length)) # 创建表的时候直接指定 CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE [indexName] (username(length)) );
使用ALTER 命令添加和删除索引
#以下实例为在表中添加索引。 mysql> ALTER TABLE testalter_tbl ADD INDEX (c); # 你还可以在 ALTER 命令中使用 DROP 子句来删除索引。尝试以下实例删除索引: mysql> ALTER TABLE testalter_tbl DROP INDEX c;
使用 ALTER 命令添加和删除主键
# mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL; # mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (i); # 你也可以使用 ALTER 命令删除主键: mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY; # 删除主键时只需指定PRIMARY KEY,但在删除索引时,你必须知道索引名。
显示索引信息
# 尝试以下实例: mysql> SHOW INDEX FROM table_name; \G ........
示例
mysql> CREATE TEMPORARY TABLE SalesSummary ( -> product_name VARCHAR(50) NOT NULL -> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00 -> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00 -> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0 ); Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO SalesSummary -> (product_name, total_sales, avg_unit_price, total_units_sold) -> VALUES -> (‘cucumber‘, 100.25, 90, 2); mysql> SELECT * FROM SalesSummary; +--------------+-------------+----------------+------------------+ | product_name | total_sales | avg_unit_price | total_units_sold | +--------------+-------------+----------------+------------------+ | cucumber | 100.25 | 90.00 | 2 | +--------------+-------------+----------------+------------------+ row in set (0.00 sec)
删除MySQL 临时表
mysql> CREATE TEMPORARY TABLE SalesSummary ( -> product_name VARCHAR(50) NOT NULL -> , total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00 -> , avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00 -> , total_units_sold INT UNSIGNED NOT NULL DEFAULT 0 ); Query OK, 0 rows affected (0.00 sec) mysql> INSERT INTO SalesSummary -> (product_name, total_sales, avg_unit_price, total_units_sold) -> VALUES -> (‘cucumber‘, 100.25, 90, 2); mysql> SELECT * FROM SalesSummary; +--------------+-------------+----------------+------------------+ | product_name | total_sales | avg_unit_price | total_units_sold | +--------------+-------------+----------------+------------------+ | cucumber | 100.25 | 90.00 | 2 | +--------------+-------------+----------------+------------------+ row in set (0.00 sec) mysql> DROP TABLE SalesSummary; mysql> SELECT * FROM SalesSummary; ERROR 1146: Table ‘RUNOOB.SalesSummary‘ doesn‘t exist
如果我们需要完全的复制MySQL的数据表,包括表的结构,索引,默认值等。 如果仅仅使用CREATE TABLE ... SELECT 命令,是无法实现的。
实例
# mysql> SHOW CREATE TABLE runoob_tbl \G; *************************** 1. row *************************** Table: runoob_tbl Create Table: CREATE TABLE `runoob_tbl` ( `runoob_id` int(11) NOT NULL auto_increment, `runoob_title` varchar(100) NOT NULL default ‘‘, `runoob_author` varchar(40) NOT NULL default ‘‘, `submission_date` date default NULL, PRIMARY KEY (`runoob_id`), UNIQUE KEY `AUTHOR_INDEX` (`runoob_author`) ) ENGINE=InnoDB row in set (0.00 sec) ERROR: No query specified
# mysql> CREATE TABLE `clone_tbl` ( -> `runoob_id` int(11) NOT NULL auto_increment, -> `runoob_title` varchar(100) NOT NULL default ‘‘, -> `runoob_author` varchar(40) NOT NULL default ‘‘, -> `submission_date` date default NULL, -> PRIMARY KEY (`runoob_id`), -> UNIQUE KEY `AUTHOR_INDEX` (`runoob_author`) -> ) ENGINE=InnoDB; Query OK, 0 rows affected (1.80 sec)
# 执行完第二步骤后,你将在数据库中创建新的克隆表 clone_tbl。 如果你想拷贝数据表的数据你可以使用 INSERT INTO... SELECT 语句来实现。 mysql> INSERT INTO clone_tbl (runoob_id, -> runoob_title, -> runoob_author, -> submission_date) -> SELECT runoob_id,runoob_title, -> runoob_author,submission_date -> FROM runoob_tbl; Query OK, 3 rows affected (0.07 sec) Records: 3 Duplicates: 0 Warnings: 0 # 执行以上步骤后,你将完整的复制表,包括表结构及表数据。
使用 AUTO_INCREMENT
实例
mysql> CREATE TABLE insect -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, # type of insect -> date DATE NOT NULL, # date collected -> origin VARCHAR(30) NOT NULL # where collected ); Query OK, 0 rows affected (0.02 sec) mysql> INSERT INTO insect (id,name,date,origin) VALUES -> (NULL,‘housefly‘,‘2001-09-10‘,‘kitchen‘), -> (NULL,‘millipede‘,‘2001-09-10‘,‘driveway‘), -> (NULL,‘grasshopper‘,‘2001-09-10‘,‘front yard‘); Query OK, 3 rows affected (0.02 sec) Records: 3 Duplicates: 0 Warnings: 0 mysql> SELECT * FROM insect ORDER BY id; +----+-------------+------------+------------+ | id | name | date | origin | +----+-------------+------------+------------+ | 1 | housefly | 2001-09-10 | kitchen | | 2 | millipede | 2001-09-10 | driveway | | 3 | grasshopper | 2001-09-10 | front yard | +----+-------------+------------+------------+ 3 rows in set (0.00 sec)
