标签:mat win direct title orm coding from break 时间
注:本博客中的代码实现来自百度问答:https://jingyan.baidu.com/article/c1a3101ef9131c9e646deb5c.html
代码运行环境:win10 python3.7
需要aip库,使用pip install baidu-aip即可
通过百度AipOcr库,来实现识别图片中的表格,并输出问表格文件。
仿照百度问答:https://jingyan.baidu.com/article/c1a3101ef9131c9e646deb5c.html,实现了以下代码:
1 # encoding: utf-8 2 import os 3 import requests 4 import time 5 import tkinter as tk 6 from tkinter import filedialog 7 from aip import AipOcr 8 9 # 定义常量,需要自己去百度智能云申请 10 APP_ID = ‘xxxxxxx‘ 11 API_KEY = ‘xxxxxxxxxxxxx‘ 12 SECRET_KEY = ‘xxxxxxxxxxxxxxxxxx‘ 13 # 初始化AipFace对象 14 client = AipOcr(APP_ID, API_KEY, SECRET_KEY) 15 16 # 读取图片 17 def get_file_content(filePath): 18 with open(filePath, ‘rb‘) as fp: 19 return fp.read() 20 21 22 #文件下载函数 23 def file_download(url, file_path): 24 r = requests.get(url) 25 with open(file_path, ‘wb‘) as f: 26 f.write(r.content) 27 28 29 if __name__ == "__main__": 30 root = tk.Tk() 31 root.withdraw() 32 data_dir = filedialog.askdirectory(title=‘请选择图片文件夹‘) + ‘/‘ 33 result_dir = filedialog.askdirectory(title=‘请选择输出文件夹‘) + ‘/‘ 34 num = 0 35 for name in os.listdir(data_dir): 36 print (‘{0} : {1} 正在处理:‘.format(num+1, name.split(‘.‘)[0])) 37 image = get_file_content(os.path.join(data_dir, name)) 38 res = client.tableRecognitionAsync(image) 39 req_id = res[‘result‘][0][‘request_id‘] #获取识别ID号 40 41 for count in range(1,10): #OCR识别也需要一定时间,设定10秒内每隔1秒查询一次 42 res = client.getTableRecognitionResult(req_id) #通过ID获取表格文件XLS地址 43 print(res[‘result‘][‘ret_msg‘]) 44 if res[‘result‘][‘ret_msg‘] == ‘已完成‘: 45 break #云端处理完毕,成功获取表格文件下载地址,跳出循环 46 else: 47 time.sleep(1) 48 49 url = res[‘result‘][‘result_data‘] 50 xls_name = name.split(‘.‘)[0] + ‘.xls‘ 51 file_download(url, os.path.join(result_dir, xls_name)) 52 num += 1 53 print (‘{0} : {1} 下载完成。‘.format(num, xls_name)) 54 time.sleep(1)
识别的表格图片为:
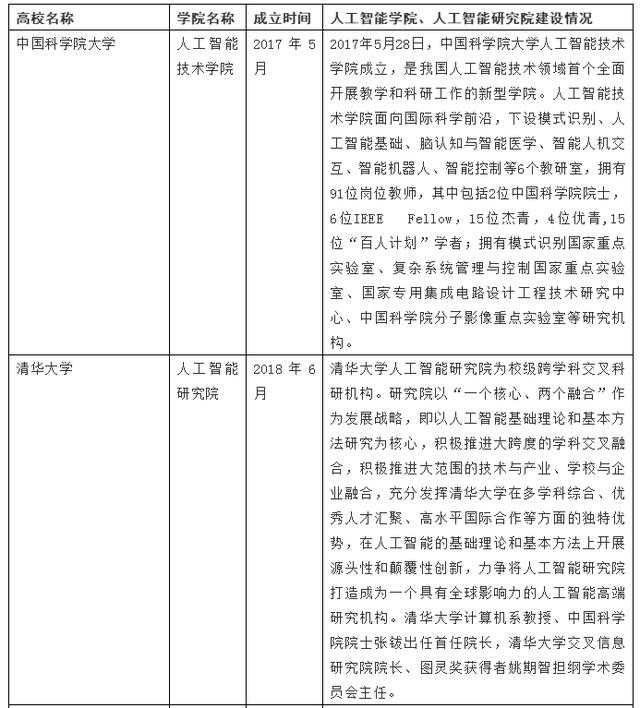
实现的效果为(注:表格的格式人为调整过,但内容没人为修改):
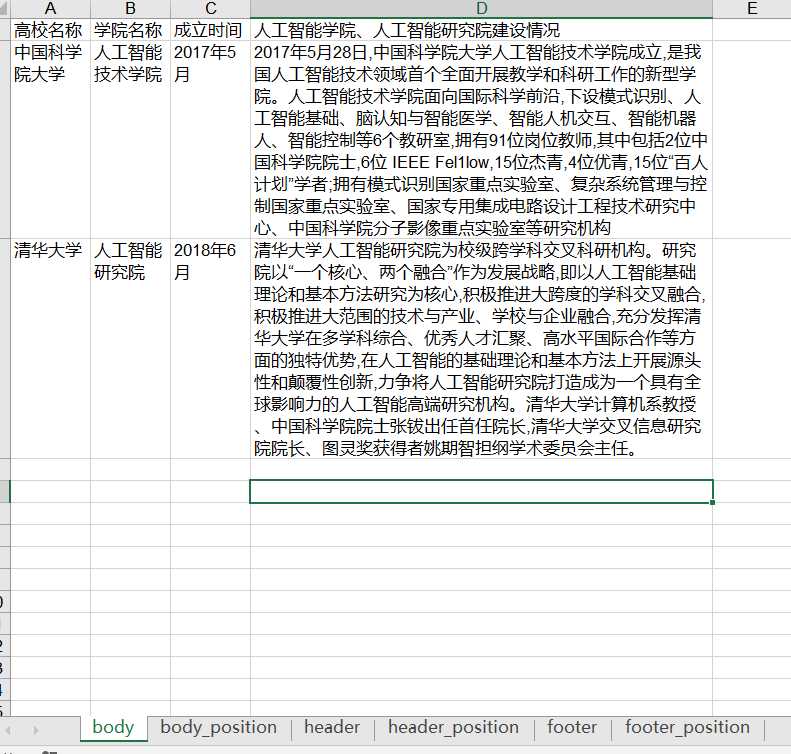
可以看出,识别的精度还是很高的,只有“Fellow”识别为了“Fel1low”。
百度智能云应用创建链接:https://console.bce.baidu.com/ai/?_=1585935093810#/ai/ocr/app/list,创建了一个应用之后,就可以获得APP_ID、API_KEY、SECRET_KEY。
百度智能云文字识别接口说明:https://cloud.baidu.com/doc/OCR/s/3k3h7yeqa。
标签:mat win direct title orm coding from break 时间
原文地址:https://www.cnblogs.com/mrlayfolk/p/12630128.html