标签:释放 mic OLE article 序列 二次 就会 希尔 链表
Timsort与其他比较排序算法时间复杂度(time complexity)的比较
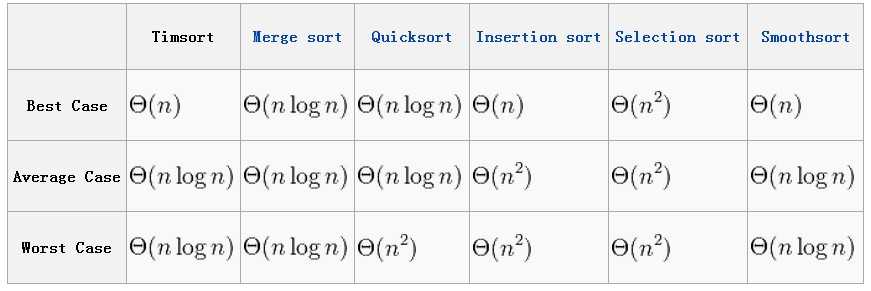
空间复杂度(space complexities)比较
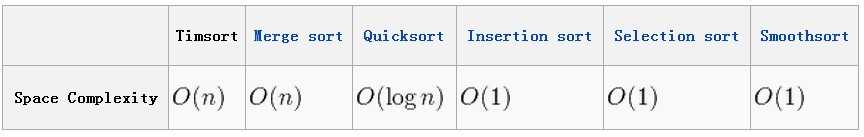
同等硬件条件下,对相同长度的的列表排序,所有时常如下:
# 打印结果:
‘‘‘
quick_sort:0.03600168228149414
sorted:0.003000020980834961
sorted:0.003000020980834961
bubble_sort:11.830676555633545
select_sort:7.196411609649658
insert_sort:6.566375494003296
shell_sort:0.06900382041931152
count_sort:14.809847116470337
merge_sort: 0.06600356101989746
‘‘‘
内置数据类型list的方法sort(),内置函数sorted()
这个的底层实现就是归并排序,只是使用了Python无法编写的底层实现,从而避免了Python本身附加的大量开销,速度比我们自己写的归并排序要快很多(10~20倍),所以说我们一般排序都尽量使用sorted和sort
# Python内置函数sorted()
li = [random.randint(0,100000) for i in range(10000)]
start = time.time()
sorted(li)
print(‘sorted:%s‘ % (time.time() - start))
# python内置数据类型list.sort()
li = [random.randint(0,100000) for i in range(10000)]
start = time.time()
li.sort()
print(‘sorted:%s‘ % (time.time() - start))
‘‘‘
sorted:0.003000020980834961
sorted:0.003000020980834961
‘‘‘
# 冒泡排序
# 最坏的时间复杂度是:(O(n^2)),最优的时间复杂度是:O(n) 有序的列表在内层循环一趟就就return了。
def bubble_sort(l):
for i in range(len(l)-1):
# 定一个标志位,做一个排序的优化。如果在循环第一趟的时候,
# 发现列表是一个有序的列表,就不会走内层循环里面的if条件
# 判断里面的代码,进行交换数字,flag标志位就不会被置换
# 成False,进而走内层循环外面的if判断,终止整个函数的运行。
flag = True
for j in range(len(l)-i-1):
if l[j] > l[j+1]:
l[j],l[j+1] = l[j+1],l[j]
flag = False
if flag:
return
# 冒泡排序
li = [random.randint(0,100000) for i in range(10000)]
start = time.time()
bubble_sort(li)
print(‘bubble_sort:%s‘ % (time.time() - start))
‘‘‘
bubble_sort:11.830676555633545
‘‘‘
# 选择排序
def select_sort(l):
for i in range(len(l)):
minloc = i
for j in range(i+1,len(l)):
if l[j] < l[minloc]:
l[j],l[minloc] = l[minloc],l[j]
# 选择排序
li = [random.randint(0,100000) for i in range(10000)]
start = time.time()
select_sort(li)
print(‘select_sort:%s‘ % (time.time() - start))
‘‘‘
select_sort:7.196411609649658
‘‘‘
# 插入排序
# 时间复杂度 O(n^2)
def insert_sort(l):
for i in range(1,len(l)):
j = i-1
temp = l[i]
while j >= 0 and l[j] > temp:
l[j+1] = l[j]
j = j-1
l[j+1] = temp
# l=[5,7,4,6,3,1,2,9,8]
# insert_sort(l)
# print(l)
# 插入排序
li = [random.randint(0,100000) for i in range(10000)]
start = time.time()
insert_sort(li)
print(‘insert_sort:%s‘ % (time.time() - start))
‘‘‘
insert_sort:6.566375494003296
‘‘‘
def partition(l,left,right):
tmp = l[left]
while left < right:
while left < right and l[right] >= tmp:
right = right - 1
l[left] = l[right]
while left < right and l[left] <= tmp:
left =left + 1
l[right] = l[left]
l[left] = tmp
return left
#快速排序
