标签:text targe 假设 show new uda hid image inf
1.定义: 所谓排序,即是整理文件中的内容,使其按照关键字递增或递减的顺序进行排列。 输入:n个记录,n1,n2……,其对应1的关键字为k1,k2…… 输出:n(i1),n(i2)……,使得k(i1)<=k(i2)…… (形象点讲就是排排坐,调座位,高在前低在后;或者低在前高在后) 2.排序算法的评价的专业术语 (1)稳定性 稳定:在排序的文件中,若存在多个关键字相同的记录,经过排序后,这些具有相同 关键字的记录之间的相对顺序不会发生改变。 不稳定:若具有相同关键字记录之间的相对次序发生改变,则成为不稳定的排序算法。 (2)复杂度 时间复杂度:一个算法执行所需消耗的时间。 空间复杂度:运行完该程序所需要的内存大小 (3)排序方式 内排序:在排序过程中,整个文件放在内存中进行处理,不涉及数据的内外存交换。 (适用于记录个数不是很多的小文件) 外排序:排序过程中要进行数据的内、外存交换。 (适用于记录个数多,不能将其一次性放入内存中的大文件)
思想:对排序记录的关键字进行两两比较,发现次序相反时则进行交换直至没有次序相反的记录。
主要排序方法:冒泡排序、选择排序
(1)算法描述:
冒泡排序是一种简单的排序,每次访问要排序的数组序列,一次比较相邻两个元素的大小,
若顺序错误就进行交换。(这个方法名的由来是小的元素慢慢“浮”在数组顶端,也可称为沉底(大的元素))
(2)算法的实现
a.比较相邻的两个元素大小,如果第一个大于第二个元素的大小就进行交换
b.对每一对相邻的元素都进行同样的操作,从第一对到最后一对,经过此步骤
最大的元素将是最后的元素。
c.针对所有的元素重复上述操作,除过最后一个。
d.重复a-c步骤,直至排序完成

1 /** 2 *@Description: 排序算法 3 *@Author: dyy 4 */ 5 public class Sort { 6 public static void main(String[] args) { 7 int [] arr = new int[]{4,2,1,6,3,6,0,-5,1,1}; 8 bubbleSort(arr); 9 //遍历打印排序后的数组 10 for(int i = 0; i < arr.length;i++){ 11 System.out.print(arr[i]+" "); 12 } 13 } 14 /** 15 *冒泡排序 16 * @date: 2018/8/15 11:27 17 */ 18 public static void bubbleSort(int[] array){ 19 //对数组进行临界判断 20 if(array==null||array.length==0){ 21 System.out.println("array is NULL"); 22 } 23 for(int i = 0; i < array.length - 1; i++){ 24 //进行相邻元素额大小比较(也可循环至array.length-1, 25 // 循环至array.length-i-1是因为没经过一圈的排序后面的元素则就是有序的) 26 for(int j = 0;j < array.length-i-1;j++){ 27 if(array[j]>array[j+1]){ 28 swap(array,j,j+1); 29 } 30 } 31 } 32 } 33 /** 34 *实现数组中两个数的交换 35 * target为要交换的数组,x,y为要交换数字的下标 36 * @date: 2018/8/15 11:30 37 */ 38 public static void swap(int[] target,int x,int y){ 39 int temp = target[x]; 40 target[x] = target[y]; 41 target[y] = temp; 42 } 43 }

(1)算法描述:选择排序是一种简单直观的排序算法。
它的工作原理是首先在未排序的序列中找到最大(小)的元素放置序列起始位置。
再从未排序序列中继续寻找元素放置已排序序列的尾部直至所有元素都有序。
(2)算法的实现:
a.初始状态:R[1……n]无序,有序数组为空
b.经过第i次扫描:R[1……i-1]有序,R[i……n]无序
c.经过n-1趟排序,为有序序列
1 /** 2 *选择排序 3 * @date: 2018/8/15 12:26 4 */ 5 public static void selectSort(int[] array){ 6 //临界条件判断 7 if(array==null||array.length==0){ 8 System.out.println("array is NULL"); 9 } 10 //做第i趟排序 11 for(int i = 0; i < array.length-1;i++){ 12 for(int j = i+1; j < array.length;j++){ 13 //选出最小的记录进行交换 14 if(array[i]>array[j]){ 15 swap(array,i,j); 16 } 17 } 18 } 19 }