获取AUTO_INCREMENT值
# 使用 mysql_insertid 属性来获取 AUTO_INCREMENT 的值。 实例如下: $dbh->do ("INSERT INTO insect (name,date,origin) VALUES(‘moth‘,‘2001-09-14‘,‘windowsill‘)"); my $seq = $dbh->{mysql_insertid};
PHP 通过 mysql_insert_id ()函数来获取执行的插入SQL语句中 AUTO_INCREMENT列的值。 mysql_query ("INSERT INTO insect (name,date,origin) VALUES(‘moth‘,‘2001-09-14‘,‘windowsill‘)", $conn_id); $seq = mysql_insert_id ($conn_id);
重置序列
# mysql> ALTER TABLE insect DROP id; # mysql> ALTER TABLE insect -> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST, -> ADD PRIMARY KEY (id);
# mysql> CREATE TABLE insect -> ( -> id INT UNSIGNED NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (id), -> name VARCHAR(30) NOT NULL, -> date DATE NOT NULL, -> origin VARCHAR(30) NOT NULL )engine=innodb auto_increment=100 charset=utf8; # 或者你也可以在表创建成功后,通过以下语句来实现: # mysql> ALTER TABLE t AUTO_INCREMENT = 100;
防止表中出现重复数据
CREATE TABLE person_tbl ( first_name CHAR(20), last_name CHAR(20), sex CHAR(10) ); # 如果你想设置表中字段 first_name,last_name 数据不能重复,你可以设置双主键模式来设置数据的唯一性, 如果你设置了双主键, 那么那个键的默认值不能为 NULL,可设置为 NOT NULL。如下所示: CREATE TABLE person_tbl ( first_name CHAR(20) NOT NULL, last_name CHAR(20) NOT NULL, sex CHAR(10), PRIMARY KEY (last_name, first_name) );
# mysql> INSERT IGNORE INTO person_tbl (last_name, first_name) -> VALUES( ‘Jay‘, ‘Thomas‘); Query OK, 1 row affected (0.00 sec) # mysql> INSERT IGNORE INTO person_tbl (last_name, first_name) -> VALUES( ‘Jay‘, ‘Thomas‘); Query OK, 0 rows affected (0.00 sec)
CREATE TABLE person_tbl ( first_name CHAR(20) NOT NULL, last_name CHAR(20) NOT NULL, sex CHAR(10), UNIQUE (last_name, first_name) );
统计重复数据
# mysql> SELECT COUNT(*) as repetitions, last_name, first_name -> FROM person_tbl -> GROUP BY last_name, first_name -> HAVING repetitions > 1;
# 如果你需要读取不重复的数据可以在 SELECT 语句中使用 DISTINCT 关键字来过滤重复数据。 # mysql> SELECT DISTINCT last_name, first_name -> FROM person_tbl; # 你也可以使用 GROUP BY 来读取数据表中不重复的数据: # mysql> SELECT last_name, first_name -> FROM person_tbl -> GROUP BY (last_name, first_name);
# 如果你想删除数据表中的重复数据,你可以使用以下的SQL语句: # mysql> CREATE TABLE tmp SELECTlast_name, first_name, sex FROM person_tblGROUP BY (last_name, first_name, sex); # mysql> DROP TABLE person_tbl; # mysql> ALTER TABLE tmp RENAME TO person_tbl; # 当然你也可以在数据表中添加 INDEX(索引) 和 PRIMAY KEY(主键)这种简单的方法来删除表中的重复记录。方法如下: # mysql> ALTER IGNORE TABLE person_tbl -> ADD PRIMARY KEY (last_name, first_name);
# 以下实例中我们将数据表 runoob_tbl 数据导出到 /tmp/runoob.txt 文件中: mysql> SELECT * FROM runoob_tbl -> INTO OUTFILE ‘/tmp/runoob.txt‘; # 你可以通过命令选项来设置数据输出的指定格式,以下实例为导出 CSV 格式: mysql> SELECT * FROM passwd INTO OUTFILE ‘/tmp/runoob.txt‘ -> FIELDS TERMINATED BY ‘,‘ ENCLOSED BY ‘"‘ -> LINES TERMINATED BY ‘\r\n‘; # 在下面的例子中,生成一个文件,各值用逗号隔开。这种格式可以被许多程序使用。 SELECT a,b,a+b INTO OUTFILE ‘/tmp/result.text‘ FIELDS TERMINATED BY ‘,‘ OPTIONALLY ENCLOSED BY ‘"‘ LINES TERMINATED BY ‘\n‘ FROM test_table;
SELECT ... INTO OUTFILE 语句有以下属性:
导出表作为原始数据
#以下实例将数据表 runoob_tbl 导出到 /tmp 目录中: $ mysqldump -u root -p --no-create-info --tab=/tmp RUNOOB runoob_tbl password ******
导出 SQL 格式的数据
$ mysqldump -u root -p RUNOOB runoob_tbl > dump.txt password ****** 以上命令创建的文件内容如下: -- MySQL dump 8.23 -- -- Host: localhost Database: RUNOOB --------------------------------------------------------- -- Server version 3.23.58 -- -- Table structure for table `runoob_tbl` -- CREATE TABLE runoob_tbl ( runoob_id int(11) NOT NULL auto_increment, runoob_title varchar(100) NOT NULL default ‘‘, runoob_author varchar(40) NOT NULL default ‘‘, submission_date date default NULL, PRIMARY KEY (runoob_id), UNIQUE KEY AUTHOR_INDEX (runoob_author) ) TYPE=MyISAM; -- -- Dumping data for table `runoob_tbl` -- INSERT INTO runoob_tbl VALUES (1,‘Learn PHP‘,‘John Poul‘,‘2007-05-24‘); INSERT INTO runoob_tbl VALUES (2,‘Learn MySQL‘,‘Abdul S‘,‘2007-05-24‘); INSERT INTO runoob_tbl VALUES (3,‘JAVA Tutorial‘,‘Sanjay‘,‘2007-05-06‘); # 如果你需要导出整个数据库的数据,可以使用以下命令: $ mysqldump -u root -p RUNOOB > database_dump.txt password ****** # 如果需要备份所有数据库,可以使用以下命令: $ mysqldump -u root -p --all-databases > database_dump.txt password ****** --all-databases 选项在 MySQL 3.23.12 及以后版本加入。 # 该方法可用于实现数据库的备份策略。
