标签:reids 缺点 更改 使用 数值 语法 file 授权 word
1.当数据达到了上亿级别单个库使用效率性能是十分低下的,当进行查询等操作时候,也是从根节点去找到子节点然后在找到叶节点 ,
数亿条取一条数据 性能就不是很迅速,而且单机的存储量,链接数,并发量,处理能力十分有限。 这个时候数据库就容易遇到了系统瓶颈,
所以为了 降低性能,缩短查询时间,减少数据库的负担,会采取分表分库的方法 。
垂直拆分:就是不同的表存储在不同的数据库,按照业务进行独立划分 ,主要通过‘列’进行划分,将不常用的字段或者较大的字段拆分出去分到扩展表中,
其次mysql是通过数据页进行存储的,按照行为单位 加载到内存当中,如果一条记录占用空间较大会导致跨分页造成额外的性能消耗,
通过大表分表小表会提高访问频率,内存加载更多的数据,命中率高,磁盘io读写快。
垂直拆分 根据er关系图
垂直拆分优点: 1 解决业务系统层面的耦合,业务清晰
2 对不同数据的业务管理、维护、监控、扩展 有更好的提高
3 高并发情况下 提高io读写效率
垂直拆分缺点: 1 部分无法进行了jion 跨库了
2 事务复杂的处理 难度较高
水平(横向)切分: 当一个单库无法再进行细粒度的垂直拆分后,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。
根据同一个表进行表内数据 的逻辑关系,拆分不同的库内表和不同库的表 ,每个表只包含一部分 数据
库内分表 : 库内分表并没有解决单一数据量过大的问题,没有将表分到不同数据上的表,对mysql 数据库压力来说没有减小,大家还是竞争同一io,性能,cpu资源 ,帮助并不是很大。
水平拆分优点:
1 提高了数据库单表数据量较大,提升系统稳定性和负载能力
水平切分的缺点:
1 分库存储表 join 表关系较麻烦
2 事务处理不是很好,跨分片的事务一致性难以保证
3 数据多次扩展难度和维护量极大
分片规则:
1 根据数值范围(时间 区域 id) id 1~9999 10000~19999等 其中有些系统也有冷热备份机制 ,将不常用的历史数据分到其他库中 。
2 根据数值取模 cusno 字段切分到4个库中,余数为0的放到第一个库,余数为1的放到第二个库,以此类推。这样同一个用户的数据会分散到同一个库中,如果查询条件带有cusno字段,则可明确定位到相应库去查询。
优点: 1 不容易让数据库产生瓶颈问题
缺点: 1 如果频繁使用 cusno 查询 会从不同的4个库中选取,数据最后在内存中融合,性能反而降低 。
A 服务 B服务 (设计的时候尽可能考虑到join)
1 在服务层做调用,先去a里面查,然后根据id 再去b 但不要批量查询。
