标签:style blog http io color ar os 使用 sp
原文:《SQL Server企业级平台管理实践》读书笔记——SQL Server中收缩数据库不好用的原因数据库管理员有时候需要控制文件的大小,可能选择收缩文件,或者把某些数据文件情况以便从数据库里删除。
这时候我们就要使用到DBCC SHRINKFILE命令,此命令的脚本为:
DBCC SHRINKFILE ( { file_name | file_id } { [ , EMPTYFILE ] | [ [ , target_size ] [ , { NOTRUNCATE | TRUNCATEONLY } ] ] } ) [ WITH NO_INFOMSGS ]
由于DBCC SHRINKFILE一次运行会同时影响所有的文件(包括数据文件和日志文件),使用者不能指定每个文件的目标大小,其结果可能不能达到预期的要求。建议是做好规划,对每个文件确定预期目标,然后使用DBCC SHRINKFILE来一个文件一个文件的做比较妥当。
要注意一些几点:
1、首先要了解数据文件当前使用的使用情况。
收缩量的大小不可能超过当前文件的空闲空间的大小。如果想要压缩数据库的大小,首先就要确认数据文件的确有相应未被使用的空间。如果空间都在使用中,那就要先确认大量占用空间的对象,比如:表格或索引,然后通过归档历史数据,先把空间释放出来。
2、主数据文件(primary File)是不能被清空的。能被完全清空的是有辅助数据文件。
3、如果要把一个文件组整个清空,要删除分配在这个文件组上的对象(表格或索引),或者把它们移动到其它文件组上,DBCC SHRINKFILE不会帮你做这个工作。
把数据文件里面该删除的数据和对象清除完、确认数据文件(组)有足够的空闲空间后,管理员就可以下DBCC SHRINKFILE命令来缩小或清空指定文件了。如果是要缩小文件,就填写上要的tearget_size,如果要清空文件,就选择EmptyFile。SQL Server在做DBCC ShrinkFile的时候,会扫描数据文件并对正在读的页面加锁。所以对数据库的性能会有所影响。但是这不是一个独占的行为,也就是说在收缩的时候,其他用户照样可以对数据库进行读写访问。所以不需要单独安排服务器停机时间来做,一般在数据库维护的时候就可以进行。可以在进程中的任意点停止DBCC SHRINKFILE操作,任何已完成的工作都会保留。如果操作没有在规定的时间内完成,也可以完全的停止它。
可是,有时候明明看到数据文件里有空间,为什么就是不能压缩或者情况它呢?这通常是因为数据文件里面虽然有很多空的页面,但是这些页面分散在各个区里,使得整个文件没有很多空的区。
需要说明的是,DBCC SHRINKFILE做的,都是区一级的动作。它会把使用过的区前移,把没有使用中的区从文件中移除。但是,它不会把一个区里面的空页面移除、合并区,也不会在页面里面的空间移除、合并页面。所以,一个数据库中有很多只使用了一两个页面的区,DBCC SHRINKFILE的效果会不明显。