# 如果你需要将数据拷贝至其他的 MySQL 服务器上, 你可以mysqldump 命令中指定数据库名及数据表。 # 在源主机上执行以下命令,将数据备份至 dump.txt 文件中: $ mysqldump -u root -p database_name table_name > dump.txt password ***** #如果完整备份数据库,则无需使用特定的表名称。 # 如果你需要将备份的数据库导入到MySQL服务器中,可以使用以下命令,使用以下命令你需要确认数据库已经创建: $ mysql -u root -p database_name < dump.txt password ***** # 你也可以使用以下命令将导出的数据直接导入到远程的服务器上,但请确保两台服务器是相通的,是可以相互访问的: $ mysqldump -u root -p database_name | mysql -h other-host.com database_name # 以上命令中使用了管道来将导出的数据导入到指定的远程主机上。
MySQL 导入数据
# 使用 mysql 命令导入语法格式为: mysql -u用户名 -p密码 < 要导入的数据库数据(runoob.sql) # 实例: # mysql -uroot -p123456 < runoob.sql # 以上命令将将备份的整个数据库 runoob.sql 导入。
# source 命令导入数据库需要先登录到数库终端: mysql> create database abc; # 创建数据库 mysql> use abc; # 使用已创建的数据库 mysql> set names utf8; # 设置编码 mysql> source /home/abc/abc.sql # 导入备份数据库
# mysql> LOAD DATA LOCAL INFILE ‘dump.txt‘ INTO TABLE mytbl;
# mysql> LOAD DATA LOCAL INFILE ‘dump.txt‘ INTO TABLE mytbl -> FIELDS TERMINATED BY ‘:‘ -> LINES TERMINATED BY ‘\r\n‘;
# mysql> LOAD DATA LOCAL INFILE ‘dump.txt‘ -> INTO TABLE mytbl (b, c, a);
# 从文件 dump.txt 中将数据导入到 mytbl 数据表中, 可以使用以下命令: $ mysqlimport -u root -p --local mytbl dump.txt password ***** # mysqlimport 命令可以指定选项来设置指定格式,命令语句格式如下: $ mysqlimport -u root -p --local --fields-terminated-by=":" --lines-terminated-by="\r\n" mytbl dump.txt password ***** # mysqlimport 语句中使用 --columns 选项来设置列的顺序: $ mysqlimport -u root -p --local --columns=b,c,a mytbl dump.txt password *****
| 选项 | 功能 |
|---|---|
| -d or --delete | 新数据导入数据表中之前删除数据数据表中的所有信息 |
| -f or --force | 不管是否遇到错误,mysqlimport将强制继续插入数据 |
| -i or --ignore | mysqlimport跳过或者忽略那些有相同唯一 关键字的行, 导入文件中的数据将被忽略。 |
| -l or -lock-tables | 数据被插入之前锁住表,这样就防止了, 你在更新数据库时,用户的查询和更新受到影响。 |
| -r or -replace | 这个选项与-i选项的作用相反;此选项将替代 表中有相同唯一关键字的记录。 |
| --fields-enclosed- by= char | 指定文本文件中数据的记录时以什么括起的, 很多情况下 数据以双引号括起。 默认的情况下数据是没有被字符括起的。 |
| --fields-terminated- by=char | 指定各个数据的值之间的分隔符,在句号分隔的文件中, 分隔符是句号。您可以用此选项指定数据之间的分隔符。 默认的分隔符是跳格符(Tab) |
| --lines-terminated- by=str | 此选项指定文本文件中行与行之间数据的分隔字符串 或者字符。 默认的情况下mysqlimport以newline为行分隔符。 您可以选择用一个字符串来替代一个单个的字符: 一个新行或者一个回车。 |
# 首先linux 下查看mysql相关目录 [root@op-workorder bin]# whereis mysql mysql: /usr/bin/mysql /usr/lib64/mysql /usr/include/mysql # 导出数据库用mysqldump命令 cd /home/work/mysql/bin # 先cd到mysql的运行路径下,再执行一下命令 # 1. 导出数据和表结构 ./mysqldump -uroot -p bsp > bsp.sql mysqldump -u用户名 -p密码 数据库名 > 数据库名.sql # 2. 只导出表结构 mysqldump -u用户名 -p密码 -d 数据库名 > 数据库名.sql mysqldump -uroot -p -d dbname > dbname .sql # 3. 导入数据库 # 1、首先建空数据库 mysql>create database bsp charset utf8; # 2、导入数据库(方法一) # 选择数据库 mysql>use bsp; # 导入数据(注意sql文件的路径) mysql>source /home/work/project/bsp/bsp.sql # 3、导入数据库(方法二) mysql -u用户名 -p密码 数据库名 < 数据库名.sql # 4、执行导出数据库报错问题解决 # 报错:mysqldump: Couldn‘t execute ‘SHOW VARIABLES LIKE ‘gtid\_mode‘‘: Table
‘performance_schema.session_variables‘ doesn‘t exist (1146) 1)mysql_upgrade -u root -p --force #更新 2)service mysql restart #restart mysql service 3)mysqldump -u root -p test > test.sql #重新备份数据
MySQL 字符串函数
| 函数 | 描述 | 实例 |
|---|---|---|
| ASCII(s) | 返回字符串 s 的第一个字符的 ASCII 码。 |
返回 CustomerName 字段第一个字母的 ASCII 码: SELECT ASCII(CustomerName) AS NumCodeOfFirstChar
FROM Customers;
|
| CHAR_LENGTH(s) | 返回字符串 s 的字符数 |
返回字符串 RUNOOB 的字符数 SELECT CHAR_LENGTH("RUNOOB") AS LengthOfString;
|
| CHARACTER_LENGTH(s) | 返回字符串 s 的字符数 |
返回字符串 RUNOOB 的字符数 SELECT CHARACTER_LENGTH("RUNOOB") AS LengthOfString;
|
| CONCAT(s1,s2...sn) | 字符串 s1,s2 等多个字符串合并为一个字符串 |
合并多个字符串 SELECT CONCAT("SQL ", "Runoob ", "Gooogle ", "Facebook") AS ConcatenatedString;
|
| CONCAT_WS(x, s1,s2...sn) | 同 CONCAT(s1,s2,...) 函数,但是每个字符串之间要加上 x,x 可以是分隔符 |
合并多个字符串,并添加分隔符: SELECT CONCAT_WS("-", "SQL", "Tutorial", "is", "fun!")AS ConcatenatedString;
|
| FIELD(s,s1,s2...) | 返回第一个字符串 s 在字符串列表(s1,s2...)中的位置 |
返回字符串 c 在列表值中的位置: SELECT FIELD("c", "a", "b", "c", "d", "e");
|
| FIND_IN_SET(s1,s2) | 返回在字符串s2中与s1匹配的字符串的位置 |
返回字符串 c 在指定字符串中的位置: SELECT FIND_IN_SET("c", "a,b,c,d,e");
|
| FORMAT(x,n) | 函数可以将数字 x 进行格式化 "#,###.##", 将 x 保留到小数点后 n 位,最后一位四舍五入。 |
格式化数字 "#,###.##" 形式: SELECT FORMAT(250500.5634, 2); -- 输出 250,500.56
|
| INSERT(s1,x,len,s2) | 字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串 |
从字符串第一个位置开始的 6 个字符替换为 runoob: SELECT INSERT("google.com", 1, 6, "runnob"); -- 输出:runoob.com
|
| LOCATE(s1,s) | 从字符串 s 中获取 s1 的开始位置 |
