标签:word lib 技术 pid time urllib 设置 www init
#发送请求 response = requests.get(url) #response的常用属性: response.text # 根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码 response.encoding=”gbk” # 修改编码方式 respones.content # bytes类型 response.content.deocde(“utf8”) # 解码 response.status_code # 获取状态码 response.request.headers # 获取请求头 response.headers # 获取响应头 # 携带header的请求 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} requests.get(url,headers=headers) # 携带带参数的请求 dic = {‘name‘:‘python‘} requests.get(url,params=dic)
# 发送请求 response = requests.post("http://www.baidu.com/", data = data,headers=headers) data 的形式:字典 # 代理的使用 requests.get("http://www.baidu.com", proxies = proxies) proxies的形式:字典 proxies = { "http": "http://192.11.11.22:2222", "https": "https://12.34.56.79:2222", }
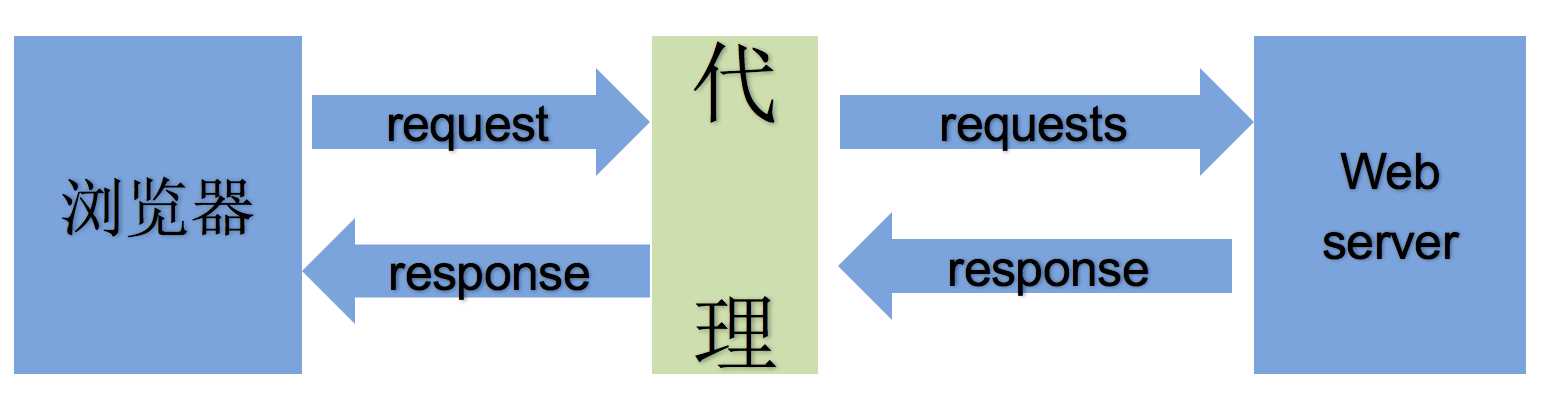
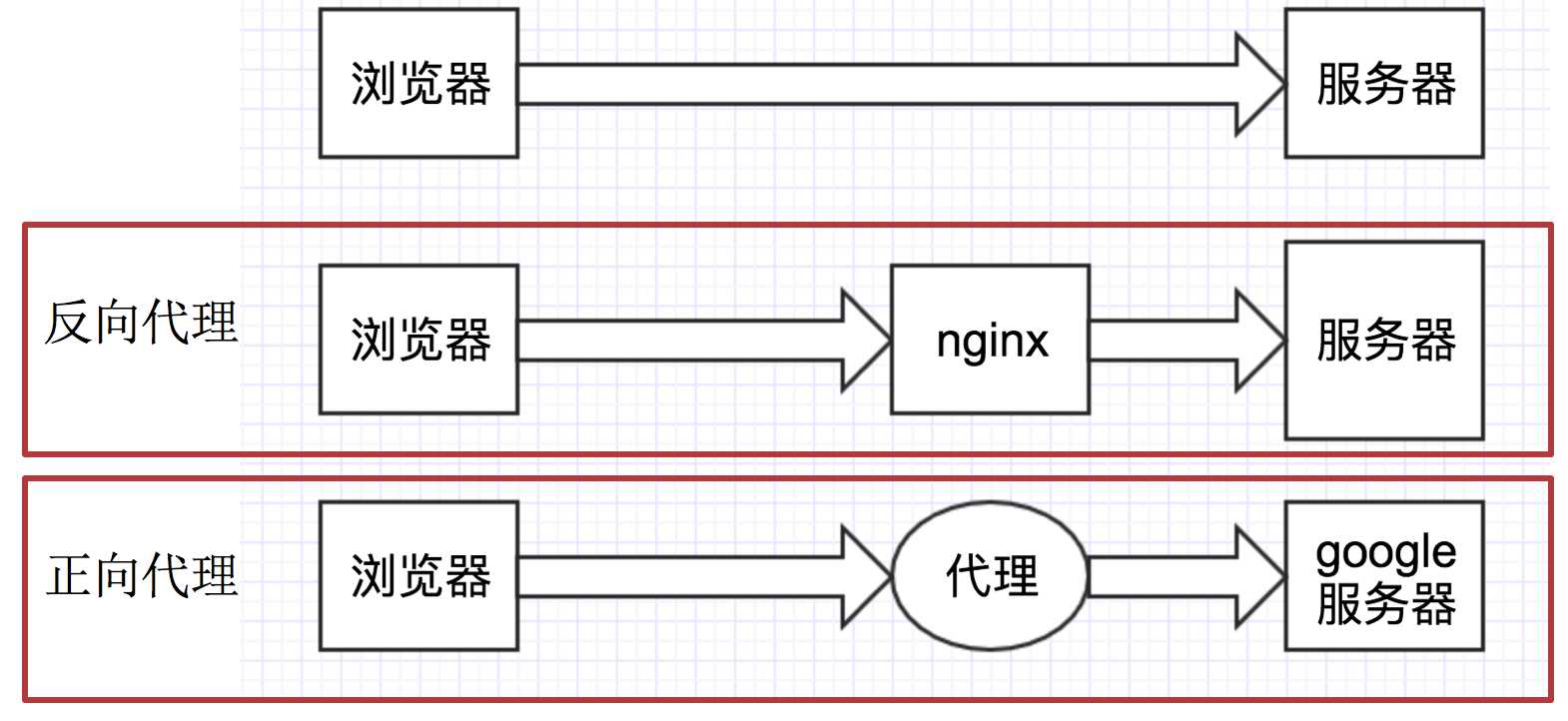
正向代理和反向代理
代理IP的分类
根据代理服务器端的配置,向目标地址发送请求时,REMOTE_ADDR, HTTP_VIA,HTTP_X_FORWARDED_FOR三个变量不同而可以分为下面四类:
透明代理(Transparent Proxy)
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Your IP
透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以从HTTP_X_FORWARDED_FOR来查到你是谁。
匿名代理(Anonymous Proxy)
REMOTE_ADDR = proxy IP
HTTP_VIA = proxy IP
HTTP_X_FORWARDED_FOR = proxy IP
匿名代理比透明代理进步了一点:别人只能知道你用了代理,无法知道你是谁。
混淆代理(Distorting Proxies)
REMOTE_ADDR = Proxy IP
HTTP_VIA = Proxy IP
HTTP_X_FORWARDED_FOR = Random IP address
如上,与匿名代理相同,如果使用了混淆代理,别人还是能知道你在用代理,但是会得到一个假的IP地址,伪装的更逼真
高匿代理(Elite proxy或High Anonymity Proxy)
REMOTE_ADDR = Proxy IP
HTTP_VIA = not determined
HTTP_X_FORWARDED_FOR = not determined
可以看出来,高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
从使用的协议:代理ip可以分为http代理,https代理,socket代理等,使用的时候需要根据抓取网站的协议来选择
3.1 requests处理cookie相关的请求之使用cookies
