标签:des blog http io ar os 使用 for sp
有很多朋友都需要把天猫的商品迁移到微店上去。可在天猫上的商品数据非常复杂,淘宝开放接口禁止向外提供数据,一般的采集器对ajax数据采集的支持又不太好。
还有现在有了火蜘蛛采集器,经过一定的配置,终于把天猫商品的数据都采集下来了(SKU信息,运费信息,库存信息,图片,商品描述等)。天猫商品网页的确是很复杂,比如商品描述,还有商品描述中的图片,使用的都是懒加载,只有当用户滚动到那里了,才会去加载描述和图片。还好这些都难不倒火蜘蛛采集器。当然了,采集回来的信息也是很复杂的,需要我们清楚了解淘宝的商品数据结构,并转换成微店的商品数据结构,然后调用微店接口进行添加。
火蜘蛛采集器下载地址:
http://firespider.duapp.com/FireSpiderWeb/index.html
如何在安装包里就已经说明了。不过现在安装包只支持win7系统。如果是win8,安装客户端时要把安装包下的components目录手工复制覆盖C:\Program Files (x86)\Mozilla Firefox\browser\components。
下面说说采集的过程
要采集网页的数据,首先要做的当然是对目标网页进行分析,目标是找出我们要采集的数据到底在哪里。这可以说是采集过程中最重要的一步。这里我们使用firebug进行分析。使用火狐浏览器打开一个天猫商品,比如:
http://detail.tmall.com/item.htm?spm=a1z10.1002.w4948-8875692881.4.4bX5Dj&id=40660880252
使用firebug分析网页结构,主要是通过几个方面进行了解:页面源代码,处理完成后的HTML,脚本,网络加载。
页面源代码:在网页右击,选择查看网页源代码可以看到。通过查看网页源代码,可以大致推测到网页使用什么样的方式加载显示,以及了解部分网页的加载逻辑。
处理完成后的HTML:通过firebug的“html”tab页可查看到完整的处理完成后的HTML树。通过查看处理完成后的HTML,与页面源代码进行对比,也可以推测网页的加载方式。
脚本:通过firebug的”script”tab页可查看到当前网页加载了哪些脚本。
网络加载:通过firebug的”net”tab页可查看到打开当前网页后一共加载了多少网络请求,以及各个网络请求的返回内容。
通过对天猫商品页的分析,我们发现:
1) 商品图像,通过HTML就可以取到
2) 商品SKU信息,如尺码和颜色,通过HTML也能取到
3) 产品参数,通过HTML也可以取到
4) 商品的一部分信息,如SKU价格等,页面源代码的一个script中,可以取到这个script的text再进行截取,得到一个json字符串
5) 商品的运费信息,在
http://mdskip.taobao.com/core/initItemDetail.htm?。。。链接返回的数据中,通过截取,得到一个json字符串
6) 商品的描述信息,通过HTML也可以取到。但是必须要慢慢滚动下去,触发懒加载后,待图片加载完成,才能取到。