获取 b 在字符串 abc 中的位置: SELECT LOCATE(‘st‘,‘myteststring‘); -- 5
返回字符串 abc 中 b 的位置: SELECT LOCATE(‘b‘, ‘abc‘) -- 2
|
| LCASE(s) | 将字符串 s 的所有字母变成小写字母 |
字符串 RUNOOB 转换为小写: SELECT LCASE(‘RUNOOB‘) -- runoob
|
| LEFT(s,n) | 返回字符串 s 的前 n 个字符 |
返回字符串 runoob 中的前两个字符: SELECT LEFT(‘runoob‘,2) -- ru
|
| LOWER(s) | 将字符串 s 的所有字母变成小写字母 |
字符串 RUNOOB 转换为小写: SELECT LOWER(‘RUNOOB‘) -- runoob
|
| LPAD(s1,len,s2) | 在字符串 s1 的开始处填充字符串 s2,使字符串长度达到 len |
将字符串 xx 填充到 abc 字符串的开始处: SELECT LPAD(‘abc‘,5,‘xx‘) -- xxabc
|
| LTRIM(s) | 去掉字符串 s 开始处的空格 |
去掉字符串 RUNOOB开始处的空格: SELECT LTRIM(" RUNOOB") AS LeftTrimmedString;-- RUNOOB
|
| MID(s,n,len) | 从字符串 s 的 n 位置截取长度为 len 的子字符串,同 SUBSTRING(s,n,len) |
从字符串 RUNOOB 中的第 2 个位置截取 3个 字符: SELECT MID("RUNOOB", 2, 3) AS ExtractString; -- UNO
|
| POSITION(s1 IN s) | 从字符串 s 中获取 s1 的开始位置 |
返回字符串 abc 中 b 的位置: SELECT POSITION(‘b‘ in ‘abc‘) -- 2
|
| REPEAT(s,n) | 将字符串 s 重复 n 次 |
将字符串 runoob 重复三次: SELECT REPEAT(‘runoob‘,3) -- runoobrunoobrunoob
|
| REPLACE(s,s1,s2) | 将字符串 s2 替代字符串 s 中的字符串 s1 |
将字符串 abc 中的字符 a 替换为字符 x: SELECT REPLACE(‘abc‘,‘a‘,‘x‘) --xbc
|
| REVERSE(s) | 将字符串s的顺序反过来 |
将字符串 abc 的顺序反过来: SELECT REVERSE(‘abc‘) -- cba
|
| RIGHT(s,n) | 返回字符串 s 的后 n 个字符 |
返回字符串 runoob 的后两个字符: SELECT RIGHT(‘runoob‘,2) -- ob
|
| RPAD(s1,len,s2) | 在字符串 s1 的结尾处添加字符串 s2,使字符串的长度达到 len |
将字符串 xx 填充到 abc 字符串的结尾处: SELECT RPAD(‘abc‘,5,‘xx‘) -- abcxx
|
| RTRIM(s) | 去掉字符串 s 结尾处的空格 |
去掉字符串 RUNOOB 的末尾空格: SELECT RTRIM("RUNOOB ") AS RightTrimmedString; -- RUNOOB
|
| SPACE(n) | 返回 n 个空格 |
返回 10 个空格: SELECT SPACE(10);
|
| STRCMP(s1,s2) | 比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1 |
比较字符串: SELECT STRCMP("runoob", "runoob"); -- 0
|
| SUBSTR(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 |
从字符串 RUNOOB 中的第 2 个位置截取 3个 字符: SELECT SUBSTR("RUNOOB", 2, 3) AS ExtractString; -- UNO
|
| SUBSTRING(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 |
从字符串 RUNOOB 中的第 2 个位置截取 3个 字符: SELECT SUBSTRING("RUNOOB", 2, 3) AS ExtractString; -- UNO
|
| SUBSTRING_INDEX(s, delimiter, number) | 返回从字符串 s 的第 number 个出现的分隔符 delimiter 之后的子串。 如果 number 是正数,返回第 number 个字符左边的字符串。 如果 number 是负数,返回第(number 的绝对值(从右边数))个字符右边的字符串。 |
SELECT SUBSTRING_INDEX(‘a*b‘,‘*‘,1) -- a
SELECT SUBSTRING_INDEX(‘a*b‘,‘*‘,-1) -- b
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(‘a*b*c*d*e‘,‘*‘,3),‘*‘,-1) -- c
|
| TRIM(s) | 去掉字符串 s 开始和结尾处的空格 |
去掉字符串 RUNOOB 的首尾空格: SELECT TRIM(‘ RUNOOB ‘) AS TrimmedString;
|
| UCASE(s) | 将字符串转换为大写 |
将字符串 runoob 转换为大写: SELECT UCASE("runoob"); -- RUNOOB
|
| UPPER(s) | 将字符串转换为大写 |
将字符串 runoob 转换为大写: SELECT UPPER("runoob"); -- RUNOOB
|
| 函数名 | 描述 | 实例 |
|---|---|---|
| ABS(x) | 返回 x 的绝对值 |
返回 -1 的绝对值: SELECT ABS(-1) -- 返回1
|
| ACOS(x) | 求 x 的反余弦值(参数是弧度) |
SELECT ACOS(0.25);
|
| ASIN(x) | 求反正弦值(参数是弧度) |
SELECT ASIN(0.25);
|
| ATAN(x) | 求反正切值(参数是弧度) |
SELECT ATAN(2.5);
|
| ATAN2(n, m) | 求反正切值(参数是弧度) |
SELECT ATAN2(-0.8, 2);
|
| AVG(expression) | 返回一个表达式的平均值,expression 是一个字段 |
返回 Products 表中Price 字段的平均值: SELECT AVG(Price) AS AveragePrice FROM Products;
|
| CEIL(x) | 返回大于或等于 x 的最小整数 |
SELECT CEIL(1.5) -- 返回2
|
| CEILING(x) | 返回大于或等于 x 的最小整数 |
SELECT CEIL(1.5) -- 返回2
|
| COS(x) | 求余弦值(参数是弧度) |
SELECT COS(2);
|
| COT(x) | 求余切值(参数是弧度) |
SELECT COT(6);
|
| COUNT(expression) | 返回查询的记录总数,expression 参数是一个字段或者 * 号 |
返回 Products 表中 products 字段总共有多少条记录: SELECT COUNT(ProductID) AS NumberOfProducts FROM Products;
|
| DEGREES(x) | 将弧度转换为角度 |
SELECT DEGREES(3.1415926535898) -- 180
|
| n DIV m | 整除,n 为被除数,m 为除数 |
计算 10 除于 5: SELECT 10 DIV 5; -- 2
|
| EXP(x) | 返回 e 的 x 次方 |
计算 e 的三次方: SELECT EXP(3) -- 20.085536923188
|
| FLOOR(x) | 返回小于或等于 x 的最大整数 |
小于或等于 1.5 的整数: SELECT FLOOR(1.5) -- 返回1
|
| GREATEST(expr1, expr2, expr3, ...) | 返回列表中的最大值 |
返回以下数字列表中的最大值: SELECT GREATEST(3, 12, 34, 8, 25); -- 34
返回以下字符串列表中的最大值: SELECT GREATEST("Google", "Runoob", "Apple"); -- Runoob
|
| LEAST(expr1, expr2, expr3, ...) | 返回列表中的最小值 |
返回以下数字列表中的最小值: SELECT LEAST(3, 12, 34, 8, 25); -- 3
返回以下字符串列表中的最小值: SELECT LEAST("Google", "Runoob", "Apple"); -- Apple
|
| LN | 返回数字的自然对数 |
返回 2 的自然对数: SELECT LN(2); -- 0.6931471805599453
|
| LOG(x) | 返回自然对数(以 e 为底的对数) |
SELECT LOG(20.085536923188) -- 3
|
| LOG10(x) | 返回以 10 为底的对数 |
SELECT LOG10(100) -- 2
|
| LOG2(x) | 返回以 2 为底的对数 |
返回以 2 为底 6 的对数: SELECT LOG2(6); -- 2.584962500721156
|
| MAX(expression) | 返回字段 expression 中的最大值 |
