标签:sizeof 缺点 syn 技术 代码 排序 hone 第一个 color
字典树,又称单词查找树、Trie树、前缀树,是一种树形结构,是一种哈希树的变种。
典型应用是用于统计、排序和保存大量的字符串(但不仅限于字符串)。
常见操作有插入和查找,删除操作少见。
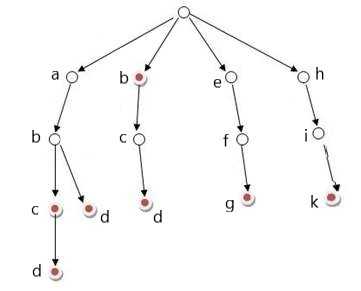
如图,最上方的节点为根节点,根节点不包含字符
从根节点开始到每一个红点的路径上字符拼接而成的字符串就是一个单词
| 该图中拥有的单词 |
|---|
| abc |
| abcd |
| abd |
| b |
| bcd |
| efg |
| hik |
常见的Trie树储存方式共有两种
代码以下述功能为例:
直接用数组来储存下一个节点的位置
const int MAXN=1e5+50;
int tree[MAXN][26]; //tree[i][j] 表示节点i的第j种儿子的节点id
int flag[MAXN]; //flag[i] 表示节点i建树时访问过的次数(前缀数量)
int cnt=0; //cnt储存目前最大的节点编号,添加节点时调用
这种写法写起来最简单,但是空间消耗巨大(256MB理想状态最多也只能开250w)
不论节点 i 的第 j 种儿子是否存在,都需要给他开一个int的空间来储存
规定id=0为根节点,tree值为0表示无儿子节点
void addNode(char *str)
{
int root=0,id; //root表示处理到某个字符时上一个节点的id
for(int i=0;str[i]!=‘\0‘;i++)
{
id=str[i]-‘a‘;
if(tree[root][id]==0)
tree[root][id]=++cnt;
root=tree[root][id];
flag[root]++;
}
}
输入单词,从头开始循环单词,root用来迭代节点的id,初始值为0
如果root节点的第id个孩子不存在(说明之前没有访问过)
让他的值变为++cnt来动态把节点加在数组可行部分的后面
因为要求的是以某个字符串为前缀的单词数,所以把树上经过某个节点的次数给记录下来,让 flag+1
int query(char *str)
{
int root=0,id;
for(int i=0;str[i]!=‘\0‘;i++)
{
id=str[i]-‘a‘;
if(tree[root][id]==0)
return 0; //查询的时候出现节点不存在的情况的话,说明不存在这样前缀的单词
root=tree[root][id];
}
return flag[root];
}
相似于添加单词的代码,只不过不需要对树的结构进行改变
如果在查找的过程中遇到路径上某个节点的儿子不存在,说明不存在这样前缀的单词(所以建树时没有加入这个节点)
退出循环时root指向的节点正好为字符串最后一个字符表示的节点,将访问次数输出即可
采用结构体指针的方式来储存信息
struct node
{
int flag;
node *next[26];
};
node root;
这种写法采用的是动态分配空间的方法,只有在使用时才分配空间,相对于上一种写法能节省更多的空间
但是如果出现多组数据的情况,上一种写法只能采用memset循环使用空间,而这种写法如果要释放内存的话还需要写一个内存释放函数
如果不释放内存,则只需要重置根节点的26个指针为NULL即可
const int MAXLEN=100;
char str[MAXLEN];
void addNode() //循环法
{
node *nd=&root;
node *tmp;
int id;
for(int i=0;str[i]!=‘\0‘;i++)
{
id=str[i]-‘a‘;
if(nd->next[id]==NULL)
{
tmp=(node*)malloc(sizeof(node));
for(int j=0;j<26;j++)
tmp->next[j]=NULL;
tmp->flag=1;
nd->next[id]=tmp;
nd=tmp; //指针迭代
}
else
{
nd=tmp;
nd->flag++;
}
}
}
void addNode(node *nd,int pos) //迭代法,调用addNode(&root,0)
{
if(str[pos]==‘\0‘)
return;
int id=str[pos]-‘a‘;
if(nd->next[id]==NULL) //将 nd->next[id] 看成这一部分的整体
{
nd->next[id]=(node*)malloc(sizeof(node));
for(int i=0;i<26;i++)
nd->next[id]->next[i]=NULL;
nd->next[id]->flag=1;
addNode(nd->next[id],pos+1);
}
else
{
nd->next[id]->flag++;
addNode(nd->next[id],pos+1);
}
}
在节点不存在时动态申请空间
const int MAXLEN=100;
char str[MAXLEN];
int query() //循环法
{
node *nd=&root;
for(int i=0;str[i]!=‘\0‘;i++)
{
if(nd==NULL)
return 0; //执行过程中找到不存在的节点,说明前缀不存在
nd=nd->next[str[i]-‘a‘];
}
return nd->flag;
}
int query(node* nd,int pos) //迭代法,调用query(&root,0)
{
if(nd==NULL)
return 0; //执行过程中找到不存在的节点,说明前缀不存在
if(str[pos]==‘\0‘)
