标签:开头 字段名 学习 三方 ima 文件 空白 com 垂直
说明: 本文用到的数据集下载地址:
链接:https://pan.baidu.com/s/1zSOypUVoYlGcs-z2pT2t0w 提取码:z95a
Pands模块可以帮助数据分析师轻松地解决数据的预处理问题,如数据类型的转换、缺失值的处理、描述性统计分析、数据的汇总等。Pandas模块的核心操作对象就是序列(Series)和数据框(DataFrame)。序列可以理解为数据集中的一个字段,数据框是指含有至少两个字段(或序列)的数据集。
构造一个序列可以使用如下方式实现:
import pandas as pd
import numpy as np
# 列表(元组)构造序列
gdp1 = pd.Series([2.8,3.01,8.99,8.2,2.58])
print(gdp1)
# 字典构造序列
gdp2 = pd.Series({"北京":2.8,"上海":3.01,"广东":8.99,"浙江":8.2,"重庆":2.58})
print(gdp2)
# Numpy一维数组构建
gdp3 = pd.Series(np.array([2.8,3.01,8.99,8.2,2.58]))
print(gdp3)
# 数据框DataFrame
df = pd.DataFrame([2.8,3.01,8.99,8.2,2.58],[2.8,3.01,8.99,8.2,2.58])
gdp4 = pd.Series(df[0])
print(gdp4)
0 2.80
1 3.01
2 8.99
3 8.20
4 2.58
dtype: float64
上海 3.01
北京 2.80
广东 8.99
浙江 8.20
重庆 2.58
dtype: float64
0 2.80
1 3.01
2 8.99
3 8.20
4 2.58
dtype: float64
2.80 2.80
3.01 3.01
8.99 8.99
8.20 8.20
2.58 2.58
Name: 0, dtype: float64
数据框实质上就是一个数据集,数据集的行代表每一条观测,数据集的列则代表各个变量。在一个数据框中可以存放不同数据类型的序列,如整数型、浮点型、字符型和日期时间型,而数组和序列则没有这样的优势,因为它们只能存放同质数据。构造一个数据库可以应用如下方式:
import pandas as pd
import numpy as np
# 嵌套列表
df1 = pd.DataFrame([[‘张三‘,‘female‘,2001,‘"北京‘],[‘李四‘,‘female‘,2001,‘上海‘],[‘王五‘,‘male‘,2003,‘广州‘]])
print(df1)
# 字典
data = {
"name":["张三","李四","王五"],
"sex":["female","female","male"],
"year":[2001,2001,2003],
"city":["北京","上海","广州"]
}
df2 = pd.DataFrame(data)
print(df2)
# 二维数组
arr = np.array([[‘张三‘,‘female‘,2001,‘"北京‘],[‘李四‘,‘female‘,2001,‘上海‘],[‘王五‘,‘male‘,2003,‘广州‘]])
print(arr)
df3 = pd.DataFrame(arr)
print(df3)
#外部读取
# 见下面
0 1 2 3
0 张三 female 2001 "北京
1 李四 female 2001 上海
2 王五 male 2003 广州
city name sex year
0 北京 张三 female 2001
1 上海 李四 female 2001
2 广州 王五 male 2003
[[‘张三‘ ‘female‘ ‘2001‘ ‘"北京‘]
[‘李四‘ ‘female‘ ‘2001‘ ‘上海‘]
[‘王五‘ ‘male‘ ‘2003‘ ‘广州‘]]
0 1 2 3
0 张三 female 2001 "北京
1 李四 female 2001 上海
2 王五 male 2003 广州
Python读取txt或csv格式中的数据,可以使用Pandas模块中的read_table函数或read_csv函数。这里的“或”并不是指每个函数只能读取一种格式的数据,而是这两种函数均可以读取文本文件的数据。
- filepath_or_buffer:指定txt文件或csv文件所在的具体路径。
- sep:指定原数据集中各字段之间的分隔符,默认为Tab制表符。
