标签:des style blog http io color ar os 使用
转载来自:http://www.cnblogs.com/spark-china/p/3941878.html
-
在VMWare 中准备第二、第三台运行Ubuntu系统的机器;
在VMWare中构建第二、三台运行Ubuntu的机器和构建第一台机器完全一样,再次不在赘述。。
与安装第一台Ubuntu机器不同的几点是:
第一点:我们把第二、三台Ubuntu机器命名为了Slave1、Slave2,如下图所示:
创建完的VMware中就有三台虚拟机了:
第二点:为了简化Hadoop的配置,保持最小化的Hadoop集群,在构建第二、三台机器的时候使用相同的root超级用户的方式登录系统。
2.按照配置伪分布式模式的方式配置新创建运行Ubuntu系统的机器;
按照配置伪分布式模式的方式配置新创建运行Ubuntu系统的机器和配置第一台机器完全相同,
下图是家林完全安装好后的截图:
3. 配置Hadoop分布式集群环境;
根据前面的配置,我们现在已经有三台运行在VMware中装有Ubuntu系统的机器,分别是:Master、Slave1、Slave2;
下面开始配置Hadoop分布式集群环境:
Step 1:在/etc/hostname中修改主机名并在/etc/hosts中配置主机名和IP地址的对应关系:
我们把Master这台机器作为Hadoop的主节点,首先看一下Master这台机器的IP地址:
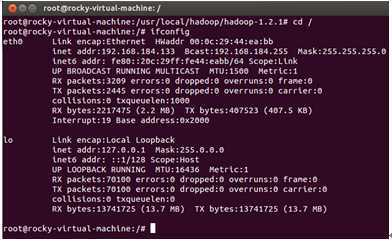
可以看到当前主机的ip地址是“192.168.184.133”.
我们在/etc/hostname中修改主机名:

进入配置文件:
可以看到按照我们装Ubuntu系统时候的默认名称,配置文件中的机器的名称是” rocky-virtual-machine”,我们把” rocky-virtual-machine”改为“Master”作为Hadoop分布式集群环境的主节点:
保存退出。此时使用以下命令查看当前主机的主机名:
发现修改的主机名没有生效,为使得新修改的主机名生效,我们重新启动系统后再次查看主机名:

发现我们的主机名成为了修改后的“Master”,表明修改成功。
打开在/etc/hosts 文件:

此时我们发现文件中只有Ubuntu系统的原始ip(127.0.0.1)地址和主机名(localhost)的对应关系:
我们在/etc/hosts中配置主机名和IP地址的对应关系:
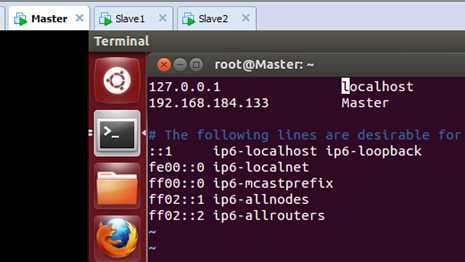
修改之后保存退出。
接下来我们使用“ping”命令看一下主机名和IP地址只见的转换关系是否正确:
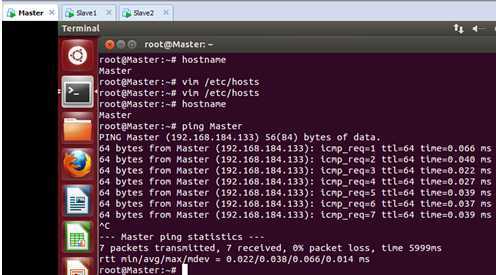
可以看到此时我们的主机“Master”对应的IP地址是“192.168.184.133”,这表明我们的配置和运行都是正确的。
进入第二台机器,看一下这台主机的IP地址:
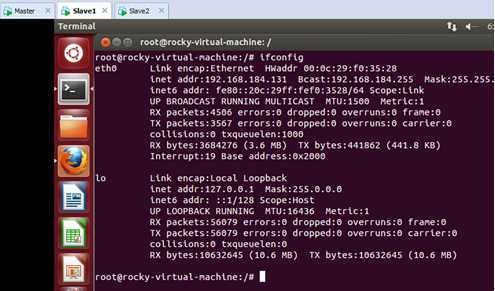
可以看出这台主机的IP地址是“192.168.184.131”.
我们在/etc/hostname中把主机名称修改为“Slave1”:
保存退出。
为了使修改生效,我们重新启动该机器,此时查看主机名:
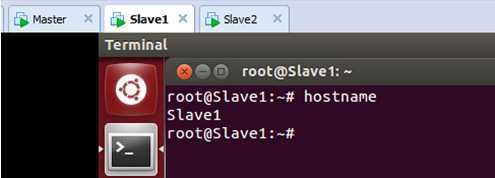
表明我们的修改生效了。
进入第三台机器,看一下这台主机的IP地址:
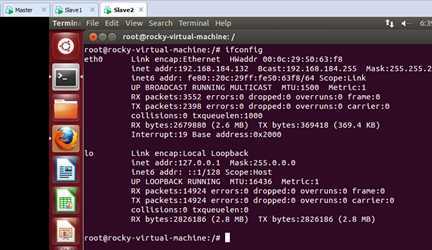
可以看出这台主机的IP地址是“192.168.184.132”.
我们在/etc/hostname中把主机名称修改为“Slave2”:
保存退出。
为了使修改生效,我们重新启动该机器,此时查看主机名:
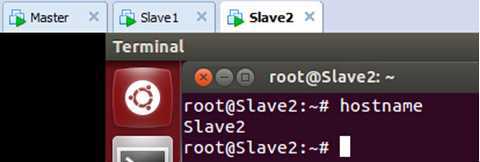
表明我们的修改生效了。
现在, Slave1上的/etc/hosts中配置主机名和IP地址的对应关系,打开后:
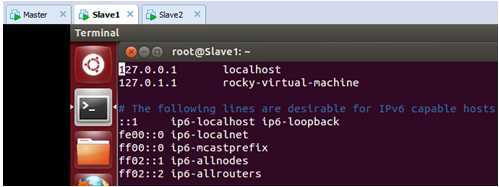
此时我们修改为配置文件为:
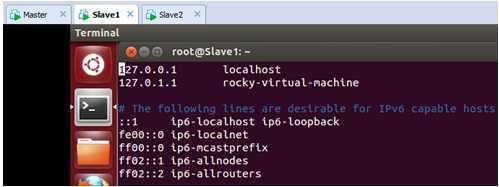
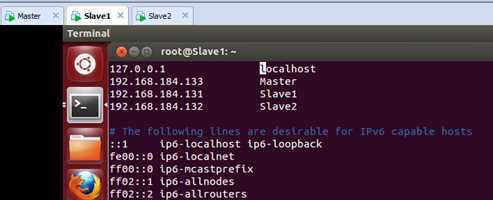
把“Master”和“Slave1”和“Slave2”的主机名和IP地址的对应关系都配置进去。保存退出。
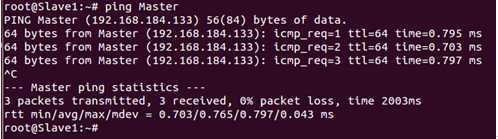
我们此时ping一下Master这个节点发现网络访问没有问题:
接着,在 Slave2上的/etc/hosts中配置主机名和IP地址的对应关系,配置完后如下:
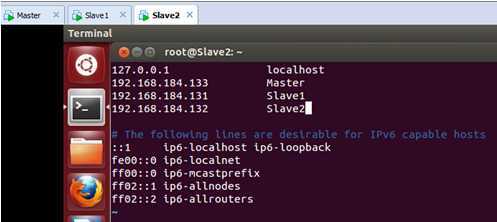
保存退出。
此时我们ping一下Master和Slave1发现都可以ping通;
最后把在 Master上的/etc/hosts中配置主机名和IP地址的对应关系,配置完后如下:
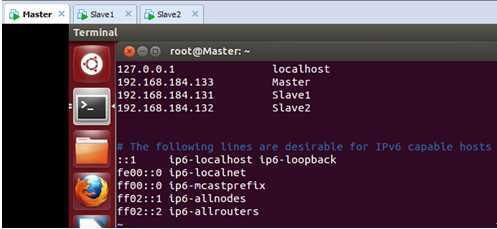
此时在Master上使用ping命令和Slave1和Slave2这两台机器进行沟通:
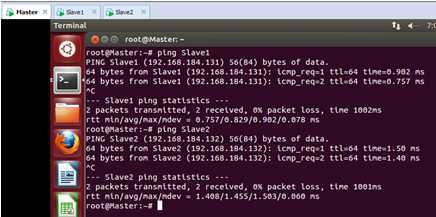
发现此时已经ping通了两个slave节点的机器。
最后我们在测试一下Slave1这台机器和Master、Slave2的通信:
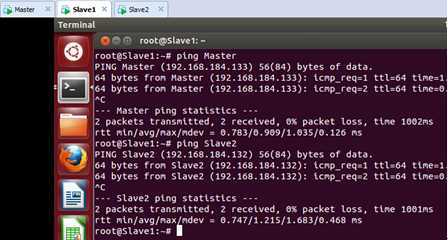
到目前为止,Master、Slave1、Slave2这三台机器之间实现了相互通信!
Step 2:SSH无密码验证配置
首先我们看一下在没有配置的情况下Master通过SSH协议访问Slave1的情况:
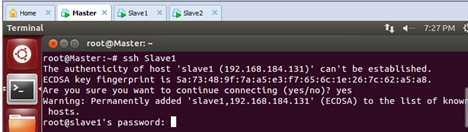
此时会发现我们是需要密码的。我们不登陆进去,直接退出。
怎么使得集群能够通过SSH免登陆密码呢?
按照前面的配置,我们已经分布在Master、Slave1、Slave2这三台机器上的/root/.ssh/目录下生成一个私钥id_rsa和一个公钥id_rsa.pub。
此时把Slave1的id_rsa.pub传给Master,如下所示:
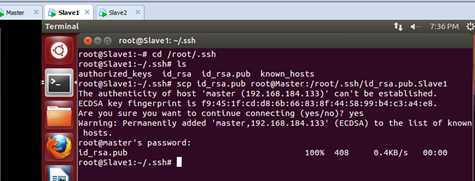
同时把Slave2的id_rsa.pub传给Master,如下所示:
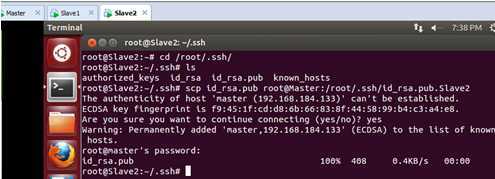
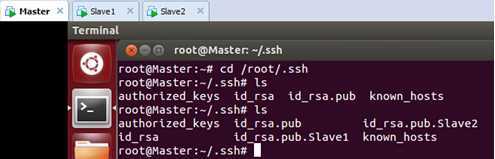
在Master上检查一下是否复制了过来:
此时我们发现Slave1和Slave2节点的公钥已经传输过来
Master节点上综合所有公钥:

将Master的公钥信息authorized_keys复制到Slave1和Slave1的.ssh目录下:
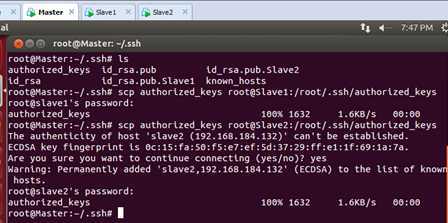
此时再次通过SSH登录Slave1和Slave2:
此时Master通过SSH登录Slave1和Slave2已经不需要密码,同样的Slave1或者Slave2通过SSH协议登录另外两台机器也不需要密码了。
Step 3:修改Master、Slave1、Slave2的配置文件
首先修改Master的core-site.xml文件,此时的文件内容是:
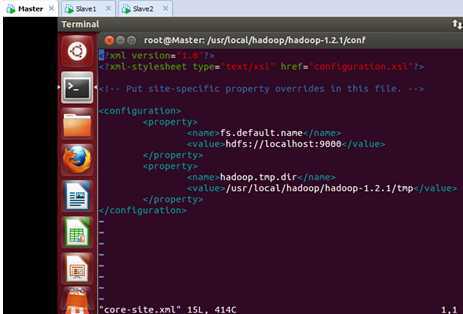
我们把“localhost”域名修改为“Master”:
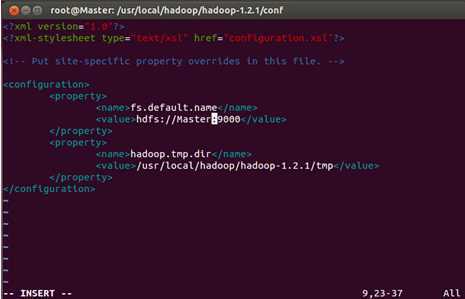
同样的操作分别打开Slave1和Slave2节点core-site.xml,把“localhost”域名修改为“Master”。
其次修改Master、Slave1、Slave2的mapred-site.xml文件.
进入Master节点的mapred-site.xml文件把“localhost”域名修改为“Master”,保存退出。
同理,打开Slave1和Slave2节点mapred-site.xml,把“localhost”域名修改为“Master”,保存退出。
最后修改Master、Slave1、Slave2的hdfs-site.xml文件:
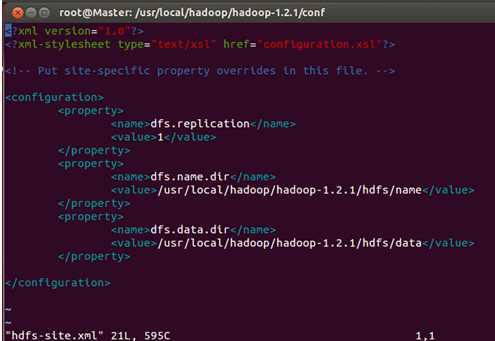
我们把三台机器上的“dfs.replication”值由1改为3,这样我们的数据就会有3份副本:
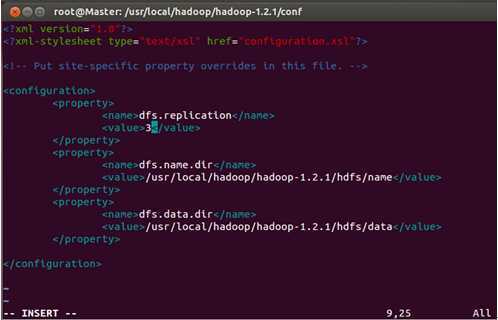
保存退出。
Step 4:修改两台机器中hadoop配置文件的masters和slaves文件
首先修改Master的masters文件:

进入文件:

把“localhost”改为“Master”:

保存退出。
修改Master的slaves文件,

进入该文件:

具体修改为:
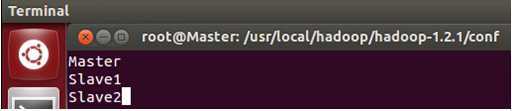
保存退出。
从上面的配置可以看出我们把Master即作为主节点,又作为数据处理节点,这是考虑我们数据的3份副本而而我们的机器台数有限所致。
把Master配置的masters和slaves文件分别拷贝到Slave1和Slave2的Hadoop安装目录下的conf文件夹下:
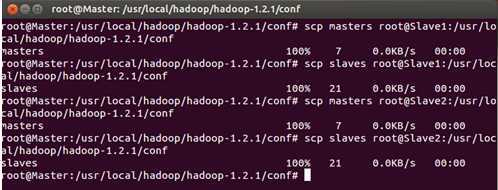
进入Slave1或者Slave2节点检查masters和slaves文件的内容:

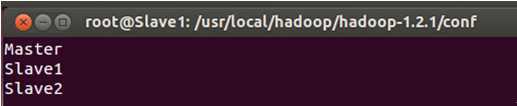
发现拷贝完全正确。
至此Hadoop的集群环境终于配置完成!
4.测试Hadoop分布式集群环境;
首先在通过Master节点格式化集群的文件系统:
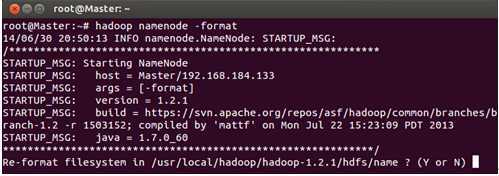
输入“Y”完成格式化:
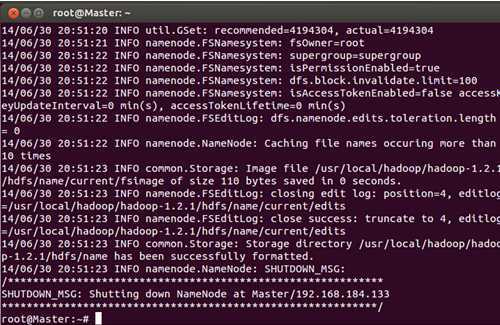
格式化完成以后,我们启动hadoop集群:
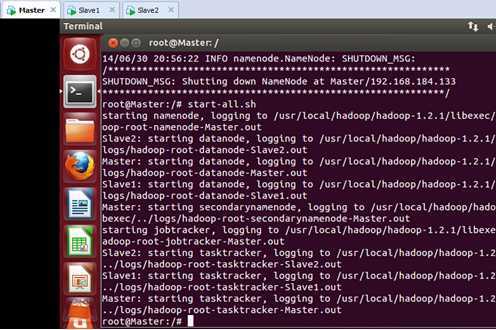
我们在尝试一下停止Hadoop集群:
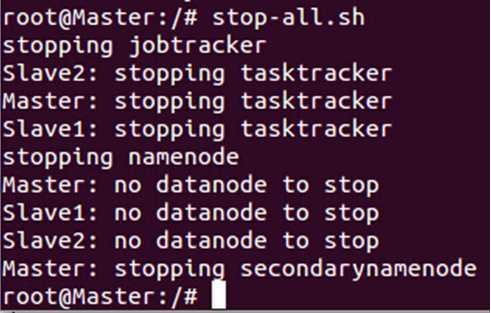
此时出现了“no datanode to stop”的错误,出现这种错误的原因如下:
每次使用 “hadoop namenode -format”命令格式化文件系统的时候会出现一个新的namenodeId,而我我们在搭建Hadoop单机伪分布式版本的时候往我们自己创建的tmp目录下放了数据,现在需要把各台机器上的“/usr/local/hadoop/hadoop-1.2.1/”下面的tmp及其子目录的内容清空,于此同时把“/tmp”目录下的与hadoop相关的内容都清空,最后要把我们自定义的hdfs文件夹中的data和name文件夹中的内容清空:

把Slave1和Slave2中同样的内容均删除掉。
重新格式化并重新启动集群,此时进入Master的Web控制台:
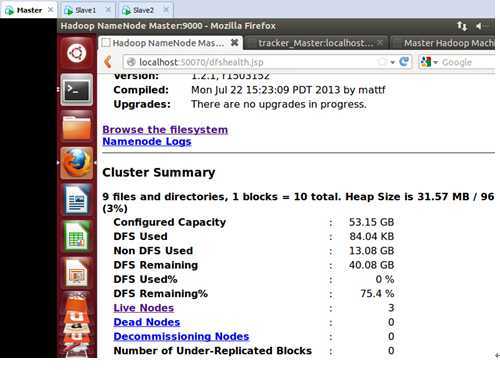
此时可以看到Live Nodes只有三个,这正是我们预期的,因为我们Master、Slave1、Slave2都设置成为了DataNode,当然Master本身同时也是NameNode。
此时我们通过JPS命令查看一下三台机器中的进程信息:
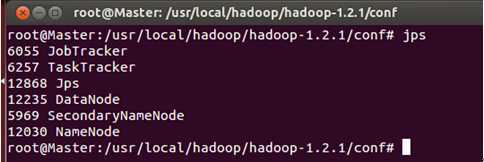
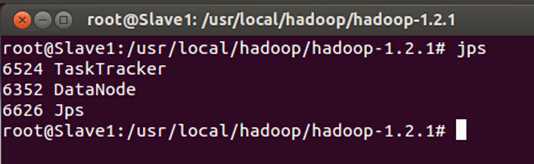
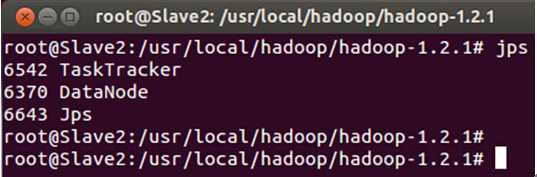
发现Hadoop集群的各种服务都正常启动。
至此,Hadoop集群构建完毕。
在1、2讲的从零起步构建好的Hadoop集群的基础上构建Spark集群,我们这里采用2014年5月30日发布的Spark 1.0.0版本,也就是Spark的最新版本,要想基于Spark 1.0.0构建Spark集群,需要的软件如下:
1.Spark 1.0.0,笔者这里使用的是spark-1.0.0-bin-hadoop1.tgz, 具体的下载地址是http://d3kbcqa49mib13.cloudfront.net/spark-1.0.0-bin-hadoop1.tgz
如下图所示:
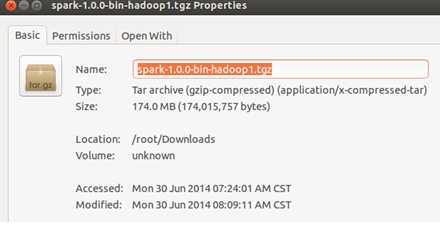
笔者是保存在了Master节点如下图所示的位置:
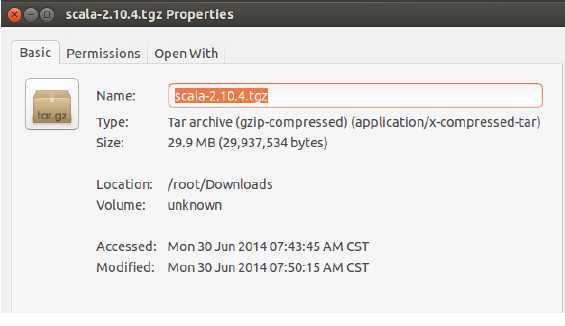
2.下载和Spark 1.0.0对应的Scala版本,官方要求的是Scala必须为Scala 2.10.x:
笔者下载的是“Scala 2.10.4”,具体官方下载地址为http://www.scala-lang.org/download/2.10.4.html 下载后在Master节点上保存为:
第二步:安装每个软件
安装Scala
- 打开终端,建立新目录“/usr/lib/scala”,如下图所示:
2.解压Scala文件,如下图所示:
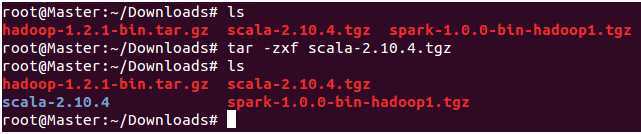
把解压好的Scala移到刚刚创建的“/usr/lib/scala”中,如下图所示

3.修改环境变量:

进入如下图所示的配置文件中:
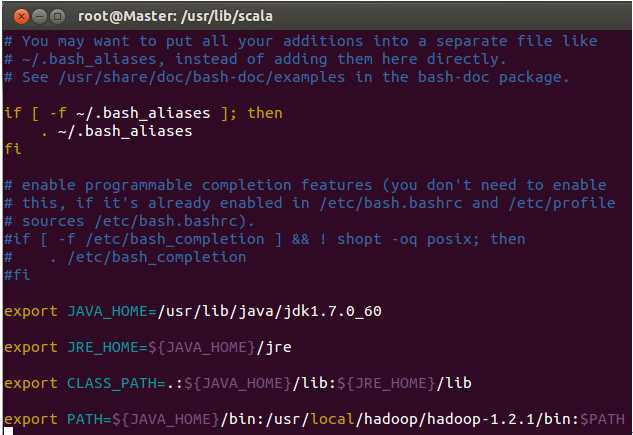
按下“i”进入INSERT模式,把Scala的环境编写信息加入其中,如下图所示:
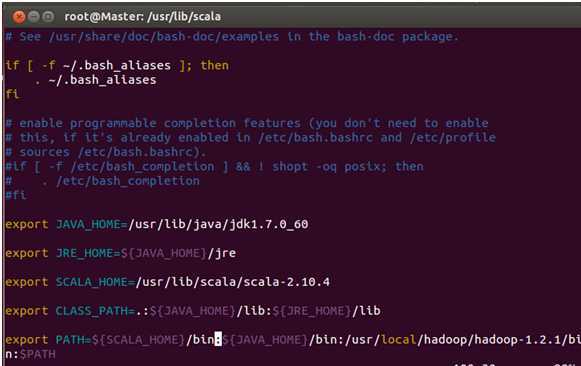
从配置文件中可以看出,我们设置了“SCALA_HOME”并把Scala的bin目录设置到了PATH中。
按下“esc“键回到正常模式,保存并退出配置文件:
执行以下命令是配置文件的修改生效:

4.在终端中显示刚刚安装的Scala版本,如下图所示

发现版本是”2.10.4”,这正是我们期望的。
当我们输入“scala”这个命令的的时候,可以直接进入Scala的命令行交互界面:

此时我们输入“9*9”这个表达式:
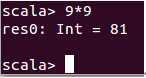
此时我们发现Scala正确的帮我们计算出了结果 。
此时我们完成了Master上Scala的安装;
由于我们的 Spark要运行在Master、Slave1、Slave2三台机器上,此时我们需要在Slave1和Slave2上安装同样的Scala,使用scp命令把Scala安装目录和“~/.bashrc”都复制到Slave1和Slave2相同的目录之之下,当然,你也可以按照Master节点的方式手动在Slave1和Slave2上安装。
在Slave1上Scala安装好后的测试效果如下:
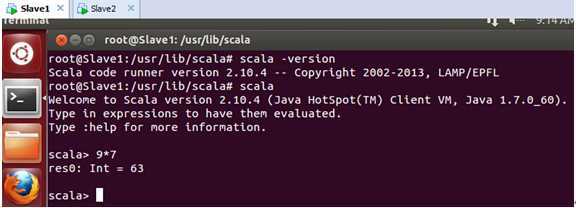
在Slave2上Scala安装好后的测试效果如下:
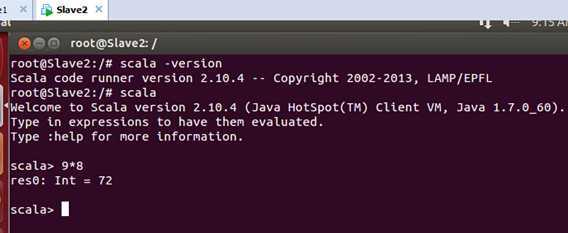
至此,我们在Master、Slave1、Slave2这三台机器上成功部署Scala。
安装Spark
Master、Slave1、Slave2这三台机器上均需要安装Spark。
首先在Master上安装Spark,具体步骤如下:
第一步:把Master上的Spark解压:
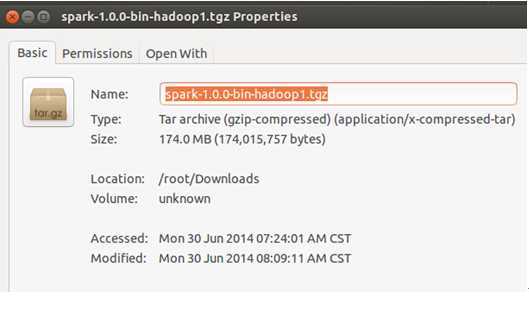
我们直接解压到当前目录下:
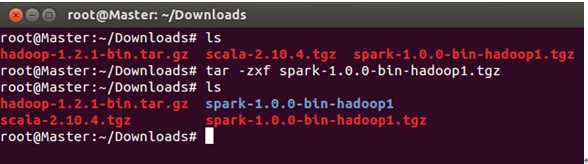
此时,我们创建Spark的目录“/usr/local/spark”:

把解压后的“spark-1.0.0-bin-hadoop1”复制到/usr/local/spark”下面:

第二步:配置环境变量
进入配置文件:

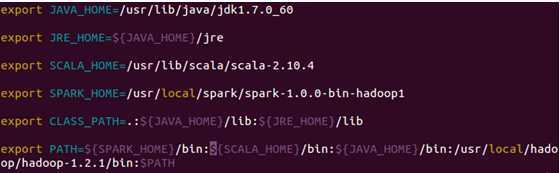
在配置文件中加入“SPARK_HOME”并把spark的bin目录加到PATH中:
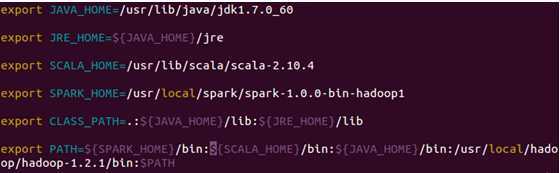
配置后保存退出,然后使配置生效:
第三步:配置Spark
进入Spark的conf目录:
在配置文件中加入“SPARK_HOME”并把spark的bin目录加到PATH中:
把spark-env.sh.template 拷贝到spark-env.sh:
使用vim打开spark-env.sh:
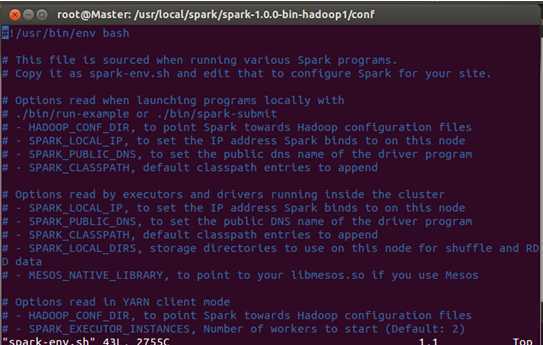
在配置文件中添加如下配置信息:

其中:
JAVA_HOME:指定的是Java的安装目录;
SCALA_HOME:指定的是Scala的安装目录;
SPARK_MASTER_IP:指定的是Spark集群的Master节点的IP地址;
SPARK_WORKER_MEMOERY:指定的Worker节点能够最大分配给Excutors的内存大小,因为我们的三台机器配置都是2g,为了最充分的使用内存,这里设置为了2g;
HADOOP_CONF_DIR:指定的是我们原来的Hadoop集群的配置文件的目录;
保存退出。
接下来配置Spark的conf下的slaves文件,把Worker节点都添加进去:

打开后文件的内容:

我们需要把内容修改为:
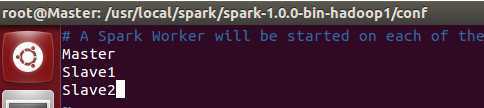
可以看出我们把三台机器都设置为了Worker节点,也就是我们的主节点即是Master又是Worker节点。
保存退出。
上述就是Master上的Spark的安装。
启动并查看集群的状况
第一步:启动Hadoop集群,这个在第二讲中讲解的非常细致,在此不再赘述:
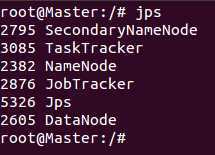
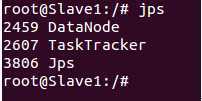
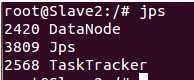
启动之后在Master这台机器上使用jps命令,可以看到如下进程信息:
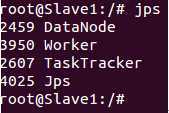
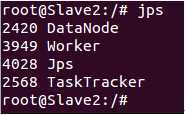
在Slave1 和Slave2上使用jps会看到如下进程信息:
第二步:启动Spark集群
在Hadoop集群成功启动的基础上,启动Spark集群需要使用Spark的sbin目录下“start-all.sh”:
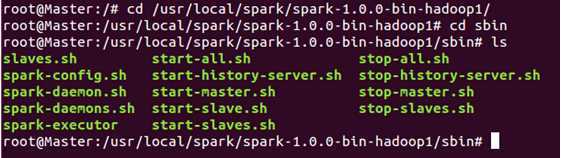
接下来使用“start-all.sh”来启动Spark集群!
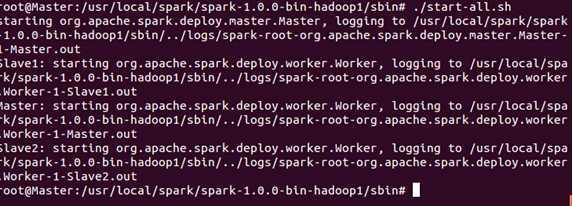
读者必须注意的是此时必须写成“./start-all.sh”来表明是当前目录下的“start-all.sh”,因为我们在配置Hadoop的bin目录中也有一个“start-all.sh”文件!
此时使用jps发现我们在主节点正如预期一样出现了“Master”和“Worker”两个新进程!
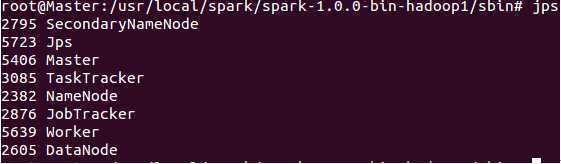
此时的Slave1和Slave2会出现新的进程“Worker”:
此时,我们可以进入Spark集群的Web页面,访问“http://Master:8080”: 如下所示:
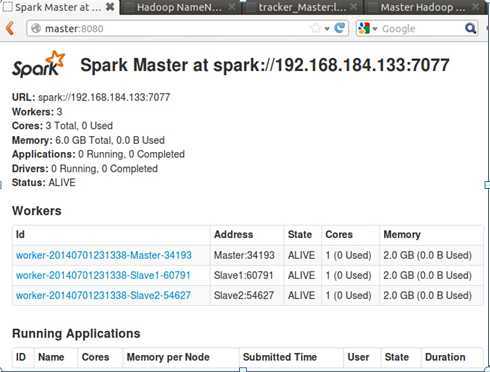
从页面上我们可以看到我们有三个Worker节点及这三个节点的信息。
此时,我们进入Spark的bin目录,使用“spark-shell”控制台:
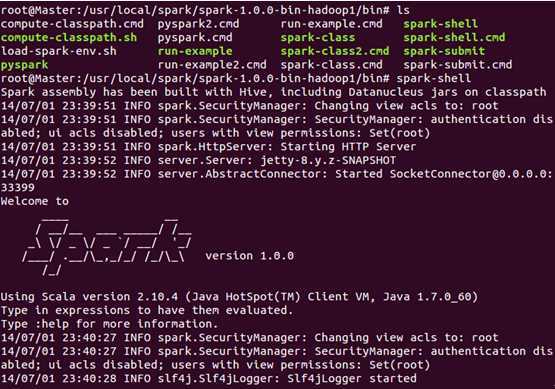
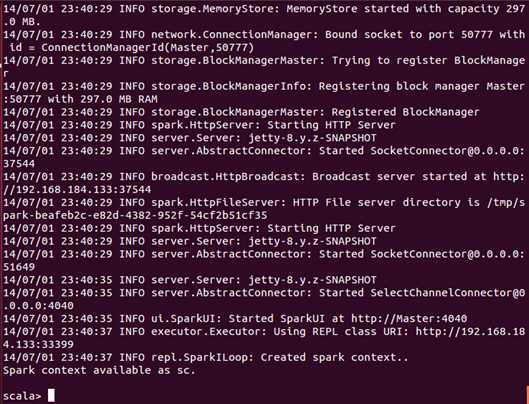
此时我们进入了Spark的shell世界,根据输出的提示信息,我们可以通过“http://Master:4040” 从Web的角度看一下SparkUI的情况,如下图所示:
当然,你也可以查看一些其它的信息,例如Environment:
同时,我们也可以看一下Executors:
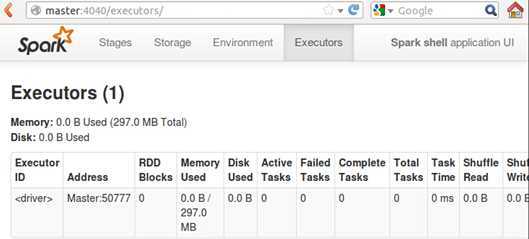
可以看到对于我们的shell而言,Driver是Master:50777.
至此,我们 的Spark集群搭建成功,Congratulations!
第一步:通过Spark的shell测试Spark的工作
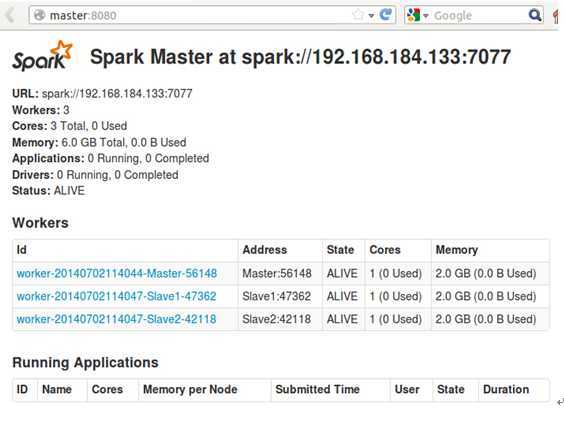
Step1:启动Spark集群,这一点在第三讲讲的极为细致,启动后的WebUI如下:
Step2:启动Spark Shell:
此时可以通过如下Web控制台查看shell的情况:
Step3:把Spark安装目录“README.md”拷贝到HDFS系统上
在Master节点上新启动一个命令终端,并进入到Spark安装目录下:

我们把文件拷贝到HDFS的root文件夹下:

此时,我们观察一下Web控制台,会发现该文件已经成功上传到HDFS上:
Step4:在Spark shell之下操作编写代码,操作我们上传的“README.md”:
首先,我们看一下在Shell环境下的“sc”这个自动帮助我们生产的环境变量:

可以看出sc就是SparkContext的实例,这是在启动Spark Shell的时候系统帮助我们自动生成的,SparkContext是把代码提交到集群或者本地的通道,我们编写Spark代码,无论是要运行本地还是集群都必须有SparkContext的实例。
接下来,我们读取“README.md”这个文件:
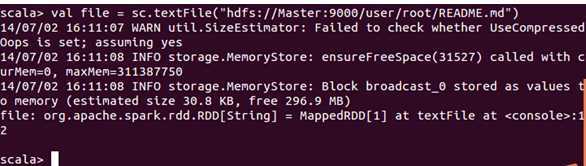
我们把读取的内容保存给了file这个变量,其实file是一个MappedRDD,在Spark的代码编写中,一切都是基于RDD操作的;
再接下来,我们从读取的文件中过滤出所有的“Spark”这个词

此时生成了一个FilteredRDD;
再接下来,我们统计一下“Spark”一共出现了多少次:
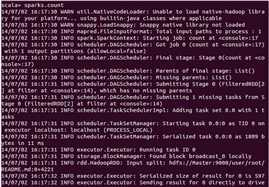
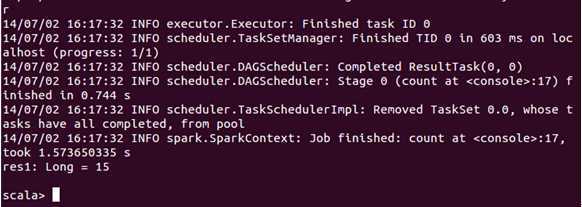
从执行结果中我们发现“Spark”这个词一共出现了15次。
此时,我们查看Spark Shell的Web控制台:

发现控制台中显示我们提交了一个任务并成功完成,点击任务可以看到其执行详情:
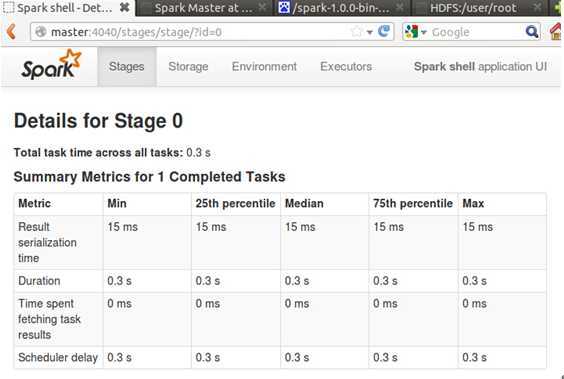
那我们如何验证Spark Shell对README.md这个文件中的“Spark”出现的15次是正确的呢?其实方法很简单,我们可以使用Ubuntu自带的wc命令来统计,如下所示:

发现此时的执行结果也是15次,和Spark Shell的计数是一样一样的。
第二步:使用Spark的cache机制观察一下效率的提升
基于上面的内容,我们在执行一下以下语句:
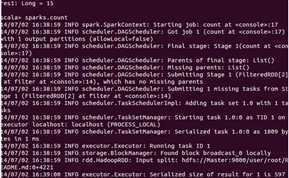
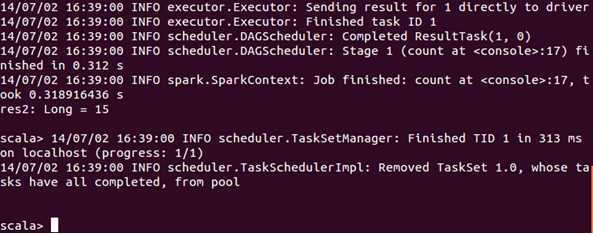
发现同样计算结果是15.
此时我们在进入Web控制台:
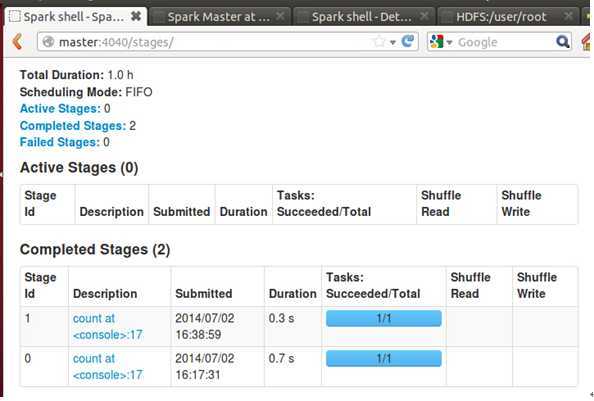
发现控制台中清晰展示我们执行了两次“count”操作。
现在我们把“sparks”这个变量执行一下“cache”操作:

此时在执行count操作,查看Web控制台:
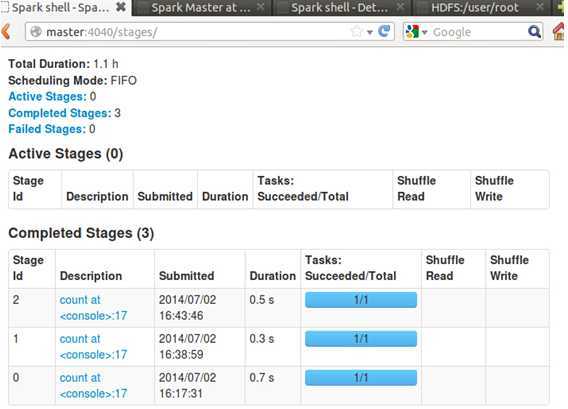
此时发现我们前后执行的三次count操作耗时分别是0.7s、0.3s、0.5s。
此时我们 第四次执行count操作,看一下Web控制台的效果:
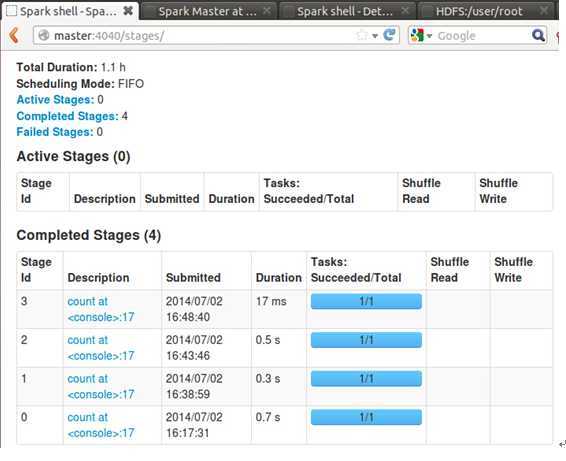
控制台上清晰的第四次操作仅仅花费了17ms,比前三次的操作速度大约快了30倍的样子。这就是缓存带来的巨大速度提升,而基于缓存是Spark的计算的核心之一!
第三步:构建Spark的IDE开发环境
Step 1:目前世界上Spark首选的InteIIiJ IDE开发工具是IDEA,我们下载InteIIiJ IDEA:
这里下载是最新版本Version 13.1.4:
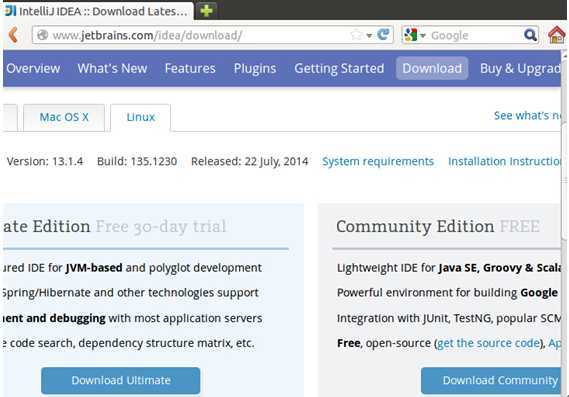
关于版本的选择,官方给出了如下选择依据:
我们在这里选择Linux系统下的”Community Edition FREE”这个版本,这能完全满足我们任意复杂程度的Scala开发需求。
家林下载完成后保存在本地的如下位置:
Step 2:安装IDEA并配置IDEA系统环境变量
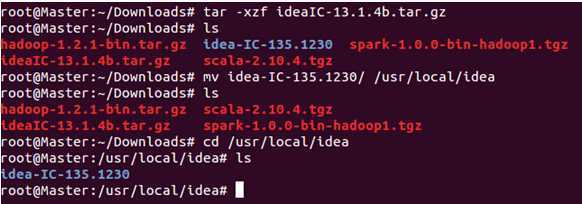
创建“/usr/local/idea”目录:
把我们下载的idea压缩包解压到该目录下:
安装完成后,为了方便使用其bin目录下的命令,我们把它配置在“~/.bashrc”:
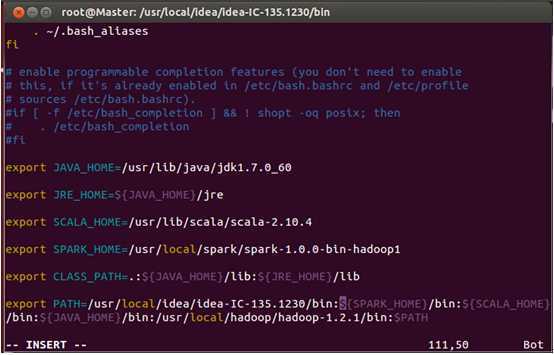
配置完成后保存退出并执行source命令使配置文件生效。
Step 3:运行IDEA并安装和配置IDEA的Scala开发插件:
官方文档指出:
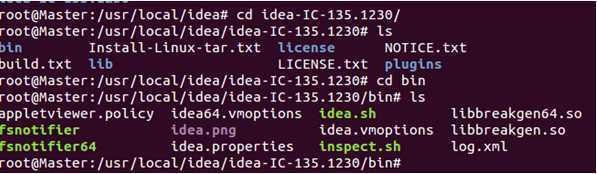
我们进入IDEA的bin目录:
此时,运行“idea.sh”出现如下界面: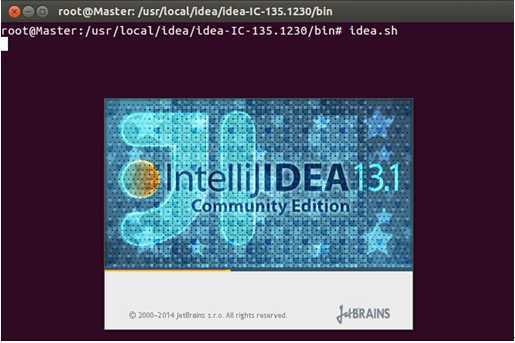
此时需要选择“Configure”进入IDEA的配置页面:
选择“Plugins”,进入插件安装界面:
此时点击左下角的“Install JetBrains plugin”选项进入如下页面:
在左上方的输入框中输入“scala”来查找scala插件:
此时点击右侧的“Install plugin”:
选择“Yes”即可开启Scala插件在IDEA中的自动安装过程。
此时大约需要花费2分钟去下载安装,当然,网速不同下载的耗时也会有所不同:
此时重启IDEA:
此时重启IDEA:
重启后进入如下界面:
Step 4:在IDEA中编写Scala代码:
首先在进入在我们前一步的进入界面中选择“Create New Project”:
此时选在左侧列表中的“Scala”选项:
为了方便以后的开发工作,我们选择右侧的“SBT”选项:
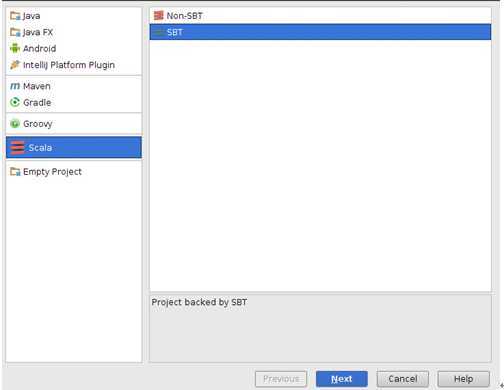
点击“Next”进入下一步,设置Scala工程的名称和目录:
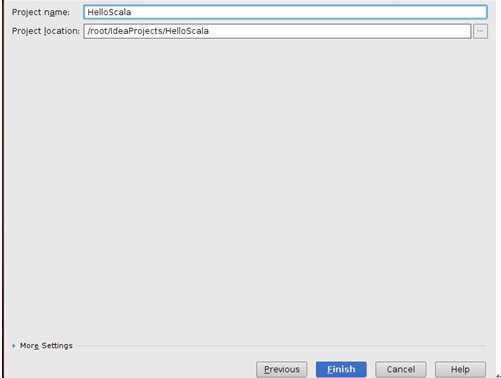
点击“Finish”完成工程的创建:
由于我们在前面选择了“SBT”选择,所以IDEA此时智能的帮助我们构建SBT工具:
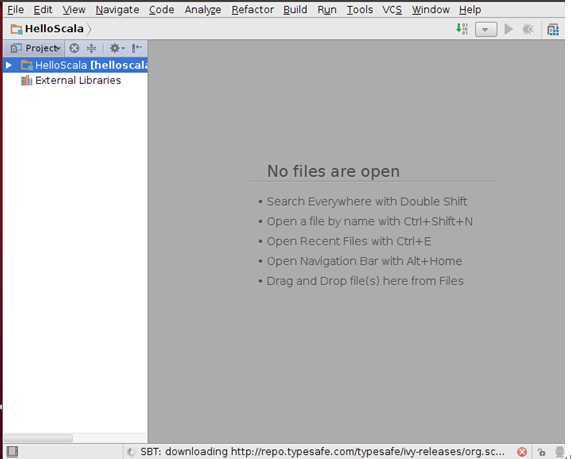
我们点击工程名称“HelloScala”:
IDEA自动完成SBT工具的安装需要一段时间,家林这里花了大约5分钟的时间,SBT好后SBT会自动帮我们建立好一些目录:
此时右击src下的main下的scala在弹出的“New”下选择“Scala Class”
输入文件名称:
把Kinde选择为“Object”:
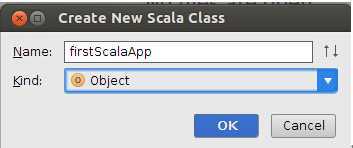
点击“OK”完成:
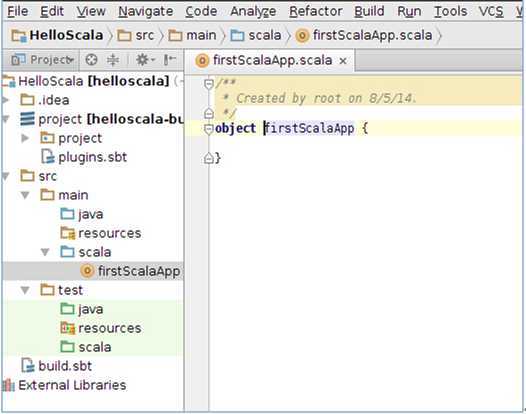
此时把我们的“firstScalaApp”的源代码修改为如下内容:
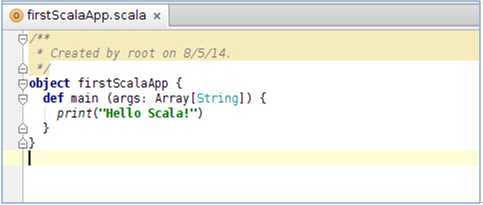
此时我们点击“firstScalaApp”的右键选择“Run Scala Console”出现如下提示:
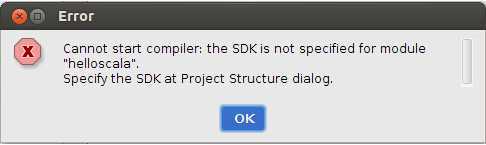
这是由于我们还没有设置Java的JDK路径,点击“OK”,进入如下视图:
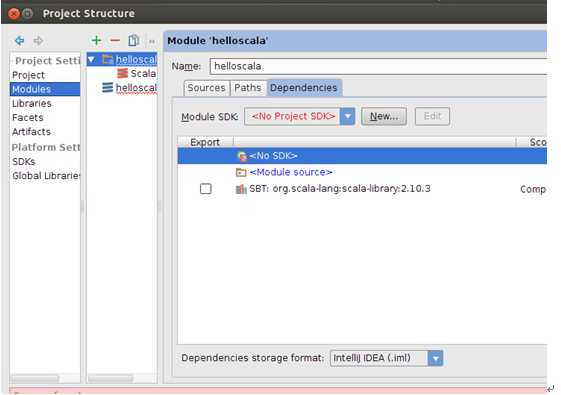
此时我们选择最左侧的“Project”选项:
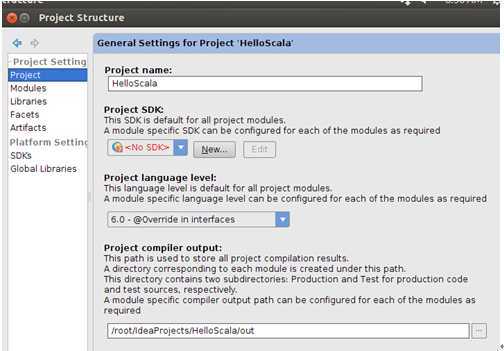
此时我们选择“No SDK”的“New”初选如下视图:
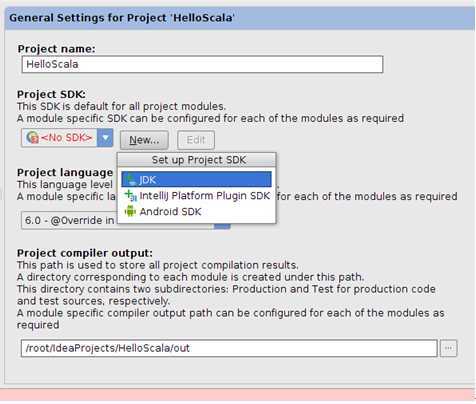
点击“JDK”选项:
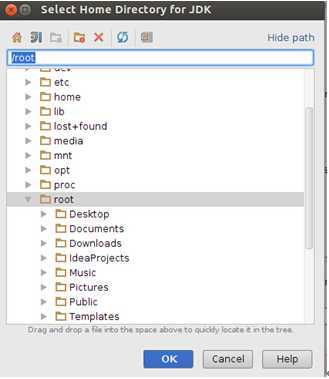
选择我们在前面安装的JDK的目录:
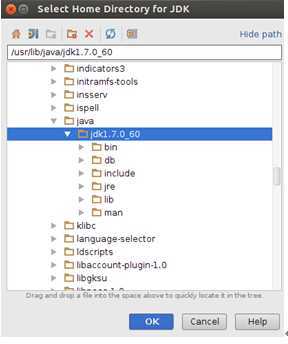
点击“OK”
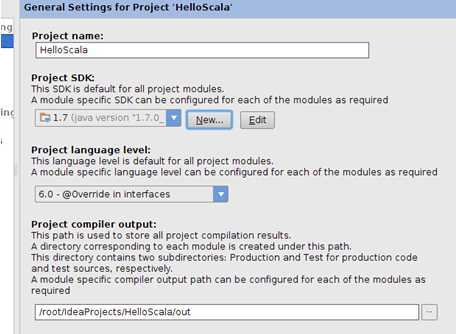
点击确认按钮:
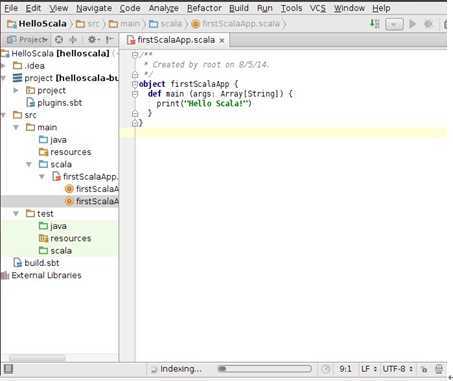
此时直接点击代码区出现如下视图:
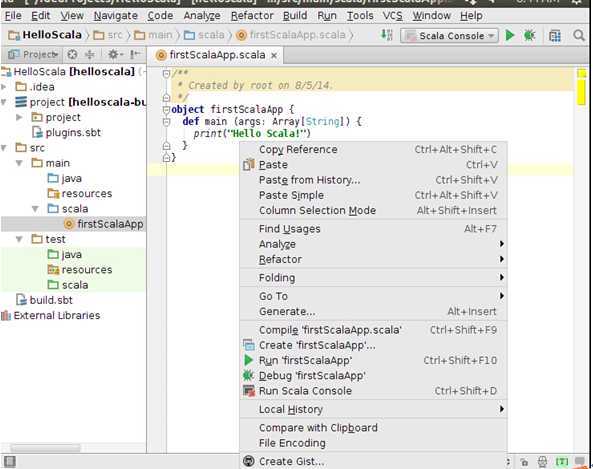
我们选择“Run ‘firstScalaApp’”来运行程序:
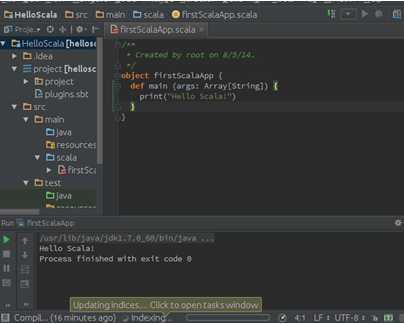
第一运行Scala会有些缓慢,运行结果如下图所示:
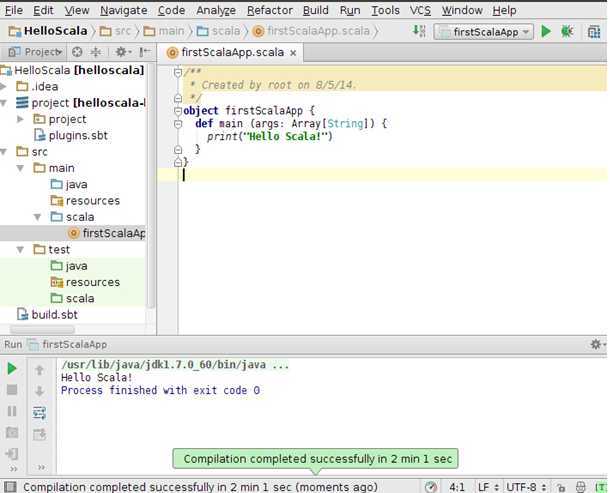
此时成功打印出“Hello Scala!”这个字符串。
此时表明程序运行成功。
Step 5:如果我们要用很酷的黑色背景,可以
File -> Settings -> Appearance -> Theme选择Darcula:
第四步:通过Spark的IDE搭建并测试Spark开发环境
Step 1:导入Spark-hadoop对应的包,次选择“File”–> “Project Structure” –> “Libraries”,选择“+”,将spark-hadoop 对应的包导入:
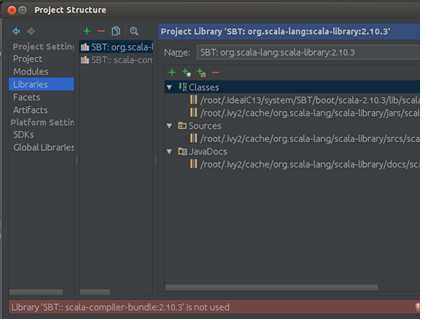
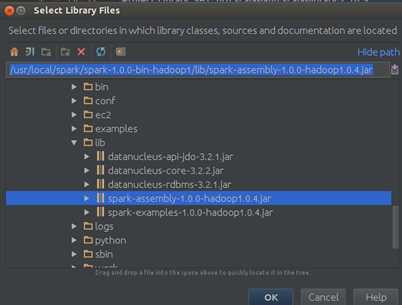
点击“OK”确认:
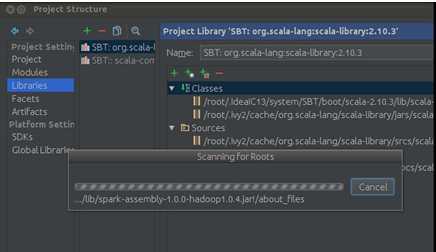
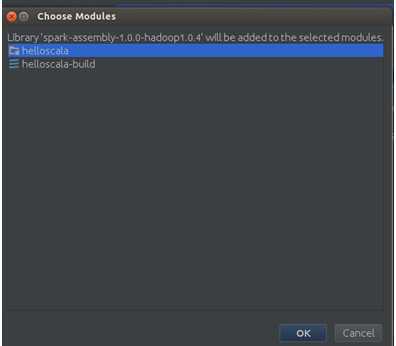
点击“OK”:
IDEA工作完成后会发现Spark的jar包导入到了我们的工程中:
Step 2:开发第一个Spark程序。打开Spark自带的Examples目录:
此时发现内部有很多文件,这些都是Spark给我提供的实例。
在我们的在我们的第一Scala工程的src下创建一个名称为SparkPi的Scala的object:
此时打开Spark自带的Examples下的SparkPi文件:
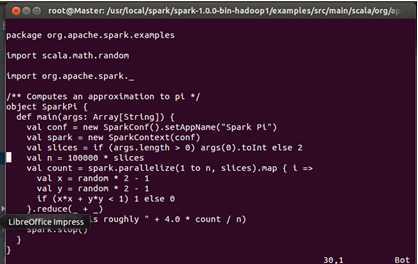
我们把该文的内容直接拷贝到IDEA中创建的SparkPi中:
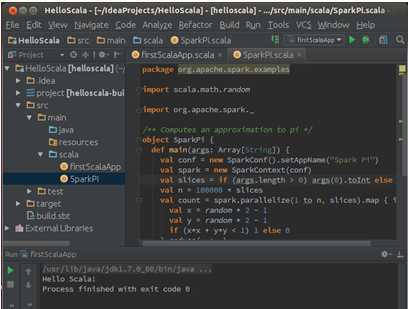
第五步:测试Spark IDE开发环境
此时我们直接选择SparkPi并运行的话会出现如下错误提示:
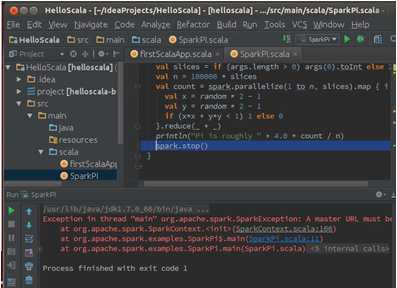
从提示中可以看出是找不到Spark程序运行的Master机器。
此时需要配置SparkPi的执行环境:
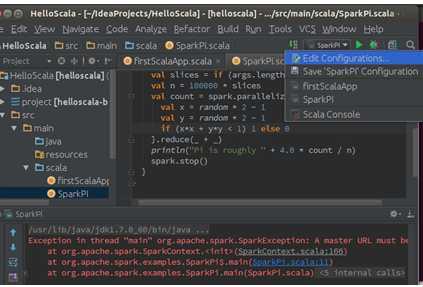
选择“Edit Configurations”进入配置界面:
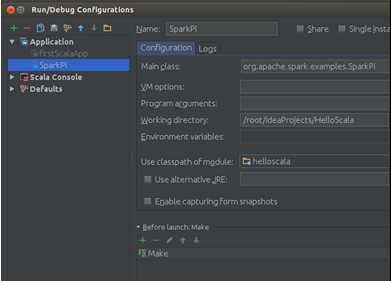
我们在Program arguments中输入“local”:
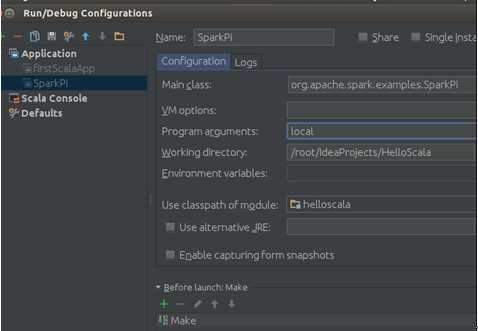
此配置说明我们的程序以local本地的模式运行,配置好后保存。
此时再次运行程序即可。
ubuntu下hadoop,spark配置
标签:des style blog http io color ar os 使用
原文地址:http://www.cnblogs.com/yuanqin/p/4077090.html