return nd->flag; //找到最后一个位置时直接返回flag值
return query(nd->next[str[pos]-‘a‘],pos+1);//否则返回下一次迭代的值
}
void del(node *nd) //迭代释放空间
{
for(int i=0;i<10;i++)
if(nd->next[i]!=NULL)
del(nd->next[i]);//先释放深度更大的节点
delete nd;//再释放自己
}
/*
注意,释放的对象原则上是只能针对动态申请空间的对象
所以不能直接调用&root
而是对root的子节点判断后释放
所以多组样例的情况初始化空间应该如下处理
*/
for(int i=0;i<10;i++)
{
if(root.next[i]!=NULL)
del(root.next[i]);
root.next[i]=NULL;
}
指针储存方式优点有很多,但是要求对指针操作熟练
注意不要出现空指针操作!
?
?
均采用上述储存方式 二 的写法
思路同上文,记录路径经过的次数即可
#include<bits/stdc++.h>
using namespace std;
struct node
{
int flag;
node *next[26];
};
node root;
char str[233];
void addNode(node *nd,int pos)
{
if(str[pos]==‘\0‘)
return;
int id=str[pos]-‘a‘;
if(nd->next[id]==NULL) //将 nd->next[id] 看成这一部分的整体
{
nd->next[id]=(node*)malloc(sizeof(node));
for(int i=0;i<26;i++)
nd->next[id]->next[i]=NULL;
nd->next[id]->flag=1;
addNode(nd->next[id],pos+1);
}
else
{
nd->next[id]->flag++;
addNode(nd->next[id],pos+1);
}
}
int query(node* nd,int pos)
{
if(nd==NULL)
return 0; //执行过程中找到不存在的节点,说明前缀不存在
if(str[pos]==‘\0‘)
return nd->flag; //找到最后一个位置时直接返回flag值
return query(nd->next[str[pos]-‘a‘],pos+1);//否则返回下一次迭代的值
}
int main()
{
int i;
for(i=0;i<26;i++)
root.next[i]=NULL;
while(true)
{
i=0;
while((str[i]=getchar())!=‘\n‘)
i++;
if(i==0)
break;
str[i]=‘\0‘;
addNode(&root,0);
}
while(scanf("%s",str)!=EOF)
printf("%d\n",query(&root,0));
return 0;
}
flag设为bool类型变量
为true表示有单词以当前节点作为结尾
在每次输入后先判断是否已经存在单词,如果不存在再进行插入操作并让答案+1即可
贼恶心的题目,正常读入注意 空行/行首有空格/行末有空格/单词之间间隔2个及以上空格 的情况,或者读入行后使用stringstream处理
#include<bits/stdc++.h>
using namespace std;
struct node
{
bool flag;
node *next[26];
};
node root;
char str[233];
int ans;
void addNode(node *nd,int pos)
{
if(str[pos]==‘\0‘)
{
if(nd->flag) //如果已经是某个单词的结尾,答案-1
ans--;
nd->flag=true; //标记结尾
return;
}
int id=str[pos]-‘a‘;
if(nd->next[id]==NULL) //将 nd->next[id] 看成这一部分的整体
{
nd->next[id]=(node*)malloc(sizeof(node));
nd->next[id]->flag=false; // 初始置于false
for(int i=0;i<26;i++)
nd->next[id]->next[i]=NULL;
addNode(nd->next[id],pos+1);
}
else
addNode(nd->next[id],pos+1);
}
string s;
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);cout.tie(0);
while(getline(cin,s))
{
if(s[0]==‘#‘)
break;
int i,j,len;
ans=0;
for(i=0;i<26;i++)
root.next[i]=NULL;
root.flag=false;
len=s.length();
s=s+" ";//最后面加个空格方便处理
i=0;
while(s[i]==‘ ‘)//处理行首空格
i++;
while(i<len)
{
j=0;
while(s[i]!=‘ ‘)
str[j++]=s[i++];
while(s[i]==‘ ‘)//处理单词间空格
i++;
str[j]=‘\0‘;
addNode(&root,0);
ans++;
}
cout<<ans<<‘\n‘;
}
return 0;
}
/*
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);cout.tie(0);
while(getline(cin,s))
{
