标签:分析 意思 not each 就是 str teacher 通配 ima
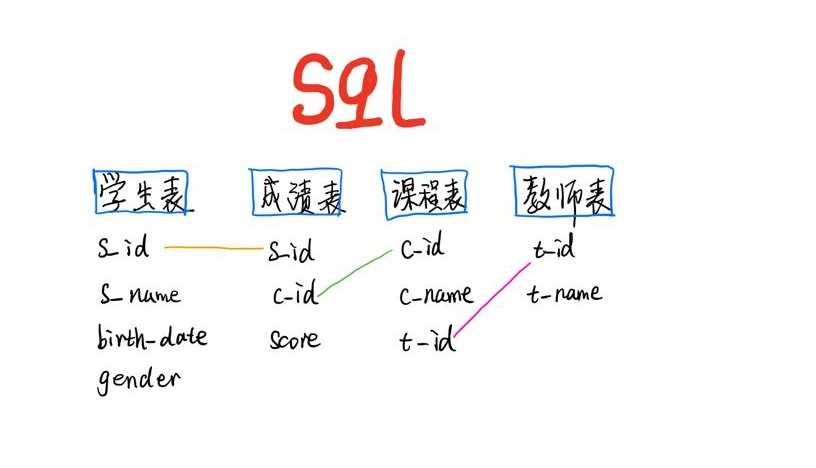
继续来练习 sql 查询, 似乎也没有什么窍门, 跟着写多了, 自然就记住了, 这个帖子, 来记录一波, 模糊查询 like; 四表关联查询: 老师名 -> 老师id -> 课程id -. 学生 id -> 学生表
查询姓 “王” 的学生个数;
查询姓名中包含 "王" 的学生信息;
查询姓名为 3个字的学生姓名和性别;
查询姓张的老师中, 不重名的老师个数;
分析
主要是关于模糊查询这块, 在 mysql 中, 即关于关键字 “like" 和 通配符 ”%, - “ 等的应用。
select
count(s_id) as 老师人数
from student
where
s_name like "王%";
+--------------+
| 老师人数 |
+--------------+
| 1 |
+--------------+
1 row in set (0.00 sec)
-- % 匹配任意
select *
from student
where s_name like "%王%";
+------+--------+------------+--------+
| s_id | s_name | birth_date | gender |
+------+--------+------------+--------+
| 0001 | 王二 | 1989-01-01 | 男 |
+------+--------+------------+--------+
1 row in set (0.00 sec)
-- "_" 下划线表示匹配单个字符
select
s_name,
gender
from student
where s_name like "___";
+-----------+--------+
| s_name | gender |
+-----------+--------+
| 胡小适 | 男 |
+-----------+--------+
1 row in set (0.00 sec)
-- distinct 去重
select
count(distinct s_name) as "王姓不重名老师数"
from student
where s_name like "王%";
+--------------------------+
| 王姓不重名老师数 |
+--------------------------+
| 1 |
+--------------------------+
1 row in set (0.00 sec)
查询没有选过 "仲尼" 老师课的学生的学号, 姓名, 性别.