知道了我们要采集数据在哪里之后,我们就可以开始定制采集了:定义执行器,提取器,采集模块,采集任务等。鉴于一些网页的复杂性(例如淘宝),有时我们会需要反复进行尝试,直到找到合适的方法为止。下面介绍一下我们定制的天猫采集任务:
2.1 商品页采集模块
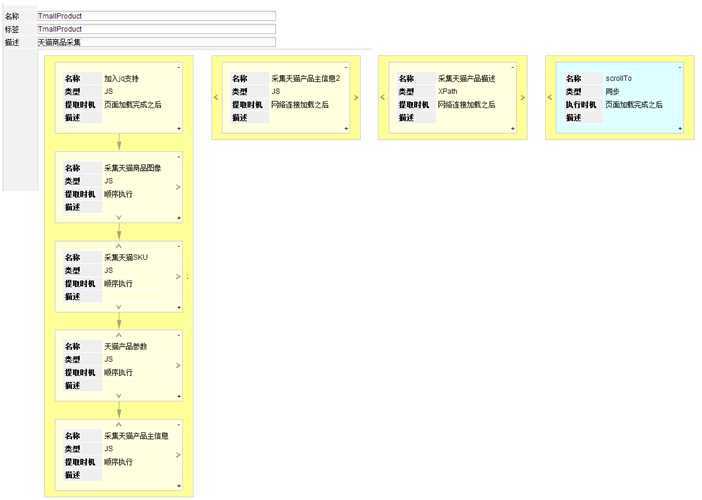
这里定义了四个处理器链:
第一个链:在网页加载完成后,依次执行“加入JQ支持”,“采集天猫商品图像”,“采集天猫SKU”,“天猫产品参数”,“采集天猫产品主信息”。
第二个链:在某个网络链接加载完成后,执行“采集天猫产品主信息2”。
第三个链:在某个网络链接加载完成后,执行“采集天猫产品描述”。
第四个链:在网页加载完成后,执行“scrollTo”。
下面我们对这些处理器逐个进行介绍:
加入JQ支持
加入JQ支持本来应该定义为执行器,这里把它定义为提取器。不过这也无妨,执行器跟JS提取器本质上是一样的,只是有无参数有无返回值的区别而已。加入JQ支持的目的只是为了在后面的处理器中写JS脚本方便一些,可以直接使用JQ脚本。当然,天猫商品页面本来就已经使用了$这个函数名,所以不要忘记了调用一下jQuery.noConflict();
此处理器的实现,就只是把jquery.mini.js源码考到function里面了,再调用一下jQuery.noConflict();
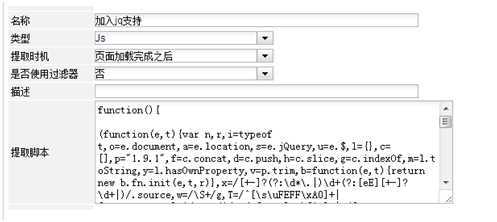
function(){
//把jquery.mini.js源码考到这里
//…
//把$还给原始页面
jQuery.noConflict();
}
采集天猫商品图像
商品图像都在页面上的J_UIThumb这个UL下面,我们通过jquery取到它。注意,这里取到的图像链接是小图的图像链接。对小图链接经过截取得到大图链接。
小图链接:http://gi1.md.alicdn.com/bao/uploaded/i1/TB128CJGpXXXXa0XXXXXXXXXXXX_!!0-item_pic.jpg_60x60q90.jpg
大图链接:http://gi1.md.alicdn.com/bao/uploaded/i1/TB128CJGpXXXXa0XXXXXXXXXXXX_!!0-item_pic.jpg
还有一点要注意,就是要对这个提取器配置添加“链接下载过滤器”,这样采集器会把这些图像都保存到本地,方便后续处理。
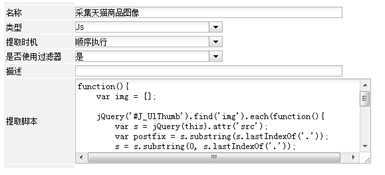
脚本:
function(){
var img = [];
jQuery(‘#J_UlThumb‘).find(‘img‘).each(function(){
var s = jQuery(this).attr(‘src‘);
// 对小图链接进行截取得到大图链接
var postfix = s.substring(s.lastIndexOf(‘.‘));
s = s.substring(0, s.lastIndexOf(‘.‘));
s = s.substring(0, s.lastIndexOf(‘.‘));
s = s + postfix;
img.push(s);
});
return {
mainImgs:{
type:‘list‘,
value:img,