返回数据表 Products 中字段 Price 的最大值: SELECT MAX(Price) AS LargestPrice FROM Products;
|
| MIN(expression) | 返回字段 expression 中的最小值 |
返回数据表 Products 中字段 Price 的最小值: SELECT MIN(Price) AS LargestPrice FROM Products;
|
| MOD(x,y) | 返回 x 除以 y 以后的余数 |
5 除于 2 的余数: SELECT MOD(5,2) -- 1
|
| PI() | 返回圆周率(3.141593) |
SELECT PI() --3.141593
|
| POW(x,y) | 返回 x 的 y 次方 |
2 的 3 次方: SELECT POW(2,3) -- 8
|
| POWER(x,y) | 返回 x 的 y 次方 |
2 的 3 次方: SELECT POWER(2,3) -- 8
|
| RADIANS(x) | 将角度转换为弧度 |
180 度转换为弧度: SELECT RADIANS(180) -- 3.1415926535898
|
| RAND() | 返回 0 到 1 的随机数 |
SELECT RAND() --0.93099315644334
|
| ROUND(x) | 返回离 x 最近的整数 |
SELECT ROUND(1.23456) --1
|
| SIGN(x) | 返回 x 的符号,x 是负数、0、正数分别返回 -1、0 和 1 |
SELECT SIGN(-10) -- (-1)
|
| SIN(x) | 求正弦值(参数是弧度) |
SELECT SIN(RADIANS(30)) -- 0.5
|
| SQRT(x) | 返回x的平方根 |
25 的平方根: SELECT SQRT(25) -- 5
|
| SUM(expression) | 返回指定字段的总和 |
计算 OrderDetails 表中字段 Quantity 的总和: SELECT SUM(Quantity) AS TotalItemsOrdered FROM OrderDetails;
|
| TAN(x) | 求正切值(参数是弧度) |
SELECT TAN(1.75); -- -5.52037992250933
|
| TRUNCATE(x,y) | 返回数值 x 保留到小数点后 y 位的值(与 ROUND 最大的区别是不会进行四舍五入) |
SELECT TRUNCATE(1.23456,3) -- 1.234
|
| 函数名 | 描述 | 实例 |
|---|---|---|
| ADDDATE(d,n) | 计算起始日期 d 加上 n 天的日期 |
SELECT ADDDATE("2017-06-15", INTERVAL 10 DAY);
->2017-06-25
|
| ADDTIME(t,n) | 时间 t 加上 n 秒的时间 |
SELECT ADDTIME(‘2011-11-11 11:11:11‘, 5)
->2011-11-11 11:11:16 (秒)
|
| CURDATE() | 返回当前日期 |
SELECT CURDATE();
-> 2018-09-19
|
| CURRENT_DATE() | 返回当前日期 |
SELECT CURRENT_DATE();
-> 2018-09-19
|
| CURRENT_TIME | 返回当前时间 |
SELECT CURRENT_TIME();
-> 19:59:02
|
| CURRENT_TIMESTAMP() | 返回当前日期和时间 |
SELECT CURRENT_TIMESTAMP()
-> 2018-09-19 20:57:43
|
| CURTIME() | 返回当前时间 |
SELECT CURTIME();
-> 19:59:02
|
| DATE() | 从日期或日期时间表达式中提取日期值 |
SELECT DATE("2017-06-15");
-> 2017-06-15
|
| DATEDIFF(d1,d2) | 计算日期 d1->d2 之间相隔的天数 |
SELECT DATEDIFF(‘2001-01-01‘,‘2001-02-02‘)
-> -32
|
| DATE_ADD(d,INTERVAL expr type) | 计算起始日期 d 加上一个时间段后的日期 |
SELECT ADDDATE(‘2011-11-11 11:11:11‘,1)
-> 2011-11-12 11:11:11 (默认是天)
SELECT ADDDATE(‘2011-11-11 11:11:11‘, INTERVAL 5 MINUTE)
-> 2011-11-11 11:16:11 (TYPE的取值与上面那个列出来的函数类似)
|
| DATE_FORMAT(d,f) | 按表达式 f的要求显示日期 d |
SELECT DATE_FORMAT(‘2011-11-11 11:11:11‘,‘%Y-%m-%d %r‘)
-> 2011-11-11 11:11:11 AM
|
| DATE_SUB(date,INTERVAL expr type) | 函数从日期减去指定的时间间隔。 |
Orders 表中 OrderDate 字段减去 2 天: SELECT OrderId,DATE_SUB(OrderDate,INTERVAL 2 DAY) AS OrderPayDate
FROM Orders
|
| DAY(d) | 返回日期值 d 的日期部分 |
SELECT DAY("2017-06-15");
-> 15
|
| DAYNAME(d) | 返回日期 d 是星期几,如 Monday,Tuesday |
SELECT DAYNAME(‘2011-11-11 11:11:11‘)
->Friday
|
| DAYOFMONTH(d) | 计算日期 d 是本月的第几天 |
SELECT DAYOFMONTH(‘2011-11-11 11:11:11‘)
->11
|
| DAYOFWEEK(d) | 日期 d 今天是星期几,1 星期日,2 星期一,以此类推 |
SELECT DAYOFWEEK(‘2011-11-11 11:11:11‘)
->6
|
| DAYOFYEAR(d) | 计算日期 d 是本年的第几天 |
SELECT DAYOFYEAR(‘2011-11-11 11:11:11‘)
->315
|
| EXTRACT(type FROM d) | 从日期 d 中获取指定的值,type 指定返回的值。 type可取值为:
|
SELECT EXTRACT(MINUTE FROM ‘2011-11-11 11:11:11‘)
-> 11
|
| FROM_DAYS(n) | 计算从 0000 年 1 月 1 日开始 n 天后的日期 |
SELECT FROM_DAYS(1111)
-> 0003-01-16
|
| HOUR(t) | 返回 t 中的小时值 |
SELECT HOUR(‘1:2:3‘)
-> 1
|
| LAST_DAY(d) | 返回给给定日期的那一月份的最后一天 |
SELECT LAST_DAY("2017-06-20");
-> 2017-06-30
|
| LOCALTIME() | 返回当前日期和时间 |
SELECT LOCALTIME()
-> 2018-09-19 20:57:43
|
| LOCALTIMESTAMP() | 返回当前日期和时间 |
SELECT LOCALTIMESTAMP()
-> 2018-09-19 20:57:43
|
| MAKEDATE(year, day-of-year) | 基于给定参数年份 year 和所在年中的天数序号 day-of-year 返回一个日期 |
SELECT MAKEDATE(2017, 3);
-> 2017-01-03
|
| MAKETIME(hour, minute, second) | 组合时间,参数分别为小时、分钟、秒 |
SELECT MAKETIME(11, 35, 4);
-> 11:35:04
|
| MICROSECOND(date) | 返回日期参数所对应的微秒数 |
SELECT MICROSECOND("2017-06-20 09:34:00.000023");
-> 23
|
| MINUTE(t) | 返回 t 中的分钟值 |
SELECT MINUTE(‘1:2:3‘)
-> 2
|
| MONTHNAME(d) | 返回日期当中的月份名称,如 November |
SELECT MONTHNAME(‘2011-11-11 11:11:11‘)
-> November
|
| MONTH(d) | 返回日期d中的月份值,1 到 12 |
SELECT MONTH(‘2011-11-11 11:11:11‘)
->11
|
| NOW() | 返回当前日期和时间 |
SELECT NOW()
-> 2018-09-19 20:57:43
|
| PERIOD_ADD(period, number) | 为 年-月 组合日期添加一个时段 |
SELECT PERIOD_ADD(201703, 5);
-> 201708
|
| PERIOD_DIFF(period1, period2) | 返回两个时段之间的月份差值 |
SELECT PERIOD_DIFF(201710, 201703);
-> 7
|
| QUARTER(d) | 返回日期d是第几季节,返回 1 到 4 |
SELECT QUARTER(‘2011-11-11 11:11:11‘)
-> 4
|
| SECOND(t) | 返回 t 中的秒钟值 |
SELECT SECOND(‘1:2:3‘)
-> 3
|
| SEC_TO_TIME(s) | 将以秒为单位的时间 s 转换为时分秒的格式 |
