标签:函数 使用 mamicode 包含 时间 二分 就是 平均情况 ima
函数1 用来打印列表元素
函数2 每打印一个元素休眠1秒
这两个函数迭代整个列表一次,运行时间都是O(n) 实际上肯定函数1更快 c为算法固定时间量,称为常量。
比如函数1所需时间可能是10ms * n,
函数二是1s * n 但通常不考虑这个量
从简单查找和二分查找来看,简单查找一次10ms 二分查找一次1s,表面上看简单查找更快。
实际上 如果四十亿个元素肯定二分查找快得多,此时固定时间量起不到影响作用。
但有时候,常量影响可能很大,比如说快速查找和合并查找 快速查找常量较小,如果运行时间都是O(n logn),快速查找会快得多。
实际上,相对于遇上最糟情况,快速查找更容易遇上平均情况
什么是最糟?什么是平均情况?
数组 1,2,3,4,5,6,7,8 如果把第一个数是基准值,实际上要调用八次才能完成排序,这就是最糟情况
而把4作为基准值,就不需要那么多递归调用,调用栈就要短得多,为最佳情况。
最糟情况下,栈长就是O(n),最佳情况下,栈长为O(log n)。

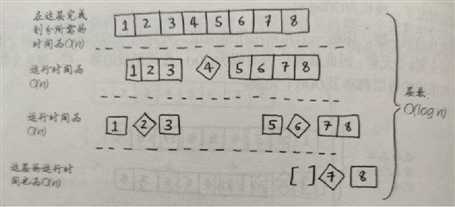
调用栈时 实际每层都设计0(n)个元素
所以最糟情况下 O(n)*O(n) = O(n^2)
而平均情况就是最佳情况,O(nlogn) = O(logn)
小结:
①D&C将问题逐步分解。使用D&C处理列表时,基线条件很可能是空数组或者只包含一个元素的数组
②快速排序时,请随机选择基准值。快速排序平均运行时间为O(n logn)
③大O表示法的常量有时候事关重大,是快速排序比合并排序快得多的原因所在
④比较简单查找和二分查找时,常量不关紧要,因为列表很长,O(log n)的速度比O(n)快得多
标签:函数 使用 mamicode 包含 时间 二分 就是 平均情况 ima
原文地址:https://www.cnblogs.com/zhangshengchao/p/12642087.html