# cookies的形式:字典 cookies = {"cookie的name":"cookie的value"} # 使用方法: resp = requests.get(url,headers=headers,cookies=cookies}
# requests.utils.dict_from_cookiejar:把cookiejar对象转化为字典
import requests url = "http://www.baidu.com" response = requests.get(url) print(type(response.cookies)) cookies = requests.utils.dict_from_cookiejar(response.cookies) print(cookies)
3.2 requests处理cookie相关的请求之session
# requests 提供了一个叫做session类,来实现客户端和服务端的会话保持 # 会话保持有两个内涵: # 保存cookie # 实现和服务端的长连接 # 使用方法 session = requests.session() response = session.get(url,headers) # session实例在请求了一个网站后,对方服务器设置在本地的cookie会保存在session中,下一次再使用session请求对方服务器的时候,会带上前一次的cookie
class Login(): def __init__(self, loginName, password): # 用户名和密码 self.loginName = loginName self.password = password # 接口地址 self.login_url = ‘‘ self.headers = { "Origin": "*", "Referer": "* ‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36‘ } # spider session self.session = requests.session() def parse_get(self, url, params): ‘‘‘ 发送get请求 :param url: :param params: :return: ‘‘‘ resp = self.session.get(url=url, params=params, headers=self.headers) return resp.content.decode()
3.3 requests处理证书错误
# ssl的证书不安全导致,添加verify=False参数 import requests url = "https://www.12306.cn/mormhweb/" response = requests.get(url,verify=False)
3.4 超时参数添加
# 添加timeout参数,能够保证在3秒钟内返回响应,否则会报错 response = requests.get(url,timeout=3)
3.5 retrying模块的使用
# parse.py import requests from retrying import retry headers = {} @retry(stop_max_attempt_number=3) #最大重试3次,3次全部报错,才会报错 def _parse_url(url) response = requests.get(url, headers=headers, timeout=3) #超时的时候回报错并重试 assert response.status_code == 200 #状态码不是200,也会报错 return response def parse_url(url) try: #进行异常捕获 response = _parse_url(url) except Exception as e: print(e) response = None return response
标签:word lib 技术 pid time urllib 设置 www init
原文地址:https://www.cnblogs.com/caijunchao/p/12643895.html