# 时间复杂度:O(nlogn)
def quick_sort(l,left,right):
if left < right:
mid = partition(l,left,right)
quick_sort(l,left,mid-1)
quick_sort(l,mid+1,right)
# 快排
li = [random.randint(0,100000) for i in range(10000)]
start = time.time()
quick_sort(li, 0, len(li)-1)
print(‘quick_sort:%s‘ % (time.time() - start))
‘‘‘
quick_sort:0.03600168228149414
‘‘‘
# 希尔排序
‘‘‘
希尔排序是一种分组插入排序算法
首先取一个整数d1=n/2,将元素分为d1个组,魅族相邻元素之间的距离为d1,在各组内进行直接插入排序;
取第二个整数d2=d1/2,重复上述分组排序过程,直到d1=1,即所有元素在同一组内进行直接插入排序。
希尔排序每趟并不使某些元素有序,而是使整体数据越来越接近有序;最后一趟排序使得所有数据有序。
‘‘‘
def shell_sort(l):
gap = len(l) // 2
while gap > 0:
for i in range(gap, len(l)):
tmp = l[i]
j = i - gap
while j >= 0 and tmp < l[j]:
l[j + gap] = l[j]
j -= gap
l[j + gap] = tmp
gap //= 2
# 希尔排序
li = [random.randint(0,100000) for i in range(10000)]
start = time.time()
shell_sort(li)
print(‘shell_sort:%s‘ % (time.time() - start))
‘‘‘
shell_sort:0.06900382041931152
‘‘‘
# 计数排序
def count_sort(l):
n = len(l)
res = [None] * n
# 首次循环遍历, 每个列表的数都统计
for i in range(n):
# p 表示 a[i] 大于列表其他数 的次数
p = 0
# q 表示 等于 a[i] 的次数
q = 0
# 二次循环遍历, 列表中的每个数都和首次循环的数比较
for j in range(n):
if l[i] > l[j]:
p += 1
elif l[i] == l[j]:
q += 1
for k in range(p, p+q): # q表示 相等的次数,就表示, 从 P 开始索引后, 连续 q 次,都是同样的 数
res[k] = l[i]
return res
# 计数排序
li = [random.randint(0,100000) for i in range(10000)]
start = time.time()
count_sort(li)
print(‘count_sort:%s‘ % (time.time() - start))
‘‘‘
count_sort:14.809847116470337
‘‘‘
归并排序仍然是利用完全二叉树实现,它是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列。
基本过程:假设初始序列含有n个记录,则可以看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到n/2个长度为2或1的有序子序列,再两两归并,最终得到一个长度为n的有序序列为止,这称为2路归并排序。
下面的截图来自《大话数据结构》相关章节,便于理解整个代码的实现过程。
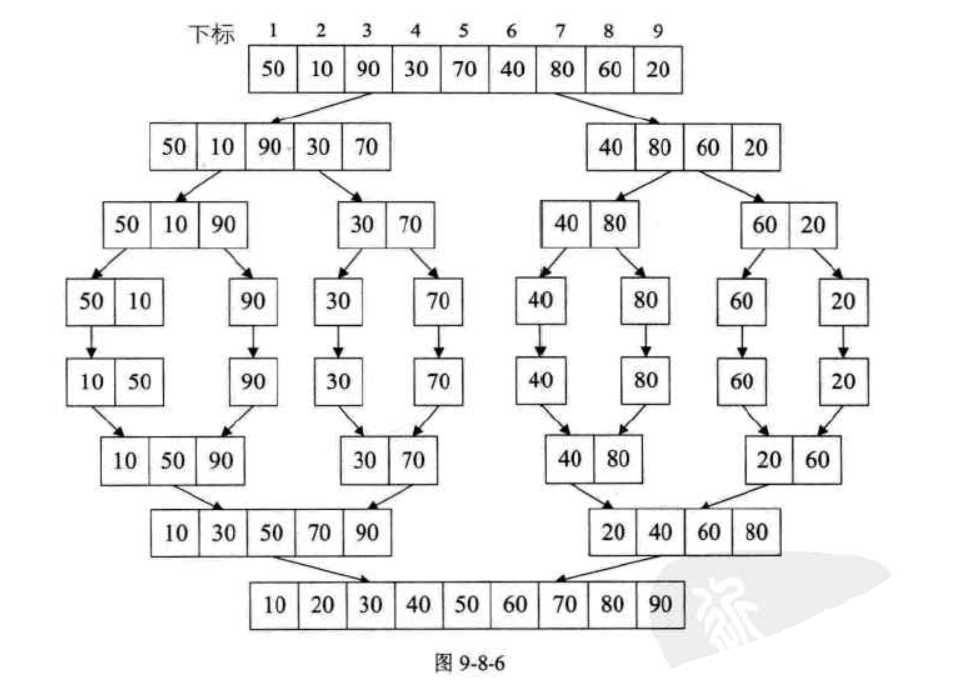
图中主要表明了实例代码中的两部分,分别为原始序列的拆分和合并两部分。
# 归并排序
def merge_sort(lst):
if len(lst) <= 1:
return lst # 从递归中返回长度为1的序列
middle = len(lst) // 2
left = merge_sort(lst[:middle]) # 通过不断递归,将原始序列拆分成n个小序列
right = merge_sort(lst[middle:])
return merge(left, right)
def merge(left, right):
i, j = 0, 0
result = []
while i < len(left) and j < len(right): # 比较传入的两个子序列,对两个子序列进行排序
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:]) # 将排好序的子序列合并
result.extend(right[j:])
return result
# 归并排序
li = [random.randint(0, 100000) for i in range(10000)]
start = time.time()
lst = merge_sort(li)
print("merge_sort:", time.time() - start)
‘‘‘
merge_sort: 0.06600356101989746
‘‘‘
列表查找:从列表中查找指定元素
? 输入:列表、待查找元素
? 输出:元素下标或为查找到元素
顺序查找:
? 从列表的第一个元素开始,顺序进行搜索,直到找到为止。
二分查找:
? 从有序列表的候选区data[0:n]开始,通过对待查找的值与候选区中间值的比较,可以使候选区减少一半。
# 二分查找
malloc()到底从哪里得到了内存空间?