分析
涉及 教师表, 课程表, 成绩表, 学生表 . 一步步查出来即可
面向过程
先根据老师 "姓名" -> 老师 id -> 课程 id -> 选课 score 拿到 学生 id -> 学生表信息
a. 通过老师姓名 "仲尼" 从 教师表 拿 "教师id"
select
t_id
from teacher
where t_name = "仲尼";
+------+
| t_id |
+------+
| 0002 |
+------+
1 row in set (0.00 sec)
b. 通过 "教师id" 从 课程表 拿到 "课程id"
select
c_id
from course
where
t_id = (
select
t_id
from teacher
where t_name = "仲尼"
);
+------+
| c_id |
+------+
| 0001 |
+------+
c. 通过 "课程id" 从 成绩表 拿到 "学生id" (课程: 学生 是 1:n)
select
s_id
from score
where c_id = (
select
c_id
from course
where
t_id = (
select
t_id
from teacher
where t_name = "仲尼"
)
);
+------+
| s_id |
+------+
| 0001 |
| 0003 |
+------+
d. 通过 "学生id" 从 学生表 拿到 学生的学号, 姓名, 性别 (没选 就 not in )
-- 没有选就 not in
select
s_id as "学号",
s_name as "姓名",
gender as "性别"
from student
where s_id not in (
select
s_id
from score
where c_id = (
select
c_id
from course
where
t_id = (
select
t_id
from teacher
where t_name = "仲尼"
)
)
);
+--------+--------+--------+
| 学号 | 姓名 | 性别 |
+--------+--------+--------+
| 0002 | 星落 | 女 |
| 0004 | 油哥 | 男 |
+--------+--------+--------+
2 rows in set (0.00 sec)
这种思路, 感觉跟咱变成用的, 面向过程是一样的思维, 比较注重逻辑关系. 我个人是比较喜欢的, 逻辑性和推理是我一直比较感兴趣的话题, 尤其是数学公式推到, 我觉得非常的有意思. 当然这里我能写出这个一步步的逻辑呢, 主要还是基于对表字段的熟悉和其关联关系, 表关系 (1:1, 1:n, n:n )等的掌握, 这里逻辑, 即:
老师姓名 -> 老师id -> 课程 id -> 学生id -> 学生信息
tips: 成绩表中, 学生 与 选课 是 1: n 的关系哦
但业务中, 往往对表字段, 关联不那么熟悉 , 说业务嘛, 了解业务就已经是非常头疼的事情了, 还有一个表字段有很多啥的, 搞起来则麻烦对于理解这些逻辑关联关系.
连接查询写法
思路还是一样的, 差别就是, 我个人感觉, 这是一种 "面向对象" 的写法 , 当然不是咱真正的面向对象, 就是 表拼接 .
分析
关键是在于 "选课" 这张表, 即成绩表, 它的字段有:
学号, 课程号, 课程名称, 成绩
有了 "课程号" 不就知道了 "教师id" 和 "教师姓名" 了吗 (left join 或 inner join 都行)
学号, 课程号, 课程名称, 成绩; 教师id, 教师姓名
最后, 根据 "学号" 不就知道学生信息了嘛 (inner join)
学名, 姓名,性别;学号, 课程号, 课程名称, 成绩; 教师id, 教师姓名
-- 注意别名的使用
select
s.*,
c.*,
t.*
from score as s
-- 成绩表 关联 课程表
inner join course as c
on
s.c_id = c.c_id
-- 课程表 关联 教师表
inner join teacher as t
on
c.t_id = t.t_id
where
t.t_name = "仲尼";
+------+------+-------+------+--------+------+------+--------+
| s_id | c_id | score | c_id | c_name | t_id | t_id | t_name |
+------+------+-------+------+--------+------+------+--------+
| 0001 | 0001 | 80 | 0001 | 语文 | 0002 | 0002 | 仲尼 |
| 0003 | 0001 | 80 | 0001 | 语文 | 0002 | 0002 | 仲尼 |
+------+------+-------+------+--------+------+------+--------+
其实 , 咱只要用到 s_id 就可以了, 以 s_id 作为条件 去查出相应的 学生信息即可
select
s_id,
s_name,
gender
from student
where
s_id not in (
select
s.s_id
from score as s
-- 成绩表 关联 课程表
inner join course as c
on
s.c_id = c.c_id
-- 课程表 关联 教师表
inner join teacher as t
on
c.t_id = t.t_id
where
t.t_name = "仲尼"
);
+------+--------+--------+
| s_id | s_name | gender |
+------+--------+--------+
| 0002 | 星落 | 女 |
| 0004 | 油哥 | 男 |
+------+--------+--------+
2 rows in set (0.00 sec)
表关联查询的这种方式, 我在真是的业务中是用的蛮多的, 毕竟我去了解每个表的字段, 逻辑什么的还是比较麻烦的, 一个表的字段是很多的, 我通常就给他们都拼接起来一张大表, 然后再筛选. 核心还是在思考这3个核心的问题:
标签:分析 意思 not each 就是 str teacher 通配 ima
原文地址:https://www.cnblogs.com/chenjieyouge/p/12588332.html