SELECT SEC_TO_TIME(4320)
-> 01:12:00
|
| STR_TO_DATE(string, format_mask) | 将字符串转变为日期 |
SELECT STR_TO_DATE("August 10 2017", "%M %d %Y");
-> 2017-08-10
|
| SUBDATE(d,n) | 日期 d 减去 n 天后的日期 |
SELECT SUBDATE(‘2011-11-11 11:11:11‘, 1)
->2011-11-10 11:11:11 (默认是天)
|
| SUBTIME(t,n) | 时间 t 减去 n 秒的时间 |
SELECT SUBTIME(‘2011-11-11 11:11:11‘, 5)
->2011-11-11 11:11:06 (秒)
|
| SYSDATE() | 返回当前日期和时间 |
SELECT SYSDATE()
-> 2018-09-19 20:57:43
|
| TIME(expression) | 提取传入表达式的时间部分 |
SELECT TIME("19:30:10");
-> 19:30:10
|
| TIME_FORMAT(t,f) | 按表达式 f 的要求显示时间 t |
SELECT TIME_FORMAT(‘11:11:11‘,‘%r‘)
11:11:11 AM
|
| TIME_TO_SEC(t) | 将时间 t 转换为秒 |
SELECT TIME_TO_SEC(‘1:12:00‘)
-> 4320
|
| TIMEDIFF(time1, time2) | 计算时间差值 |
SELECT TIMEDIFF("13:10:11", "13:10:10");
-> 00:00:01
|
| TIMESTAMP(expression, interval) | 单个参数时,函数返回日期或日期时间表达式;有2个参数时,将参数加和 |
SELECT TIMESTAMP("2017-07-23", "13:10:11");
-> 2017-07-23 13:10:11
|
| TO_DAYS(d) | 计算日期 d 距离 0000 年 1 月 1 日的天数 |
SELECT TO_DAYS(‘0001-01-01 01:01:01‘)
-> 366
|
| WEEK(d) | 计算日期 d 是本年的第几个星期,范围是 0 到 53 |
SELECT WEEK(‘2011-11-11 11:11:11‘)
-> 45
|
| WEEKDAY(d) | 日期 d 是星期几,0 表示星期一,1 表示星期二 |
SELECT WEEKDAY("2017-06-15");
-> 3
|
| WEEKOFYEAR(d) | 计算日期 d 是本年的第几个星期,范围是 0 到 53 |
SELECT WEEKOFYEAR(‘2011-11-11 11:11:11‘)
-> 45
|
| YEAR(d) | 返回年份 |
SELECT YEAR("2017-06-15");
-> 2017
|
| YEARWEEK(date, mode) | 返回年份及第几周(0到53),mode 中 0 表示周天,1表示周一,以此类推 |
SELECT YEARWEEK("2017-06-15");
-> 201724
|
| 函数名 | 描述 | 实例 |
|---|---|---|
| BIN(x) | 返回 x 的二进制编码 |
15 的 2 进制编码: SELECT BIN(15); -- 1111
|
| BINARY(s) | 将字符串 s 转换为二进制字符串 |
SELECT BINARY "RUNOOB";
-> RUNOOB
|
CASE expression
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
WHEN conditionN THEN resultN
ELSE result
END
|
CASE 表示函数开始,END 表示函数结束。如果 condition1 成立,则返回 result1, 如果 condition2 成立,则返回 result2,当全部不成立则返回 result,而当有一个成立之后,后面的就不执行了。 |
SELECT CASE
WHEN 1 > 0
THEN ‘1 > 0‘
WHEN 2 > 0
THEN ‘2 > 0‘
ELSE ‘3 > 0‘
END
->1 > 0
|
| CAST(x AS type) | 转换数据类型 |
字符串日期转换为日期: SELECT CAST("2017-08-29" AS DATE);
-> 2017-08-29
|
| COALESCE(expr1, expr2, ...., expr_n) | 返回参数中的第一个非空表达式(从左向右) |
SELECT COALESCE(NULL, NULL, NULL, ‘runoob.com‘, NULL, ‘google.com‘);
-> runoob.com
|
| CONNECTION_ID() | 返回服务器的连接数 |
SELECT CONNECTION_ID();
-> 4292835
|
| CONV(x,f1,f2) | 返回 f1 进制数变成 f2 进制数 |
SELECT CONV(15, 10, 2);
-> 1111
|
| CONVERT(s USING cs) | 函数将字符串 s 的字符集变成 cs |
SELECT CHARSET(‘ABC‘)
->utf-8
SELECT CHARSET(CONVERT(‘ABC‘ USING gbk))
->gbk
|
| CURRENT_USER() | 返回当前用户 |
SELECT CURRENT_USER();
-> guest@%
|
| DATABASE() | 返回当前数据库名 |
SELECT DATABASE();
-> runoob
|
| IF(expr,v1,v2) | 如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2。 |
SELECT IF(1 > 0,‘正确‘,‘错误‘)
->正确
|
| IFNULL(v1,v2) | 如果 v1 的值不为 NULL,则返回 v1,否则返回 v2。 |
SELECT IFNULL(null,‘Hello Word‘)
->Hello Word
|
| ISNULL(expression) | 判断表达式是否为 NULL |
SELECT ISNULL(NULL);
->1
|
| LAST_INSERT_ID() | 返回最近生成的 AUTO_INCREMENT 值 |
SELECT LAST_INSERT_ID();
->6
|
| NULLIF(expr1, expr2) | 比较两个字符串,如果字符串 expr1 与 expr2 相等 返回 NULL,否则返回 expr1 |
SELECT NULLIF(25, 25);
->
|
| SESSION_USER() | 返回当前用户 |
SELECT SESSION_USER();
-> guest@%
|
| SYSTEM_USER() | 返回当前用户 |
SELECT SYSTEM_USER();
-> guest@%
|
| USER() | 返回当前用户 |
SELECT USER();
-> guest@%
|
| VERSION() | 返回数据库的版本号 |
SELECT VERSION()
-> 5.6.34
|
算术运算符
# 运算符 # 作用 + # 加法 - # 减法 * # 乘法 / 或 DIV # 除法 % 或 MOD # 取余
# 1、加 mysql> select 1+2; +-----+ | 1+2 | +-----+ | 3 | +-----+ # 2、减 mysql> select 1-2; +-----+ | 1-2 | +-----+ | -1 | +-----+ # 3、乘 mysql> select 2*3; +-----+ | 2*3 | +-----+ | 6 | +-----+ # 4、除 mysql> select 2/3; +--------+ | 2/3 | +--------+ | 0.6667 | +--------+ # 5、商 mysql> select 10 DIV 4; +----------+ | 10 DIV 4 | +----------+ | 2 | +----------+ # 6、取余 mysql> select 10 MOD 4; +----------+ | 10 MOD 4 | +----------+ | 2 | +----------+
比较运算符
| 符号 | 描述 | 备注 |
|---|---|---|
| = | 等于 | |
| <>, != | 不等于 | |
| > | 大于 | |
| < | 小于 | |
| <= | 小于等于 | |
| >= | 大于等于 | |
| BETWEEN | 在两值之间 | >=min&&<=max |
| NOT BETWEEN | 不在两值之间 | |
| IN | 在集合中 | |
| NOT IN | 不在集合中 | |
| <=> | 严格比较两个NULL值是否相等 | 两个操作码均为NULL时,其所得值为1;而当一个操作码为NULL时,其所得值为0 |
| LIKE | 模糊匹配 | |
| REGEXP 或 RLIKE | 正则式匹配 | |
| IS NULL | 为空 | |
| IS NOT NULL | 不为空 |