useFor:‘save‘,
tag:‘‘
}
}
}
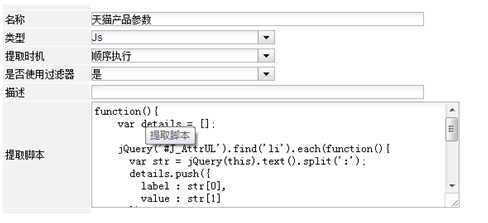
采集天猫SKU,天猫产品参数
这两个不用多说,只是从HTML中取出SKU信息。跟平时我们用JQ操作DOM是一样一样的。
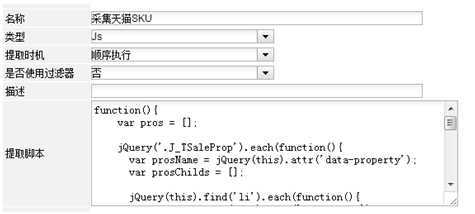
采集天猫产品主信息
天猫商品主信息都放在一个script标签中,取得这个script的内容,并进行截取,就可以得到天猫商品主信息。
function(){
//取得script标签中的内容
var str = document.getElementById(‘J_FrmBid‘).nextSibling.nextSibling.innerHTML;
//对内容进行截取
str = str.substring(str.indexOf(‘TShop.Setup(‘) + 12);
str = str.substring(0, str.lastIndexOf(‘);‘));
str = str.substring(0, str.lastIndexOf(‘);‘));
//解析成json
var result = JSON.parse(str);
return {
mainInfo:{
type:‘data‘,
value:result,
useFor:‘save‘,
tag:‘‘
}
};
}
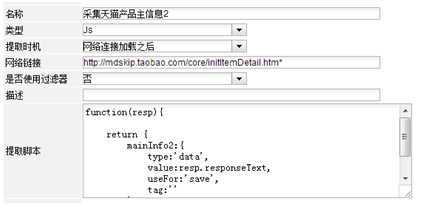
采集天猫产品主信息2
通过网页分析我们知道天猫商品的一部分信息是通 http://mdskip.taobao.com/core/initItemDetail.htm 这个链接进行加载的,所以我们定义了一个提取器,提取时机为网络加载之后,用于采集这部分的内容。
注意“提取脚本”中的resp参数,“网络连接加载之后”的处理器处理脚本都会接收这个参数,可通过resp.responseText取得网络加载的内容。
采集天猫产品描述,scrollTo
这两个处理器是组合使用的。在网页分析时我们知道产品描述是懒加载的。如果在网页加载完成后就通过$(‘#description’).html()来提取产品描述,只能提取到“描述加载中”几个字。我们要模拟用户慢慢拖动滚动条滚动网页,scrollTo处理器就是用于模拟这个过程,以触发产品描述的懒加载。
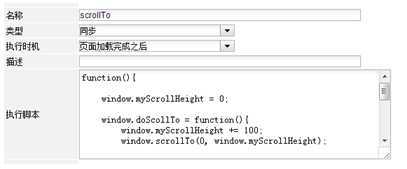
//scrollTo的执行脚本
function(){
//定义一个全局变量,用于记录当前滚动高度
window.myScrollHeight = 0;
//定义一个全局函数,
window.doScrollTo = function(){
//滚动高度增加100
window.myScrollHeight += 100;
window.scrollTo(0, window.myScrollHeight);
var nHeight = document.documentElement.scrollTop + window.screen.availHeight;
//如果已经滚动到底了,调用跨域加载,用于触发提取器“采集天猫产品描述”