- header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称。
- names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头。* * index_col:指定原数据集中的某些列作为数据框的行索引(标签)。
- usecols:指定需要读取原数据集中的哪些变量名。
- dtype:读取数据时,可以为原数据集的每个字段设置不同的数据类型。
- converters:通过字典格式,为数据集中的某些字段设置转换函数。
- skiprows:数据读取时,指定需要跳过原数据集开头的行数。
- skipfooter:数据读取时,指定需要跳过原数据集末尾的行数。
- nrows:指定读取数据的行数。
- na_values:指定原数据集中哪些特征的值作为缺失值。
- skip_blank_lines:读取数据时是否需要跳过原数据集中的空白行,默认为True。
- parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)。
- thousands:指定原始数据集中的千分位符。
- comment:指定注释符,在读取数据时,如果碰到行首指定的注释符,则跳过改行。
- encoding:如果文件中含有中文,有时需要指定字符编码。
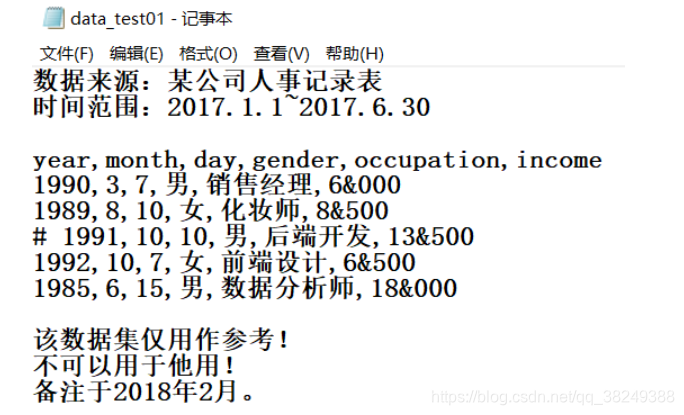
user_income = pd.read_table(r"E:/Data/3/data_test01.txt", sep=‘,‘,parse_dates={‘birthday‘:[0,1,2]},skiprows=2,skipfooter=3,comment=‘#‘,encoding=‘utf-8‘,thousands=‘&‘,engine=‘python‘)
user_income
| birthday | gender | occupation | income | |
|---|---|---|---|---|
| 0 | 1990-03-07 | 男 | 销售经理 | 6000 |
| 1 | 1989-08-10 | 女 | 化妆师 | 8500 |
| 2 | 1992-10-07 | 女 | 前端设计 | 6500 |
| 3 | 1985-06-15 | 男 | 数据分析师 | 18000 |
Pandas模块中的read_excel函数,能完美地读取电子表格数据。其参数列表如下:
- io:指定电子表格的具体路径。
- sheetname:指定需要读取电子表格中的第几个Sheet,既可以传递整数也可以传递具体的Sheet名称。
- header:是否需要将数据集的第一行用作表头,默认为是需要的。
- skiprows:读取数据时,指定跳过的开始行数。
- skip_footer:读取数据时,指定跳过的末尾行数。
- index_col:指定哪些列用作数据框的行索引(标签)。
- names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头。
- parse_cols:指定需要解析的字段。
- parse_dates:如果参数值为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键)。
- na_values:指定原始数据中哪些特殊值代表了缺失值。
- thousands:指定原始数据集中的千分位符。
- convert_float:默认将所有的数值型字段转换为浮点型字段。
- converters:通过字典的形式,指定某些列需要转换的形式。
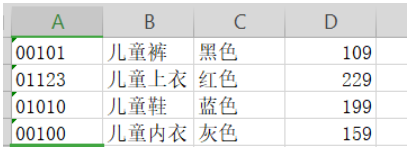
child_cloth = pd.read_excel(r"E:/Data/3/data_test02.xlsx",header=None,converters={0:str},names=["编号","服装名","颜色","价格"])
child_cloth
| 编号 | 服装名 | 颜色 | 价格 | |
|---|---|---|---|---|
| 0 | 00101 | 儿童裤 | 黑色 | 109 |
| 1 | 01123 | 儿童上衣 | 红色 | 229 |
| 2 | 01010 | 儿童鞋 | 蓝色 | 199 |
| 3 | 00100 | 儿童内衣 | 灰色 | 159 |
- sql:SQL命令字符串
- con:连接sql数据库的engine,一般可以用SQLalchemy或者pymysql之类的包建立