# mysql> select 2=3; +-----+ | 2=3 | +-----+ | 0 | +-----+ # mysql> select NULL = NULL; +-------------+ | NULL = NULL | +-------------+ | NULL | +-------------+
# mysql> select 2<>3; +------+ | 2<>3 | +------+ | 1 | +------+
# 与 = 的区别在于当两个操作码均为 NULL 时,其所得值为 1 而不为 NULL,而当一个操作码为 NULL 时,其所得值为 0而不为 NULL。 # mysql> select 2<=>3; +-------+ | 2<=>3 | +-------+ | 0 | +-------+ # mysql> select null=null; +-----------+ | null=null | +-----------+ | NULL | +-----------+ # mysql> select null<=>null; +-------------+ | null<=>null | +-------------+ | 1 | +-------------+
# mysql> select 2<3; +-----+ | 2<3 | +-----+ | 1 | +-----+
# mysql> select 2<=3; +------+ | 2<=3 | +------+ | 1 | +------+
# mysql> select 2>3; +-----+ | 2>3 | +-----+ | 0 | +-----+ # mysql> select 2>=3; +------+ | 2>=3 | +------+ | 0 | +------+
# mysql> select 5 between 1 and 10; +--------------------+ | 5 between 1 and 10 | +--------------------+ | 1 | +--------------------+
# mysql> select 5 in (1,2,3,4,5); +------------------+ | 5 in (1,2,3,4,5) | +------------------+ | 1 | +------------------+ # mysql> select 5 not in (1,2,3,4,5); +----------------------+ | 5 not in (1,2,3,4,5) | +----------------------+ | 0 | +----------------------+
# mysql> select null is NULL; +--------------+ | null is NULL | +--------------+ | 1 | +--------------+ mysql> select ‘a‘ is NULL; +-------------+ | ‘a‘ is NULL | +-------------+ | 0 | +-------------+
# mysql> select null IS NOT NULL; +------------------+ | null IS NOT NULL | +------------------+ | 0 | +------------------+ # mysql> select ‘a‘ IS NOT NULL; +-----------------+ | ‘a‘ IS NOT NULL | +-----------------+ | 1 | +-----------------+
# mysql> select ‘12345‘ like ‘12%‘; +--------------------+ | ‘12345‘ like ‘12%‘ | +--------------------+ | 1 | +--------------------+ # mysql> select ‘12345‘ like ‘12_‘; +--------------------+ | ‘12345‘ like ‘12_‘ | +--------------------+ | 0 | +--------------------+
# mysql> select ‘beijing‘ REGEXP ‘jing‘; +-------------------------+ | ‘beijing‘ REGEXP ‘jing‘ | +-------------------------+ | 1 | +-------------------------+ # mysql> select ‘beijing‘ REGEXP ‘xi‘; +-----------------------+ | ‘beijing‘ REGEXP ‘xi‘ | +-----------------------+ | 0 | +-----------------------+
逻辑运算符
#运算符号 # 作用 NOT 或 ! # 逻辑非 AND # 逻辑与 OR # 逻辑或 XOR # 逻辑异或
# mysql> select 2 and 0; +---------+ | 2 and 0 | +---------+ | 0 | +---------+ # mysql> select 2 and 1; +---------+ | 2 and 1 | +---------+ | 1 | +---------+
# mysql> select 2 or 0; +--------+ | 2 or 0 | +--------+ | 1 | +--------+ # mysql> select 2 or 1; +--------+ | 2 or 1 | +--------+ | 1 | +--------+ # mysql> select 0 or 0; +--------+ | 0 or 0 | +--------+ | 0 | +--------+ # mysql> select 1 || 0; +--------+ | 1 || 0 | +--------+ | 1 | +--------+
# mysql> select not 1; +-------+ | not 1 | +-------+ | 0 | +-------+ # mysql> select !0; +----+ | !0 | +----+ | 1 | +----+
# mysql> select 1 xor 1; +---------+ | 1 xor 1 | +---------+ | 0 | +---------+ # mysql> select 0 xor 0; +---------+ | 0 xor 0 | +---------+ | 0 | +---------+ # mysql> select 1 xor 0; +---------+ | 1 xor 0 | +---------+ | 1 | +---------+ # mysql> select null or 1; +-----------+ | null or 1 | +-----------+ | 1 | +-----------+ # mysql> select 1 ^ 0; +-------+ | 1 ^ 0 | +-------+ | 1 | +-------+
位运算符
# 运算符号 # 作用 & # 按位与 | # 按位或 ^ # 按位异或 ! # 取反 << # 左移 >> # 右移
# 1、按位与 mysql> select 3&5; +-----+ | 3&5 | +-----+ | 1 | +-----+ # 2、按位或 mysql> select 3|5; +-----+ | 3|5 | +-----+ | 7 | +-----+ # 3、按位异或 mysql> select 3^5; +-----+ | 3^5 | +-----+ | 6 | +-----+ # 4、按位取反 mysql> select ~18446744073709551612; +-----------------------+ | ~18446744073709551612 | +-----------------------+ | 3 | +-----------------------+ # 5、按位右移 mysql> select 3>>1; +------+ | 3>>1 | +------+ | 1 | +------+ # 6、按位左移 mysql> select 3<<1; +------+ | 3<<1 | +------+ | 6 | +------+
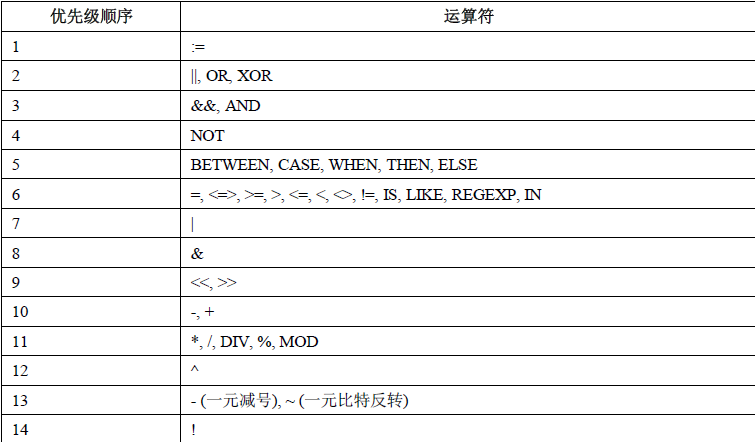
运算符优先级