if(s[0]==‘#‘)
break;
int i,j;
ans=0;
for(i=0;i<26;i++)
root.next[i]=NULL;
root.flag=false;
stringstream in(s);
while(in>>str)
{
buildTree(&root,0);
ans++;
}
cout<<ans<<‘\n‘;
}
return 0;
}
*/
挺常见的一种题型,因为数据范围大所以只能通过字典树判断
HDU 1671 Phone List Memory Limit 32MB
POJ 3630 Phone List Memory Limit 64MB
本题对空间有要求,不动态释放内存的话POJ不知道能不能过,但是HDU会MLE
想法就是在插入单词的过程中要保证:
然后在每个样例前释放一次内存即可
#include<bits/stdc++.h>
using namespace std;
struct node
{
bool flag;
node *next[10];
}root;
char str[20];
bool addNode()
{
int i,j,id;
node *nd=&root;
for(i=0;str[i]!=‘\0‘;i++)
{
id=str[i]-‘0‘;
if(nd->next[id]==NULL)
{
nd->next[id]=(node*)malloc(sizeof(node));
nd->next[id]->flag=false;
for(j=0;j<10;j++)
nd->next[id]->next[j]=NULL;
nd=nd->next[id];
}
else
{
if(nd->next[id]->flag)
return false;
nd=nd->next[id];
}
}
for(i=0;i<10;i++)
if(nd->next[i]!=NULL)
return false;
nd->flag=true;
return true;
}
void del(node *nd)
{
for(int i=0;i<10;i++)
if(nd->next[i]!=NULL)
del(nd->next[i]);
delete nd;
}
void solve()
{
int n,i;
bool flag=true;//标记答案是否合法
for(int i=0;i<10;i++)
{
if(root.next[i]!=NULL)
del(root.next[i]);
root.next[i]=NULL;
}
root.flag=false;
scanf("%d",&n);
while(n--)
{
scanf("%s",str);
if(flag&&!addNode())//如果答案已经不合法,不需要继续标记(依靠&&运算符的运算规则,左false则右不执行)
flag=false;
}
puts(flag?"YES":"NO");
}
int main()
{
int T;
scanf("%d",&T);
while(T--)
solve();
return 0;
}
因为要考虑到所有情况互不重复,所以要先建完树再去处理而不是边建树边处理(否则后面的答案可能不是最优)
此时的flag记录的是节点走过的次数
如果flag值为1,说明接下来这条路径只包含一个单词,说明就是个特征单词
此时只需要输出到第一次遇见flag为1的节点即可
#include<cstdio>
#include<cstdlib>
using namespace std;
struct node
{
int flag;
node *next[26];
}root;
char str[1050][30];
void addNode(int pos)
{
node *nd=&root;
for(int i=0;str[pos][i]!=‘\0‘;i++)
{
int id=str[pos][i]-‘a‘;
if(nd->next[id]==NULL)
{
nd->next[id]=(node*)malloc(sizeof(node));
nd=nd->next[id];
nd->flag=1;
for(int j=0;j<26;j++)
nd->next[j]=NULL;
}
else
{
nd=nd->next[id];
nd->flag++;
}
}
}
char tmp[30];
char* query(int pos)
{
int i,id;
node *nd=&root;
for(i=0;str[pos][i]!=‘\0‘;i++)
{
tmp[i]=str[pos][i];
id=str[pos][i]-‘a‘;
if(nd->next[id]->flag==1)//如果接下来的路只包含一个单词,则把这个第一个节点记录下来就可以作为特征答案
{
tmp[i+1]=‘\0‘;
return tmp;
}
nd=nd->next[id];
}
tmp[i]=‘\0‘;//到最后都没有遇到路径为1的情况,说明这个单词是别的单词的前缀,所以输出整个单词
return tmp;
}
int main()
{
int i,cnt=0;
root.flag=0;
for(i=0;i<26;i++)
root.next[i]=NULL;
while(scanf("%s",str[cnt])!=EOF)
addNode(cnt++);
for(i=0;i<cnt;i++)
printf("%s %s\n",str[i],query(i));
return 0;
}
持续补题……
【数据结构】字典树/Trie树/前缀树 - 字符串的统计、排序和保存
标签:sizeof 缺点 syn 技术 代码 排序 hone 第一个 color
原文地址:https://www.cnblogs.com/stelayuri/p/12562945.html