- index_col: 选择某一列作为index
- coerce_float:非常有用,将数字形式的字符串直接以float型读入
- parse_dates:将某一列日期型字符串转换为datetime型数据,与pd.to_datetime函数功能类似。可以直接提供需要转换的列名以默认的日期形式转换,也可以用字典的格式提供列名和转换的日期格式,比如{column_name:
format string}(format string:"%Y:%m:%H:%M:%S")。- columns:要选取的列。一般没啥用,因为在sql命令里面一般就指定要选择的列了
- chunksize:如果提供了一个整数值,那么就会返回一个generator,每次输出的行数就是提供的值的大小。
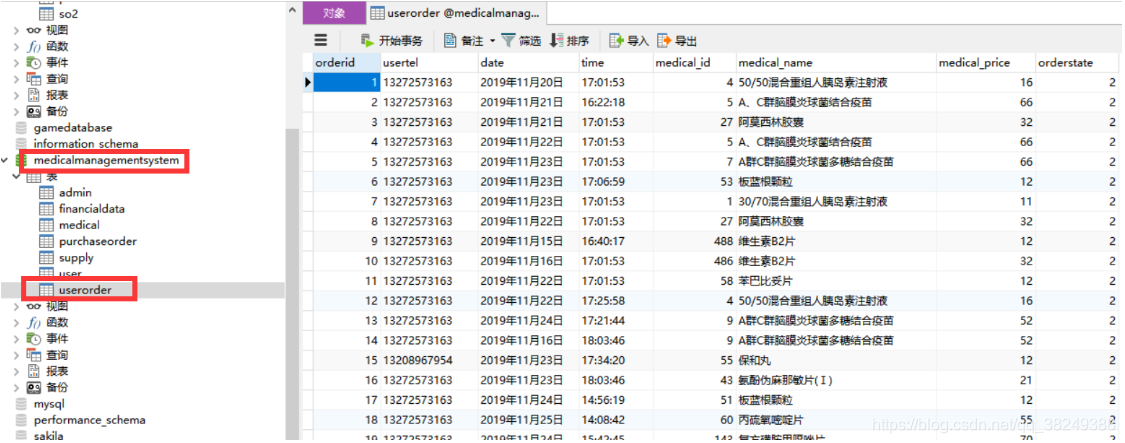
# 读入mysql数据库中的数据
# 导入第三方模块
import pymysql
#连接数据库
conn = pymysql.connect(host="localhost",user="root",password="123456",database="medicalmanagementsystem",charset=‘utf8‘)
# 读取数据
data = pd.read_sql(‘select orderid,date,time,medical_name,medical_price from userorder where orderid <10‘,conn)
# 关闭连接
conn.close()
# 数据输出
data
| orderid | date | time | medical_name | medical_price | |
|---|---|---|---|---|---|
| 0 | 1 | 2019年11月20日 | 17:01:53 | 50/50混合重组人胰岛素注射液 | 16.0 |
| 1 | 2 | 2019年11月21日 | 16:22:18 | A、C群脑膜炎球菌结合疫苗 | 66.0 |
| 2 | 3 | 2019年11月21日 | 17:01:53 | 阿莫西林胶囊 | 32.0 |
| 3 | 4 | 2019年11月22日 | 17:01:53 | A、C群脑膜炎球菌结合疫苗 | 66.0 |
| 4 | 5 | 2019年11月23日 | 17:01:53 | A群C群脑膜炎球菌多糖结合疫苗 | 66.0 |
| 5 | 6 | 2019年11月23日 | 17:06:59 | 板蓝根颗粒 | 12.0 |
| 6 | 7 | 2019年11月23日 | 17:01:53 | 30/70混合重组人胰岛素注射液 | 11.0 |
| 7 | 8 | 2019年11月22日 | 17:01:53 | 阿莫西林胶囊 | 32.0 |
| 8 | 9 | 2019年11月15日 | 16:40:17 | 维生素B2片 | 12.0 |
了解数据,例如读入数据的规模如何、各个变量都属于什么数据类型、一些重要的统计指标对应的值是多少、离散变量各唯一值的频次该如何统计等。下面以某平台二手车信息为例:
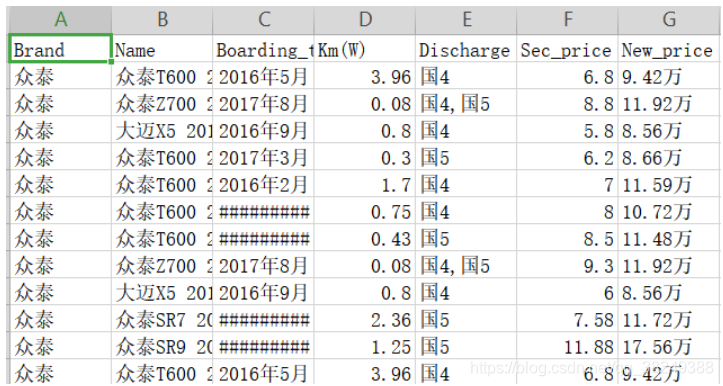
import pandas as pd
# 读取数据
second_cars = pd.read_table(r"E:/Data/3/sec_cars.csv",sep=‘,‘,encoding=‘gbk‘)
#查看数据集的行列数
print("行,列为:\n",second_cars.shape)
# 查看各个变量数据类型
print("各个变量的数据类型:\n",second_cars.dtypes)
行,列为:
(11125, 7)
各个变量的数据类型:
Brand object
Name object
Boarding_time object
Km(W) float64
Discharge object
Sec_price float64
New_price object
dtype: object
#预览前五行
second_cars.head()
| Brand | Name | Boarding_time | Km(W) | Discharge | Sec_price | New_price | |
|---|---|---|---|---|---|---|---|
| 0 | 众泰 | 众泰T600 2016款 1.5T 手动 豪华型 | 2016年5月 | 3.96 | 国4 | 6.8 | 9.42万 |