# 总数:count # 查询男性有多少人,女性有多少人 select count(*) from students where gender = 1; select count(*) from students where gender = 2;
# 最大值:max # 查询最大的年龄 select max(age) from students; # 查询女性的最高 身高 select max(height) from students where gender = 2; # 最小值:min select min(height) from students where gender = 2;
# 求和:sum # 计算所有人的年龄总和 select sum(age) from students;
# 平均值:avg # 计算平均年龄 select avg(age) from students; # 计算平均年龄 sum(age)/count(*) # 四舍五入 round(123.23 , 1) 保留1位小数 # 计算所有人的平均年龄,保留3位小数 select round(avg(age),3) from students; # 计算男性的平均身高 保留2位小数 select round(avg(height),2) from students where gender = 1;
# 查询类型 cate_name 为 ‘超级本‘ 的商品名称 name 、价格 price ( where ) select name,price from goods where cate_name = "超级本"; # 显示商品的种类 # 1 分组的方式( group by ) select cate_name from goods group by cate_name; # 2 去重的方法( distinct ) select distinct cate_name from goods; # 求所有电脑产品的平均价格 avg ,并且保留两位小数( round ) select round(avg(price),2) from goods; # 显示 每种类型 cate_name (由此可知需要分组)的 平均价格 select cate_name,avg(price) from goods group by cate_name; #查询 每种类型 的商品中 最贵 max 、最便宜 min 、平均价 avg 、数量 count select max(price),min(price),avg(price),count(*) from goods group by cate_name; # 查询所有价格大于 平均价格 的商品,并且按 价格降序 排序 order desc # 1 查询平局价格(avg_price) select avg(price) as avg_price from goods; # 2 使用子查询 select * from goods where price > (select avg(price) as avg_price from goods) order by price desc; # 查询每种类型中最贵的电脑信息(难) # 1 查找 每种类型 中 最贵的 max_price 价格 select cate_name,max(price) as max_price from goods group by cate_name; # 2 关联查询 inner join 每种类型 中最贵的物品信息 select * from goods inner join(select cate_name,max(price) as max_price from goods group by cate_name) as max_price_goods on goods.cate_name=max_price_goods.cate_name and goods.price=max_price_goods.max_price; # 创建"商品分类"表 # 第一步 创建表 (商品种类表 goods_cates ) create table if not exists goods_cates( id int unsigned primary key auto_increment, name varchar(40) not null ); # 第二步 同步 商品分类表 数据 将商品的所有 (种类信息) 写入到 (商品种类表) 中 按照 分组 的方式查询 goods 表中的所有 种类(cate_name) select cate_name from goods group by cate_name; # (注意) 把查询出来的 结果 写入 goods_cates 表里去 ( insert into ) 只插入name insert into goods_cates(name) (select cate_name from goods group by cate_name); # 第三部 同步 商品表 数据 通过 goods_cates 数据表来更新 goods 表 # 因为要通过 goods_cates表 更新 goods 表 所以要把两个表连接起来 select * from goods inner join goods_cates on goods.cate_name = goods_cates.name; # 把 商品表 goods 中的 cate_name 全部替换成 商品分类表中的 商品id ( update ... set ) update (goods inner join goods_cates on goods.cate_name = goods_cates.name) set goods.cate_name = goods_cates.id; # 第四部 修改表结构 # 查看表结构(注意 两个表中的 外键类型需要一致) desc goods; #修改表结构 alter table 字段名字不同 change,把 cate_name 改成 cate_id int unsigned not null alter table goods change cate_name cate_id int unsigned not null; # 创建 商品品牌表 goods_brands # 第一步 创建 "商品品牌表" 表 # 第一种方式 先创建表 create table goods_brands ( id int unsigned primary key auto_increment, name varchar(40) not null); # 插入数据 brand_name(分组) # 按照 分组 的方式查询 goods 表中的所有 种类(brand_name) select brand_name from goods group by brand_name; # (注意) 把查询出来的 结果 写入 goods_brands 表里去 ( insert into ) 只插入name insert into goods_brands(name) (select brand_name from goods group by brand_name); # 第二种方式 创建表的同时插入数据(了解,不建议使用) create table goods_brands ( id int unsigned primary key auto_increment, name varchar(40) not null) select brand_name as name from goods group by brand_name; # 第二步 同步数据 # 通过goods_brands数据表来更新goods数据表 g.brand_name=b.id update (goods inner join goods_brands on goods.brand_name = goods_brands.name) set goods.brand_name = goods_brands.id; # 第三步 修改表结构 # 通过alter table语句修改表结构 brand_id int unsigned not null alter table goods change brand_name brand_id int unsigned not null; # 外键的使用(了解) # 创建外键 # -- 向goods表里插入任意一条数据 insert into goods (name,cate_id,brand_id,price) values(‘老王牌拖拉机‘, 10, 10,‘6666‘); # 约束 数据的插入 使用 外键 foreign key alter table goods add foreign key (brand_id) references goods_brands(id); alter table goods add foreign key (cate_id) references goods_cates(id); alter table goods add foreign key(brand_id) references goods_brands(id); # 失败原因 老王牌拖拉机 delete delete from goods where name="老王牌拖拉机"; # 创建表的同时设置外键 (注意 goods_cates 和 goods_brands 两个表必须事先存在) create table goods( id int primary key auto_increment not null, name varchar(40) default ‘‘, price decimal(5,2), cate_id int unsigned, brand_id int unsigned, is_show bit default 1, is_saleoff bit default 0, foreign key(cate_id) references goods_cates(id), foreign key(brand_id) references goods_brands(id) ); # 如何取消外键约束 #需要先获取外键约束名称,该名称系统会自动生成,可以通过查看表创建语来获取名称 show create table goods; # 获取名称之后就可以根据名称来删除外键约束 alter table goods drop foreign key goods_ibfk_1; alter table goods drop foreign key goods_ibfk_2; # 总结:在实际开发中,很少会使用到外键约束,会极大的降低表更新的效率
 MySQL 的介绍到这篇基本就算完事了,后期我会继续更新,关注不迷路哦,多多支持!!!
MySQL 的介绍到这篇基本就算完事了,后期我会继续更新,关注不迷路哦,多多支持!!!
标签:ble 写入 自动提交 mode detail mysql 复制 strcmp 读取 字段名
原文地址:https://www.cnblogs.com/yangmaosen/p/12569399.html