下面的案例来展示这个过程:
我们新建一个每一行都会占用一个页面的表格。表上没有聚集索引,所以是一个堆表。往里面插入8000条数据:
create table show_extent ( a int, b nvarchar(3900) ) go declare @i int set @i=1 while @i<=1000 begin insert into show_extent values(1,replicate(N‘a‘,3900)) insert into show_extent values(2,replicate(N‘b‘,3900)) insert into show_extent values(3,replicate(N‘c‘,3900)) insert into show_extent values(4,replicate(N‘d‘,3900)) insert into show_extent values(5,replicate(N‘e‘,3900)) insert into show_extent values(6,replicate(N‘f‘,3900)) insert into show_extent values(7,replicate(N‘g‘,3900)) insert into show_extent values(8,replicate(N‘h‘,3900)) set @i=@i+1 end dbcc showcontig(‘show_extent‘) go
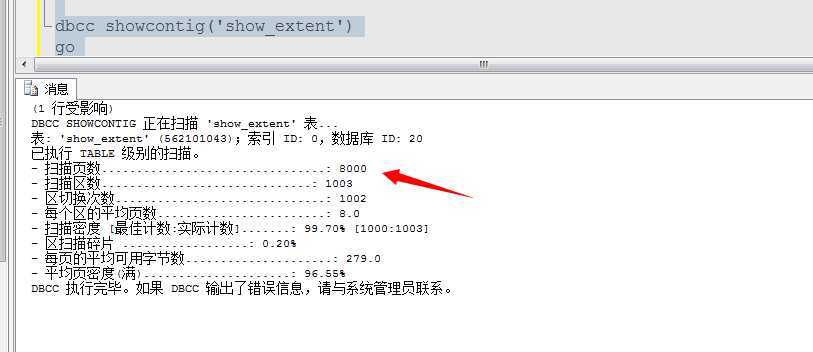
可以看到这个表有1003个区,然后平均每个区里面有8个页面,共计8000个页面...当然这里面包含区碎片所以多处了3个区,24个页的冗余
我们下面删除一部分数据,只保留a=5的这些个记录,来对比前后的空间大小
sp_spaceused show_extent go delete show_extent where a<>5 go sp_spaceused show_extent go dbcc showcontig(‘show_extent‘) go
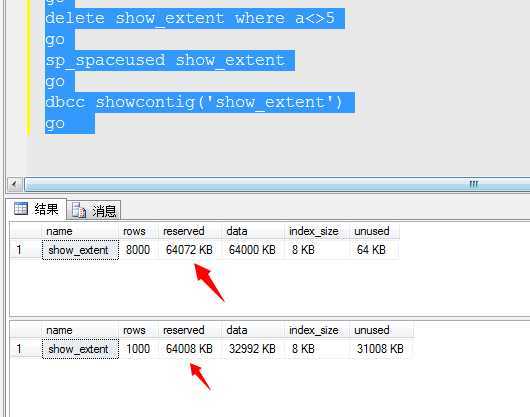
可以看到...删除之后的页面空间是没有释放的。只是缩小了一点点。
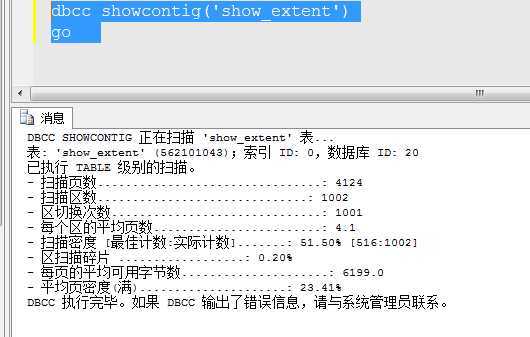
区没有变化,页数减少了才一半左右,也就是说每个区平均现在只有4.1个页面,在这种情况下去收缩数据库是没有效果的。
我们下面收缩一些看看效果
DBCC SHRINKFILE(1,40)
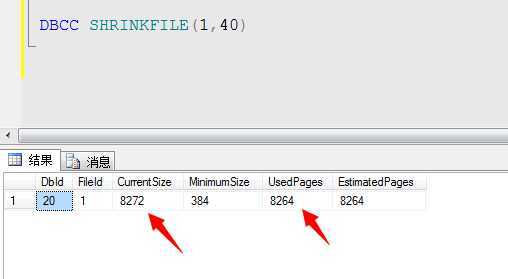
可以看到页数不但没有减少,而且增加了..这地方的原因是它按照逻辑分区计算的:1002*8约等于8016..