2 全局表,每个业务层面都可能用到,在每一个独立的子库里面 数据是一模一样的 全局表数据变更比较少,基于全局应用,如果是公共服务也可以做公共服务
3 对字段做冗余 更改的话 可以通过定时任务 或者 任务通知
在应用层采用拼接手段,查询之后在组装。
1 自增id做主键
2 uuid 做主键值比较长,会造成索引比较大,性能比较低 。
3 snowflate 算法生成的 雪花算法
4 数据库表专门存储id
1 保证多个数据库表的强一致性 rpc的 二阶提交 或 三阶提交
mysql的数据文件和二进制文件: /var/lib/mysql/
mysql的配置文件: /etc/my.cnf
mysql的日志文件: /var/log/mysql.log
1 master 主机
创建一个sql 用户为repl准许其他用户通过远程访问远程master,读取其二进制文件
1.1 create user replidentified by ‘repl‘; // 从新确定用户为repl
1.2 GRANT REPLICATION SLAVE ON . TO ‘repl‘@‘%‘ IDENTIFIED BY ‘repl‘ ;//repl用户必须具有REPLICATION SLAVE权限 ,用户授权复制从机
2 修改etc/my.cnf文件在【mysqld】添加
2.1 log-bin=mysql-bin ; // 开启二进制流文件
server-id=140; // 定义唯一id
2.2 service mysqld restart // sql重新启动
2.3 show master status ; // 查看状态
2 slave 从机
2.1 修改142 my.cnf配置文件, 在[mysqld]下增加如下配置
server-id=132 服务器id,唯一
relay-log=slave-relay-bin
relay-log-index=slave-relay-bin.index
read_only=1
2.2 重启数据库: systemctl restart mysqld
2.3 连接到数据库客户端,通过如下命令建立同步连接
change master to master_host=‘192.168.11.140‘, master_port=3306,master_user=‘repl‘,master_password=‘repl‘,master_log_file=‘mysql-bin.000001‘,master_log_pos=0;
2.4 执行 start slave
2.5 show slave status\G;查看slave服务器状态,当如下两个线程状态为yes,表示主从复制配置成功
Slave_IO_Running=Yes
Slave_SQL_Running=Yes