(1)算法描述
插入排序也是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对已未排序
的序列的数据,在已经有序的序列中从后向前找并进行插入。但是在进行插入的过程中需
要不断的将已经排序好的数据进行移位操作。
(2)算法实现
a.从第一个数据开始,将该元素认为已经排序好的序列。
b.取出下一个元素,在已经排序好的元素序列中从后向前进行扫描。
c.如果该元素(排序好的元素)大于新的元素,则将该元素移动到下一个位置
d.重复步骤c,知道找到已排序好的元素小于或者等于新元素的位置
e.将新的元素插入到该位置
f.重复步骤b
1 /** 2 *插入排序 3 * @date: 2018/8/15 19:42 4 */ 5 public static void insertSort(int[] array){ 6 //临界条件判断 7 if(array==null||array.length==0){ 8 System.out.println("array is null"); 9 } 10 for(int i = 0; i < array.length;i++){ 11 //从下一个元素进行遍历,若新元素小于已经排序好的序列的元素进行交换 12 for(int j = i ;(j>0)&&(array[j-1]>array[j]);j--){ 13 swap(array,j-1,j); 14 } 15 } 16 }

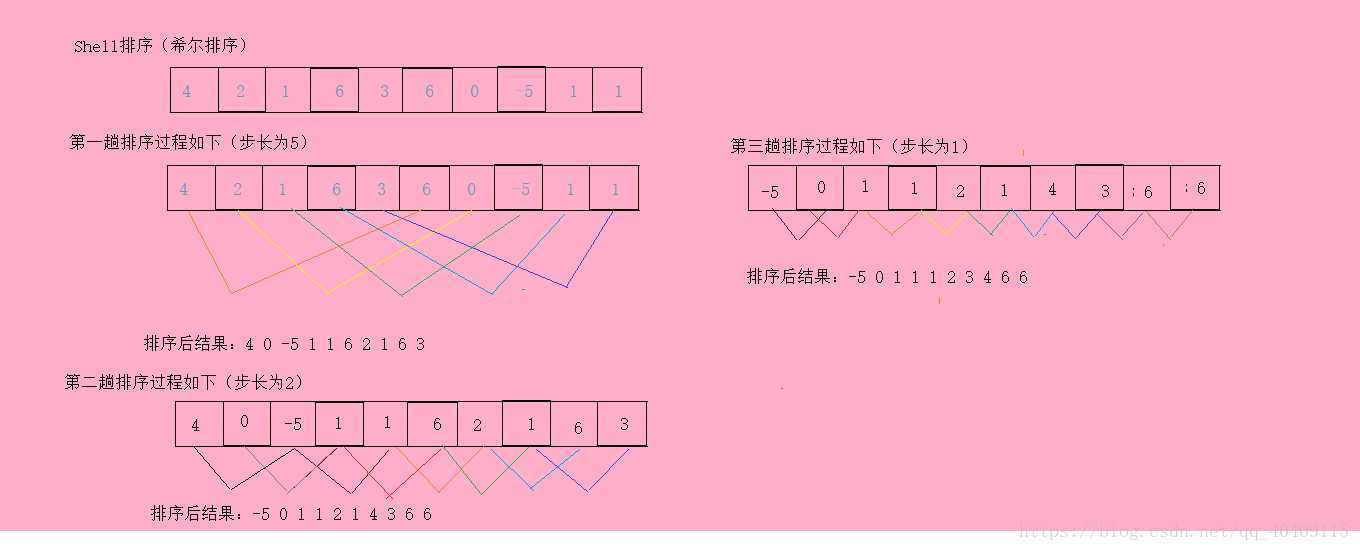
(1)算法描述 希尔排序是插入排序的一种,其中心思想是将数据进行分组,然后对每一组 数据进行排序,在每一组数据有序后,可以利用插入排序对所有分组进行最 后一次排序。这样可以减少数据交换的次数,加快排序速度。 (2)算法实现 a.选择一个增序序列t(1),t(2)……t(n),其中t(n)=1 b.按照增量序列个数k,对序列进行k此排序 c.每次排序,根据对应的增量,分为若干个长度为m的子序列,分别对子序列 进行插入排序。当增量为1时一个序列来进行处理,表长即为整个序列的长度。
1 /** 2 *Shell排序(希尔排序) 3 * @date: 2018/8/15 20:07 4 */ 5 public static void shellSort(int[] array){ 6 if(array==null||array.length==0){ 7 System.out.println("array is null"); 8 } 9 //分隔集合之间的长度(第一次假设为集合长度的一半) 10 int increment = 0; 11 //分隔集合之间的长度,每次为前一次的一半(最后一次为1) 12 for(increment = array.length/2;increment>0;increment = increment>>1){ 13 for(int i = increment;i<array.length;i++){ 14 for(int j = i - increment;j >= 0;j = j - increment){ 15 if(array[i] < array[j]){ 16 swap(array,i,j); 17 } 18 } 19 } 20 } 21 }
【排序算法】——冒泡排序、选择排序、插入排序、Shell排序等排序原理及Java实现
标签:text targe 假设 show new uda hid image inf
原文地址:https://www.cnblogs.com/edda/p/12594760.html