if(nHeight >= document.body.scrollHeight){
//注意这里要加上r=Math.random(),防止因网页缓存而不加载
jQuery.ajax({url:"http://localhost:8090/FireSpider/html/index.html?r=" + Math.random(),crossDomain:true});
} else {
//如果还没有滚动到底,200毫秒后再次调用doScrollTo
window.setTimeout("doScrollTo()", 200);
}
}
//200毫秒后调用doScrollTo
window.setTimeout("doScrollTo()", 200);
}
“采集天猫产品描述”定义为在http://localhost:8090/FireSpider/*加载完成后执行。而此网络连接正是由scrollTo触发加载的。
2.2 列表页采集模块
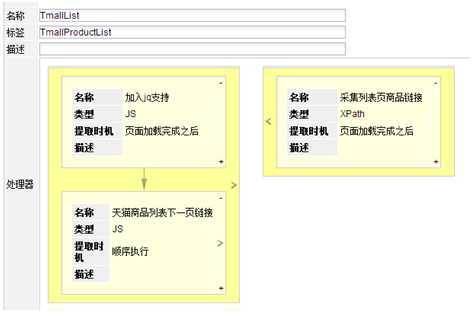
天猫商品列表下一页链接
商品列表页是分页显示的,列表页都要采集。在采集每一页列表页的时候,都看看是否有“下一页”链接,把链接加入采集URL中。

脚本
function(){
// 如果有”下一页”链接
var len = jQuery(‘.next‘).length;
if(len > 0){
var url = jQuery(‘.next‘).attr(‘href‘);
return {
nextPage:{
type : ‘data‘,
value : url,
useFor : ‘url‘,
tag : ‘TmallProductList‘
}
};
}
}
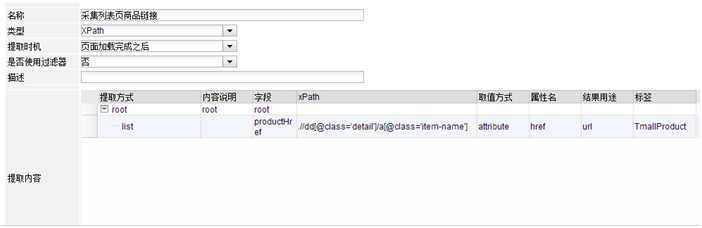
采集列表页商品链接
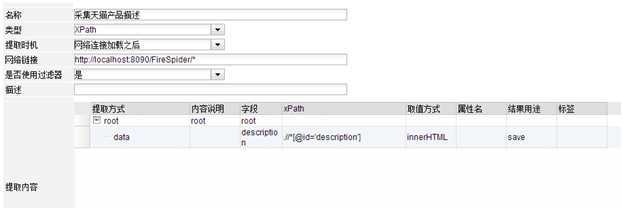
用于采集列表页的商品链接,这是个xpath提取器,通过firebug可看到xpath是 .//dd[@class=‘detail‘]/a[@class=‘item-name‘]
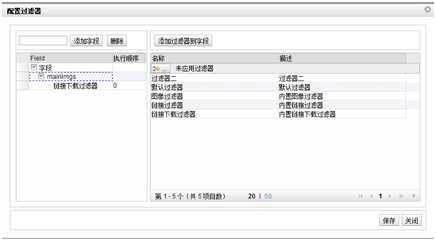
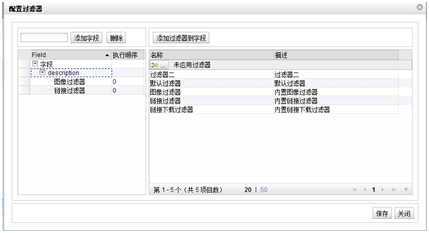
3. 过滤器
需要配置过滤器的有:“天猫商品图像”,“采集天猫产品描述”,目的是要把图片保存到本地。
天猫商品图像
采集天猫产品描述
4. 采集任务
4.1 单个商品采集任务(测试用)
这个任务只是采集一个商品,主要是用来测试看商品页的采集是否能成功运行。
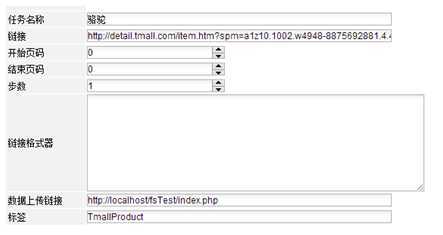
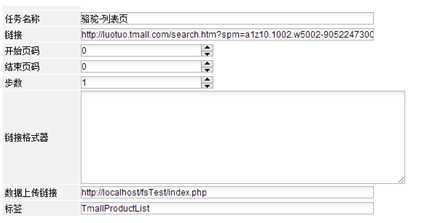
4.2 正式采集任务
这个是正式的采集任务,入口是商品列表页的第一页。
使用火蜘蛛采集器Firespider采集天猫商品数据并上传到微店
标签:des blog http io ar os 使用 for sp
原文地址:http://www.cnblogs.com/rexy/p/4077675.html