3 bin.log 是二进制流 ,可以通过命令 进行 64位 查看 bin.log代码
先建立二进制流文件binlog 之后通过io流在master读 binlog之后在slave上写到reply日志中 ,然后slave 在通过 sql 内部线程 来读取reply文件 。
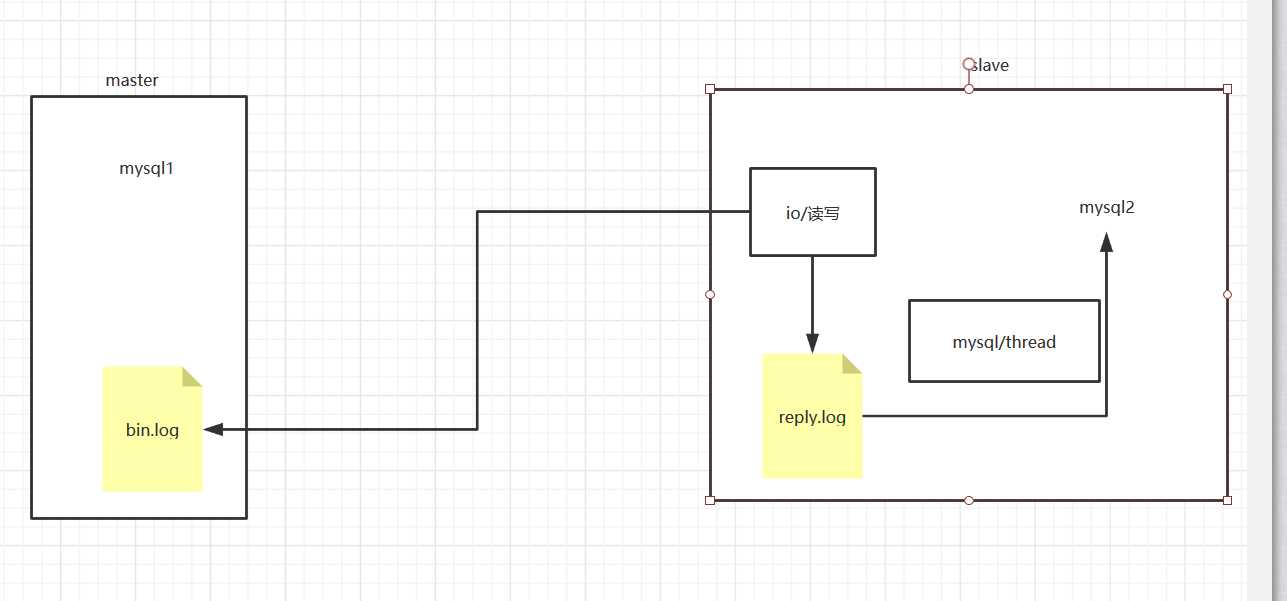
binlog 里面分为3 种类型
statement: 是对mysql的所有操作进行记录,缺点是 有uuid 或者时间now的时候 会对从表产生了数据不一致的问题
row: 是成功之后的一条复制,eccpet 1行 ,复制这个操作,但是占用空间大 。
mixed: 是混合机制mysql 自动来判断 用row还是 statement ;
语法:
binlog 位置/var/lib/mysql
show variables like ‘%log%‘
sync_bin_log 为0 的时候 不会立即更新 根据bin_log_cache 来决定
sync_bin_log=1 数据安全性最高 但是性能会下降
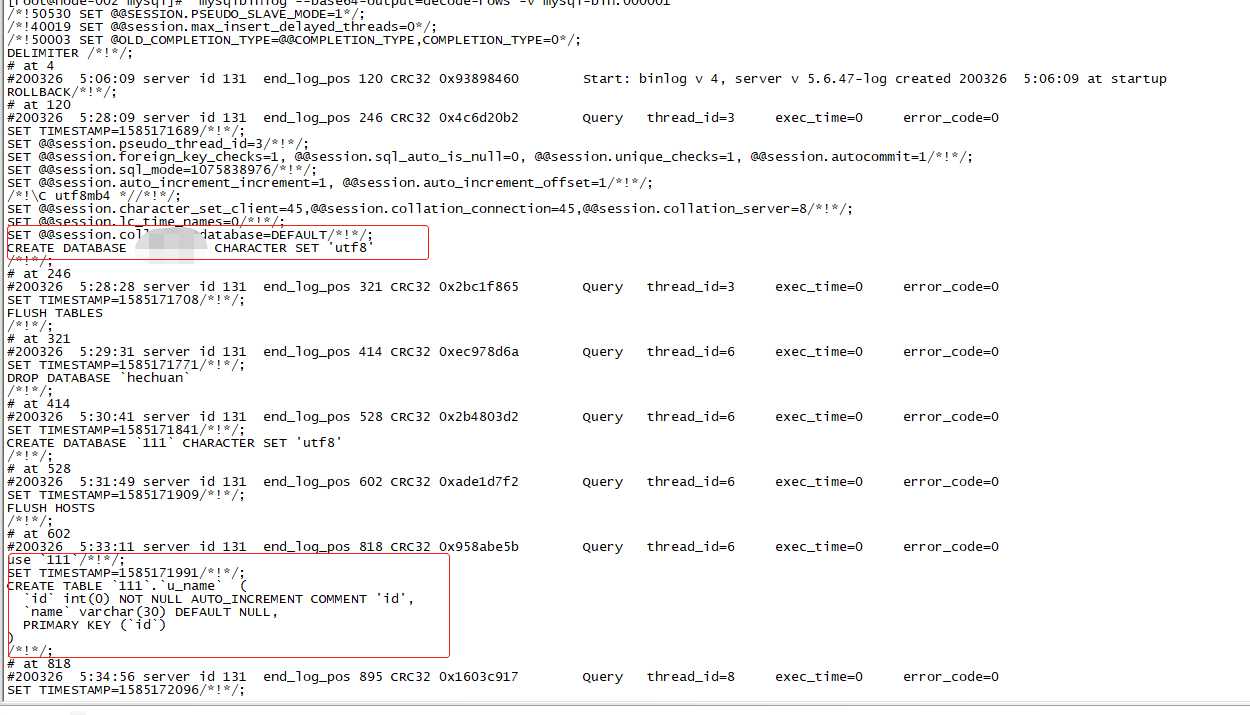
binlog 二进制查看 mysqlbinlog --base64-output=decode-rows -v mysql-bin.000001 查看binlog的内容
设置类型
set global binlog_format=’row/mixed/statement’;
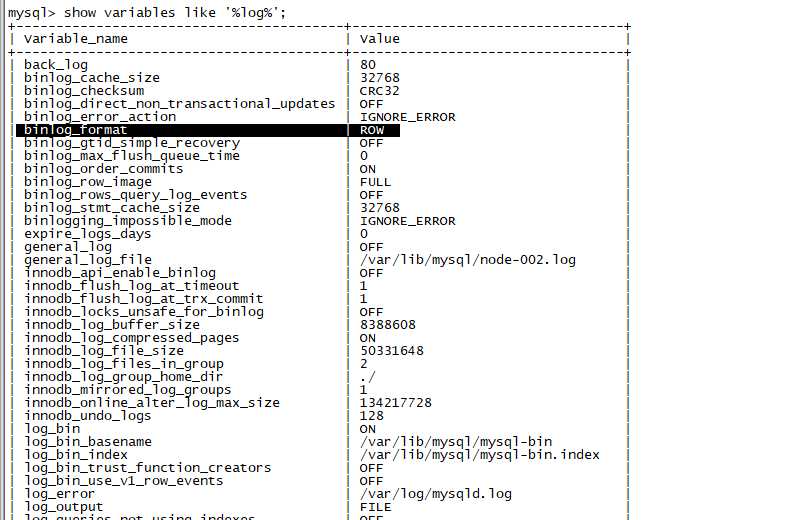
或者在vim /etc/my.cnf 的[mysqld]下增加binlog_format=‘mixed’
4 主从复制产生的问题和解决办法
产生问题有 :1 网络延迟问题 :bin文件的传输延迟
2 高并发下数据库达到瓶颈 :slave一个sql线程所能承受的范围,或者slave的大型query语句产生锁等待
3 磁盘写耗费时间:文件通知更新、磁盘读取延迟、磁盘写入延迟
解决问题: 1. 在数据库和应用层增加缓存处理,优先从缓存中读取数据,master 数据库加入 reids 配置种 ,然后在去redis中读取,没有再去数据库读 这样提供了时间
2. 减少slave同步延迟,可以修改slave库sync_binlog属性
3. 增加延时监控
Nagios做网络监控
mk-heartbeat(主表和从表建立一个表里面有时间 通过时间差来判断)
标签:reids 缺点 更改 使用 数值 语法 file 授权 word
原文地址:https://www.cnblogs.com/chianw877466657/p/12557559.html