| 1 | 众泰 | 众泰Z700 2016款 1.8T 手动 典雅型 | 2017年8月 | 0.08 | 国4,国5 | 8.8 | 11.92万 |
| 2 | 众泰 | 大迈X5 2015款 1.5T 手动 豪华型 | 2016年9月 | 0.80 | 国4 | 5.8 | 8.56万 |
| 3 | 众泰 | 众泰T600 2017款 1.5T 手动 精英贺岁版 | 2017年3月 | 0.30 | 国5 | 6.2 | 8.66万 |
| 4 | 众泰 | 众泰T600 2016款 1.5T 手动 旗舰型 | 2016年2月 | 1.70 | 国4 | 7.0 | 11.59万 |
#预览尾五行
second_cars.tail()
| Brand | Name | Boarding_time | Km(W) | Discharge | Sec_price | New_price | |
|---|---|---|---|---|---|---|---|
| 11120 | DS | DS 3 2012款 1.6L 手自一体 风尚版 | 2013年6月 | 1.90 | 欧5 | 10.80 | 23.86万 |
| 11121 | DS | DS 3 2012款 1.6L 手自一体 风尚版 | 2013年6月 | 1.92 | 欧5 | 9.50 | 23.86万 |
| 11122 | DS | DS 5LS 2015款 1.6T 手自一体 THP160雅致版 | 2016年5月 | 1.51 | 国4,国5 | 12.30 | 20.28万 |
| 11123 | DS | DS 5 2015款 1.8T 手自一体 THP200 豪华版 | 2016年3月 | 3.00 | 国4,国5 | 17.99 | 28.65万 |
| 11124 | DS | DS 6 2016款 1.6T 豪华版THP160 | 2017年1月 | 1.37 | 国4,国5 | 16.00 | 24.95万 |
# 数据类型转换
second_cars.Boarding_time = pd.to_datetime(second_cars.Boarding_time, format="%Y年%m月")
# 删除有NaN数据的行 可先在EXCEL里面将暂无更换为NaN,使用缺失值处理中的删除法
# 此步其实已经在做数据的清洗了。
print("数据是否存在缺失值:",any(second_cars.isnull()))
second_cars.dropna()
second_cars.New_price = second_cars.New_price.str[:-1].astype(‘float‘)
second_cars.dtypes
数据是否存在缺失值:True
Brand object
Name object
Boarding_time datetime64[ns]
Km(W) float64
Discharge object
Sec_price float64
New_price float64
dtype: object
# 数值型数据的描述统计
second_cars.describe()
| Km(W) | Sec_price | New_price | |
|---|---|---|---|
| count | 11125.000000 | 11125.000000 | 10984.000000 |
| mean | 6.279603 | 25.671780 | 51.326006 |
| std | 3.479047 | 52.797762 | 79.682066 |
| min | 0.020000 | 0.650000 | 2.910000 |
| 25% | 4.000000 | 5.200000 | 16.050000 |
| 50% | 6.000000 | 10.000000 | 26.690000 |
| 75% | 8.200000 | 23.800000 | 52.210000 |
| max | 34.600000 | 808.000000 | 976.920000 |
# 查看数据偏度和峰度值
import pandas as pd
# 挑出数值型变量
num_variables = second_cars.columns[second_cars.dtypes != ‘object‘][1:]
print(num_variables)
# 自定义函数, 计算偏度和峰度
def skew_kur(x):
skewness = x.skew()
kurtsis = x.kurt()
#返回偏度值和峰值
