标签:png init img toc 一个 ike bre origin 爬虫
爬取斗图啦网站,地址为:https://www.doutula.com/photo/list/,网站截图如下:
现在需要按页爬取前2页的表情包,那么接下来直接上代码吧。
from urllib import request
import requests
from lxml import etree
import re
import os
HEADERS= {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘
}
def parse_url(url):
response = requests.get(url, headers=HEADERS)
text = response.text
html_str = etree.HTML(text)
imgs = html_str.xpath(‘//div[@class="page-content text-center"]//a/img[@class!="gif"]‘)
for img in imgs:
img_url = img.get(‘data-original‘)
alt = img.get(‘alt‘)
# 替换alt中的特殊字符
alt = re.sub(r‘[\?\?\.,。,!!/]‘,‘‘,alt)
# 提取后缀名
suffix = os.path.splitext(img_url)[1]
filename = alt + suffix
print("正在下载:" + filename)
request.urlretrieve(img_url,‘image/‘+filename)
def main():
for i in range(1,3):
base_url = ‘https://www.doutula.com/photo/list/?page={}‘.format(i)
parse_url(base_url)
if __name__ == ‘__main__‘:
main()
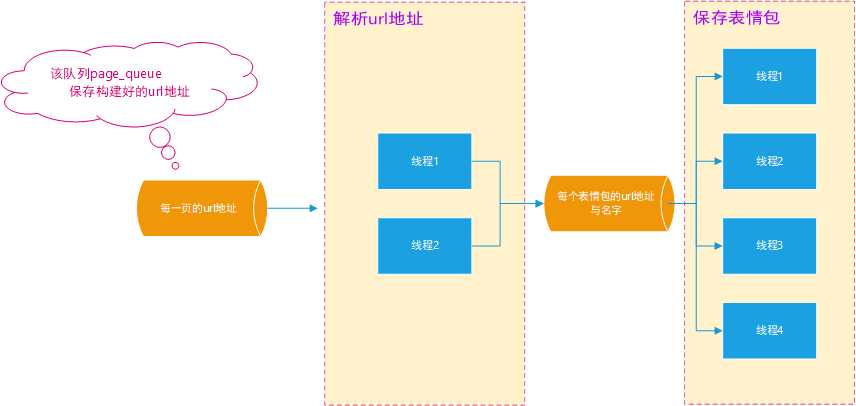
单线程爬取的话,存在一个问题,下载表情包太慢了,等逐一下载。为了解决这个问题,就可以使用多线程来解决这个问题。
# Author:Logan
from urllib import request
import requests
from lxml import etree
import re
import os
from queue import Queue
import threading
# 定义生产者
class Procuder(threading.Thread):
HEADERS = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36‘
}
def __init__(self, page_queue, img_queue, *args, **kwargs):
super(Procuder, self).__init__( *args, **kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_url(url)
def parse_url(self,url):
response = requests.get(url, headers=self.HEADERS)
text = response.text
html_str = etree.HTML(text)
imgs = html_str.xpath(‘//div[@class="page-content text-center"]//a/img[@class!="gif"]‘)
for img in imgs:
img_url = img.get(‘data-original‘)
alt = img.get(‘alt‘)
# 替换alt中的特殊字符
alt = re.sub(r‘[\?\?\.,。,!!/*]‘, ‘‘, alt)
# 提取后缀名
suffix = os.path.splitext(img_url)[1]
filename = alt + suffix
self.img_queue.put((filename,img_url))
self.page_queue.task_done() # 让队列计数减一
class Counsumer(threading.Thread):
def __init__(self, page_queue, img_queue, *args, **kwargs):
super(Counsumer, self).__init__(*args, **kwargs)
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
print("============")
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
filename,img_url = self.img_queue.get()
request.urlretrieve(img_url,‘image/‘+filename)
print("下载完成:%s" %filename)
self.img_queue.task_done()
def main():
page_queue =Queue(100)
img_queue = Queue(1000)
for i in range(1,2):
base_url = ‘https://www.doutula.com/photo/list/?page={}‘.format(i)
page_queue.put(base_url)
for i in range(5):
t1 = Procuder(page_queue, img_queue)
t1.start()
t1.join()
for i in range(5):
t2 = Counsumer(page_queue, img_queue)
t2.start()
t2.join() # 让主线程阻塞(等待子线程结束在结束)
if __name__ == ‘__main__‘:
main()
如果线程里每从队列里取一次,但没有执行task_done(),则join无法判断队列到底有没有结束,在最后执行个join()是等不到结果的,会一直挂起。可以理解为,每task_done一次 就从队列里删掉一个元素,这样在最后join的时候根据队列长度是否为零来判断队列是否结束,从而执行主线程。
标签:png init img toc 一个 ike bre origin 爬虫
原文地址:https://www.cnblogs.com/OliverQin/p/12636681.html