标签:下标 upd val alt 字典 读取 list enc turn
一、文件格式
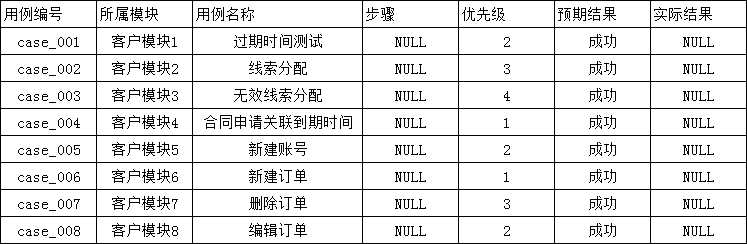
二、第一种方式:列表方式以行为单位读取
Python格式显示:

代码:
import os
import xlrd #导入xlrd模块,可在线安装
def Read_Excel_Case(path):
work=xlrd.open_workbook(path) #打开文件
sheet=work.sheet_by_index(0) # 用下标的方式选择要读取文件中的工作表,也可用工作表的名称 sheet=work.sheet_by_name(‘Sheet1‘)
Case_list=[] #创建一个空列表来接收值
for i in range(1,sheet.nrows): #根据我们需要的格式规则,用外层循环控制行数,sheet.nrows代表了最大行数值
casebranch=[]
for j in range(0,sheet.ncols): #内层循环控制列数,sheet.ncols代表了最大列数值
casebranch.append(sheet.cell_value(i,j)) # 用列表循环接收一行的所有单元个数据
Case_list.append(casebranch) #内层循环结束后,用列表接收读取好了的一行数据
return Case_list #返回数据
三、第二种方式:字典方式以行为单位读取
Python格式显示:

代码:
#encoding: utf-8
import os
import xlrd
import json
class Read_excel_dict_data:
def __init__(self,filepath):
self.fliepath=filepath # 创建一个文件地址的实例属性
self.work=xlrd.open_workbook(self.fliepath) # 打开文件
self.sheet = self.work.sheet_by_index(0) #选择要读取的工作表,以下标的位置
def Getexcrl_dict(self):
dict1={} #定义一个外层空字典
for i in range(1,self.sheet.nrows): #外层循环控制行数,sheet.nrows 最大行数
dict2={} # 定义一个内层空字典
for j in range(1,self.sheet.ncols): #sheet.nrows 最大列数
title=self.sheet.cell_value(0,j) # title变量存入字典的键名,从0开始,对应下标行的列值
value=self.sheet.cell_value(i,j) # value变量存入字典的值
dict2.update({title:value}) #将键值组合起来赋给字典,用update方式 :字典.update({键名:值})
head=self.sheet.cell_value(i,0) #head的变量存入外层字典的键名,每一行的用例编号
dict1.update({head:dict2}) #将head值作为键名赋给外层大字典,将内层小字典的值(除去用例名称的每一行的值)赋给外层字典的值。一一对应。
return dict1
if __name__==‘__main__‘:
current = os.path.dirname(__file__)
Filepath = os.path.join(current, ‘../data/case_01.xlsx‘)
case01=Read_excel_dict_data(Filepath)
value1=case01.Getexcrl_dict()
print(value1)
print(json.dumps(value1,indent=1,ensure_ascii=False)) #字典可以用json格式显示打印,显示的更清楚

Python基础--实战一:用xlrd模块读取excel文档
标签:下标 upd val alt 字典 读取 list enc turn
原文地址:https://www.cnblogs.com/HMeier/p/12613529.html