return pd.Series([skewness,kurtsis],index = ([‘Skew‘,‘kurt‘]))
#运用apply方法
second_cars[num_variables].apply(func = skew_kur,axis =0)
Index([‘Km(W)‘, ‘Sec_price‘, ‘New_price‘], dtype=‘object‘)
| Km(W) | Sec_price | New_price | |
|---|---|---|---|
| Skew | 0.815231 | 6.270313 | 4.996912 |
| kurt | 2.361091 | 54.719769 | 33.519911 |
这三个变量都属于右偏(因为偏度值均大于0),而且三个变量也是尖峰的(因为峰度值也都大于0)。在自定义函数中,运用到了计算偏度的skew方法和计算峰度的kurt方法,然后将计算结果组合到序列中;最后使用apply方法,该方法的目的就是对指定轴(axis=0,即垂直方向的各列)进行统计运算(运算函数即自定义函数)。
# 离散型变量的描述
second_cars.describe(include=[‘object‘])
| Brand | Name | Discharge | |
|---|---|---|---|
| count | 11125 | 11125 | 11125 |
| unique | 104 | 4462 | 34 |
| top | 别克 | 经典全顺 2010款 柴油 短轴 多功能 中顶 6座 | 国4 |
| freq | 1347 | 126 | 4296 |
# 离散变量的频次统计
Freq = second_cars.Brand.value_counts()
Freq_ratio = Freq/second_cars.shape[0]
Freq_df = pd.DataFrame({‘频次‘:Freq,‘频率‘:Freq_ratio})
Freq_df.head()
| 频次 | 频率 | |
|---|---|---|
| 别克 | 1347 | 0.121079 |
| 大众 | 989 | 0.088899 |
| 奔驰 | 864 | 0.077663 |
| 宝马 | 749 | 0.067326 |
| 奥迪 | 748 | 0.067236 |
Freq2 = second_cars.Discharge.value_counts()
Freq_ratio2 = Freq2 / second_cars.shape[0]
Freq_df2 = pd.DataFrame({‘频次‘:Freq2,‘频率‘:Freq_ratio2})
Freq_df2.head()
| 频次 | 频率 | |
|---|---|---|
| 国4 | 4296 | 0.386157 |
| 欧4 | 1876 | 0.168629 |
| 欧5 | 1132 | 0.101753 |
| 国4,国5 | 843 | 0.075775 |
| 国3 | 798 | 0.071730 |
Freq2 = second_cars.Discharge.value_counts()
Freq_ratio2 = Freq2 / second_cars.shape[0]
Freq_df2 = pd.DataFrame({‘频次‘:Freq2,‘频率‘:Freq_ratio2})
# 上面的标准排量国4、欧4等,是数据框的索引,可将其置为数据框中的列
Freq_df2.reset_index(inplace=True)
Freq_df2.rename(columns={‘index‘:‘排放量‘},inplace=True)
Freq_df2.head()
| 排放量 | 频次 | 频率 | |
|---|---|---|---|
| 0 | 国4 | 4296 | 0.386157 |
| 1 | 欧4 | 1876 | 0.168629 |
| 2 | 欧5 | 1132 | 0.101753 |
| 3 | 国4,国5 | 843 | 0.075775 |
| 4 | 国3 | 798 | 0.071730 |
今天的学习就先到这里了,Pandas确实不失为一款好的数据处理工具,不仅能够读写txt,csv, Excel,数据库,还提供了数据预处理,数据描述,数据清洗等功能,后续还需不上相关知识。
续见: python 数据分析--数据处理工具Pandas(2).
标签:开头 字段名 学习 三方 ima 文件 空白 com 垂直
原文地址:https://www.cnblogs.com/sinlearn/p/12665734.html