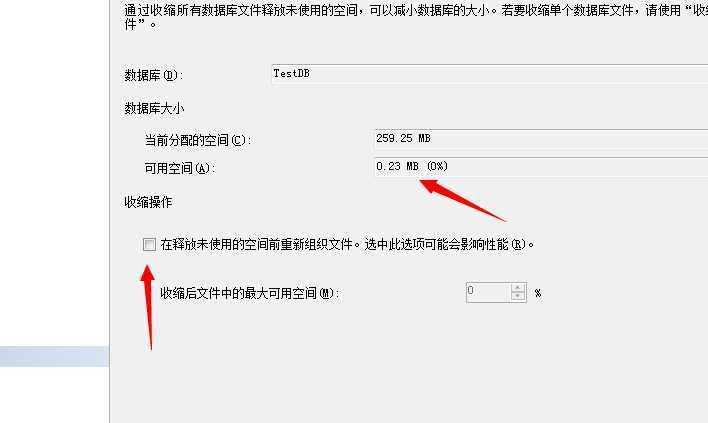
可以看到能够收缩的空间很少很少..而且给出了一个好的解决方法就是:重新组织页,但是这样会影响性能,也就是说这样它会重新组织页,填充页。
当然我们这里还有另外一个解决方案,通过重建索引的方式把页面重新排列一次。现在还没有聚集索引,我们给他新建一个
create clustered index show_I on show_extent(a) go dbcc showcontig(‘show_extent‘)
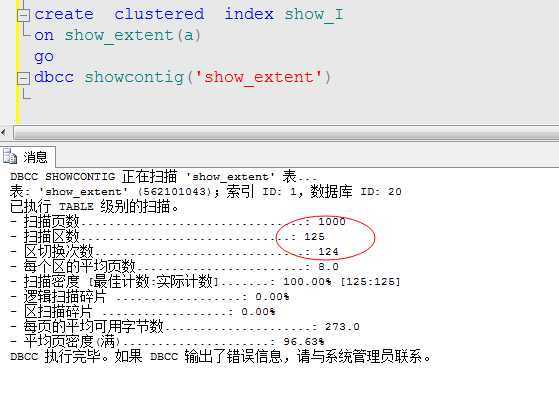
可以看到...立马缩减到1000页,125个区,我们来看看能收缩多少数据。
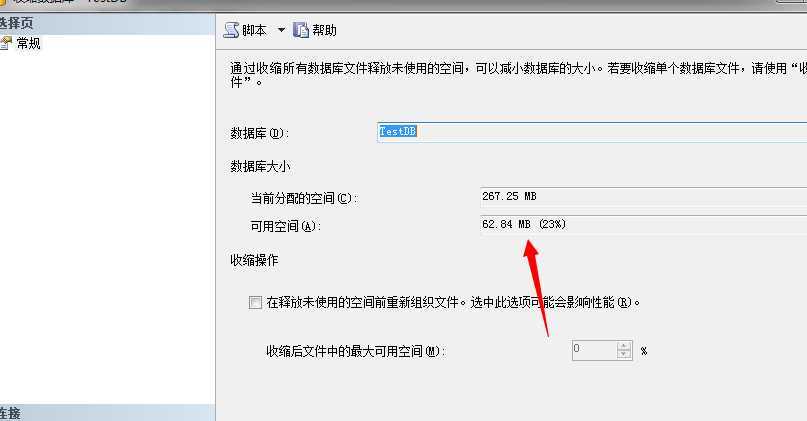
现在可以看到了可以收缩的百分比了。我们来执行收缩数据操作
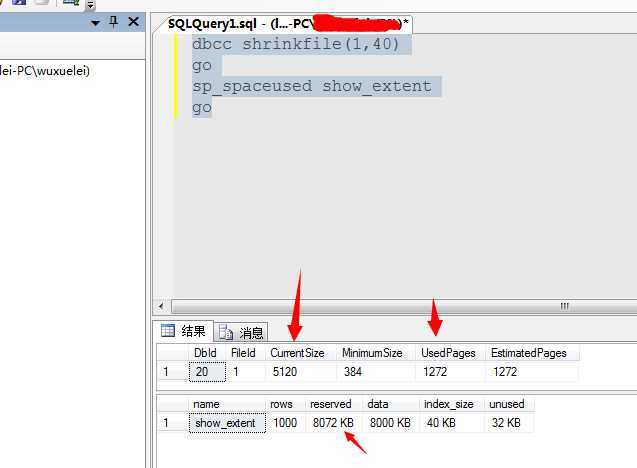
可以看到我们已经将数据收缩至5120,说明此时收缩数据已经产生了作用。
如果不想建立聚集索引,可以把这张表的数据先移走,然后清空表格,再把数据插回来。当然这样比较麻烦,还是有聚集索引管理起来比较方便。
刚才谈到了造成Shrinkfile效果不佳的情况。在一个有聚集索引的的表格上,可以通过重建建立聚集索引来解决。但是如果区里面存放的是text或者image之类的数据类型,SQL Server会单独的页面来存放这些数据。如果这类存储页面也发生同样的问题,和堆一样,做索引重建也不会影响到他们。
对于这种对象的处理方式,就是把这些可能有问题的对象都找出来,然后重新建立他们。可以利用DBCC Extentinfo这个命令打出数据文件里面的所有区的分配信息。然后计算每个对象理论上区的数目和实际数目。如果实际数目远大于理论的数目。那这个对象就是存在多于的碎片,需我们考虑重建对象了。
我们下面来看一个例子:
if exists(select name from sysobjects where NAME =‘extentinfo‘ and type=‘U‘) drop table extentinfo go create table extentinfo ( [file_id] smallint, page_id int, pg_alloc int, ext_size int, obj_id int, index_id int, partition_number int, partition_id bigint, iam_chain_type varchar(50), pfs_bytes varbinary(10) ) go if exists(select name from sysobjects where NAME =‘import_extentinfo‘ and type=‘P‘) drop procedure import_extentinfo go create procedure import_extentinfo as dbcc extentinfo(‘TestDB‘) go