标签:style blog class code c java
浅析C/C++中的switch/case陷阱
先看下面一段代码:
文件main.cpp

#include<iostream> using namespace std; int main(int argc, char *argv[]) { int a =0; switch(a) { case 0: int b=1;cout<<b<<endl;break; case 1: cout<<b<<endl;break; default:break; } return 0; }
在gcc编译器下编译的结果为:

提示跳过了变量b的初始化过程。对于一个局部变量,它的作用域为它所定义的地方到它所在的语句块结束为止,那么对于变量b,它所在的最小语句块为switch{}块,那么也就说在case 0后面的部分,变量b都是可见的(注意在case 0之前变量b是无法访问的)。考虑这样一种情况,当a的值为0,那么程序就跳到case 1执行,此时b虽然可以访问,但是跳过了它的初始化过程。而如果在定义变量的同时进行了初始化,表明程序员希望初始化这个变量,但是此时跳过了该变量的初始化,就可能导致程序出现程序员无法意料的情况,因此编译器为了避免跳过这样的初始化而造成无法预料的结果,就对该语句进行报错。
如果将上述代码改为:
switch(a) { case 0: int b;b=0;cout<<b<<endl;break; case 1: cout<<b<<endl;break; default: break; }
编译的结果为:

只是进行了警告,因为在定义变量的时候没有进行初始化,也就是说程序怎么执行都不会跳过变量的初始化过程,不会说由于跳过了该过程而造成无法预料的错误或程序崩溃现象。因此只是进行了警告。
再看下面这段代码:
switch(a) { case 0: break; default: int b=1;cout<<b<<endl;break; }
这段代码没有报错。因为如果执行case 0,变量b没有进行初始化,但是由于在case 0部分b是不可见的,因此不会对程序造成任何影响,而如果执行default分支,则b会被初始化,因此程序没有报错。
归根到底,出现上述的crosses initialization和jump to case label错误的原因是由于变量的作用域问题,因此一个好的习惯就是在case子句下面加上大括号来限定变量的作用域。
switch(a) { case 0: {int b=1;cout<<b<<endl;break;} case 1: break; default: break; }
不过要注意,一旦加上了大括号,在case 0后面便不能访问到变量b了。
注意,如果上述代码以C方式进行编译,编译结果则会有所不同:
main.c
#include <stdio.h> #include<stdlib.h> int main(int argc, char *argv[]) { int a =2; switch(a) { case 0: int b=17;printf("%d\n",b);break; case 1: break; default:printf("%d\n",b);break; } return 0; }
编译结果:

报的错误意思是在该标签下不能定义变量。为什么呢?原因很简单,在C语言中所有的变量定义都必须放到所在语句块的最前面。所以如果改成这样:
#include <stdio.h> #include<stdlib.h> int main(int argc, char *argv[]) { int a =2; switch(a) { int b=17; case 0: printf("%d\n",b);break; case 1: break; default:printf("%d\n",b);break; } return 0; }
编译结果:
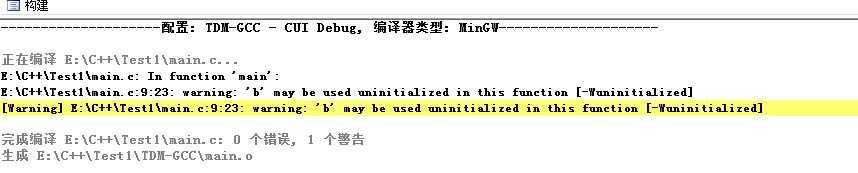
没有报错,注意这里没有报crosses initialization的错误,这点C和C++有点不同。如果以C++方式编译,肯定会报crosses initialization的错误,这也更加说明C++在语法方面要求比C更加严格。
该程序运行的结果:
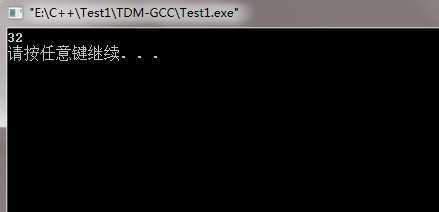
输出32,是一个随机值。因为b并没有进行初始化,所以输出的是随机值。
以上只是个人观点,若有不正之处,恳请指正,以免误导他人。
浅析C/C++中的switch/case陷阱,布布扣,bubuko.com
标签:style blog class code c java
原文地址:http://www.cnblogs.com/dolphin0520/p/3729579.html