insert extentinfo exec import_extentinfo go select name as table_name, [file_id],obj_id, index_id, partition_id, ext_size, ‘actual page count‘=sum(pg_alloc), ‘actual extent count‘=count(*), ‘expected extent count‘=ceiling(sum(pg_alloc)*1.0/ext_size), --一个对象的所有盘区页数的各总和/ ‘expected extents / actual extents‘ = (ceiling(sum(pg_alloc)*1.00/ext_size)*100.00) / count(*) from extentinfo inner join sysobjects on obj_id=id group by [file_id],obj_id, index_id,partition_id, ext_size ,name having count(*)-ceiling(sum(pg_alloc)*1.0/ext_size) > 0 order by partition_id, obj_id, index_id, [file_id]
这里我们通过DBCC extentinfo命令来查看数据库中的区明细,然后查看理论值和实际值的差距,如果存在大量的碎片,我们就需要进行重建清理了。
DBCC EXTENTINFO命令用于查询某个数据库、或者某个数据对象(主要是数据表)的盘区分配情况。其语法结构如下:
DBCC
EXTENTINFO(dbname,tablename,indexid)
我们给出这个命令显示行的明细:
|
字段名称 |
说 明 |
|
file_id |
数据库的数据文件编号 |
|
page_id |
在某个盘区中的第一个页面的页面号 |
|
字段名称 |
说 明 |
|
pg_alloc |
该盘区为数据库分配的页面数量m(1≤m≤8) |
|
ext_size |
盘区的大小,以页面为单位 |
|
object_id |
数据库对象的ID |
|
index_id |
表示数据对象的类型 |
|
partition_number |
分区号 |
|
rows |
大约的数据行数 |
|
hobt_id |
存储数据的堆或B树的存储单元ID |
我们来找个数据库看一下存在碎片的情况:
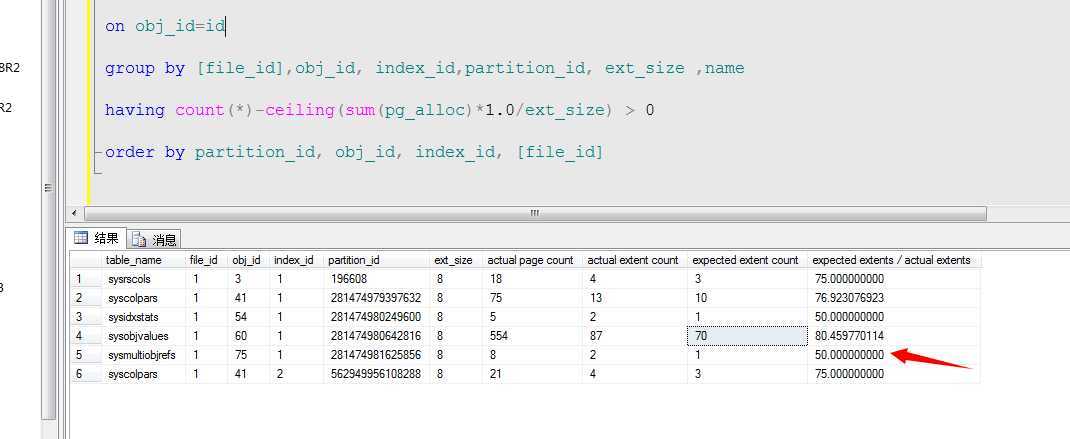
可以看到上图中,箭头所指的这个行数据,理论应该为一个区就可以,但是实际上它建立了两个分区...所以这种情况可以考虑整理碎片,进行重建,释放碎片。
《SQL Server企业级平台管理实践》读书笔记——SQL Server中收缩数据库不好用的原因
标签:style blog http io color ar os 使用 sp
原文地址:http://www.cnblogs.com/lonelyxmas/p/4076659.html