答案是从堆里面获得空间。也就是说函数返回的指针是指向堆里面的一块内存。
? ? ? 操作系统中有一个记录空闲内存地址的链表。当操作系统收到程序的申请时,就会遍历该链表,然后就寻找第一个空间大于所申请空间的堆结点,然后就将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
? ? ?malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表(Free List)。调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块(根据不同的算法而定(将最先找到的不小于申请的大小内存块分配给请求者,将最合适申请大小的空闲内存分配给请求者,或者是分配最大的空闲块内存块)。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。
? ? ?调用free函数时,它将用户释放的内存块连接到空闲链上。到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。如果无法获得符合要求的内存块,malloc函数会返回NULL指针,因此在调用malloc动态申请内存块时,一定要进行返回值的判断。
在此也要说明就是因为new和malloc需要符合大众的申请内存空间的要求,针对泛型提供的,分配内存设计到分配算法和查找,此外还要避免内存碎片,所以其效率比较低下,因此有时程序猿会自己重写new和delete,或者创建一个内存池来管理内存,提高程序运行的效率。
转至:https://blog.csdn.net/m0_37631322/article/details/81777855
1.链表是什么
链表是一种上一个元素的引用指向下一个元素的存储结构,链表通过指针来连接元素与元素;
链表是线性表的一种,所谓的线性表包含顺序线性表和链表,顺序线性表是用数组实现的,在内存中有顺序排列,通过改变数组大小实现。而链表不是用顺序实现的,用指针实现,在内存中不连续。意思就是说,链表就是将一系列不连续的内存联系起来,将那种碎片内存进行合理的利用,解决空间的问题。
所以,链表允许插入和删除表上任意位置上的节点,但是不允许随即存取。链表有很多种不同的类型:单向链表、双向链表及循环链表。
2.单向链表

单向链表包含两个域,一个是信息域,一个是指针域。也就是单向链表的节点被分成两部分,一部分是保存或显示关于节点的信息,第二部分存储下一个节点的地址,而最后一个节点则指向一个空值。
3.双向链表

从上图可以很清晰的看出,每个节点有2个链接,一个是指向前一个节点(当此链接为第一个链接时,指向的是空值或空列表),另一个则指向后一个节点(当此链接为最后一个链接时,指向的是空值或空列表)。意思就是说双向链表有2个指针,一个是指向前一个节点的指针,另一个则指向后一个节点的指针。
4.循环链表
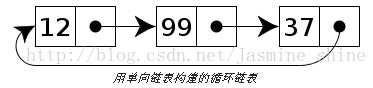
循环链表就是首节点和末节点被连接在一起。循环链表中第一个节点之前就是最后一个节点,反之亦然。
5.数组和链表的区别?
不同:链表是链式的存储结构;数组是顺序的存储结构。
链表通过指针来连接元素与元素,数组则是把所有元素按次序依次存储。
链表的插入删除元素相对数组较为简单,不需要移动元素,且较为容易实现长度扩充,但是寻找某个元素较为困难;
数组寻找某个元素较为简单,但插入与删除比较复杂,由于最大长度需要再编程一开始时指定,故当达到最大长度时,扩充长度不如链表方便。
相同:两种结构均可实现数据的顺序存储,构造出来的模型呈线性结构。
6.链表的应用、代码实践
约瑟夫问题:
传说在公园1世纪的犹太战争中,犹太约瑟夫是公元一世纪著名的历史学家。在罗马人占领乔塔帕特后,39 个犹太人与约瑟夫及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被敌人俘虏,于是决定了一个流传千古的自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报到第3人该人就必须自杀,然后再由下一个人重新报数,直到所有人都自杀身亡为止。然而约瑟夫和他的朋友并不想遵从这个约定,约瑟夫要他的朋友先假装遵从,他将朋友与自己安排在第_个和第_个位置,于是逃过了这场死亡游戏,你知道安排在了第几个嘛?
针对以上问题,使用单向循环链表的方式求解:
//节点类
function Node(elemnt) {
this.item = elemnt;
this.next = null;
}
//循环列表需要修改一下构造函数,和遍历时候的判断条件
//构造函数如下;希望从后向前遍历,又不想要建立双向链表,就使用循环链表。
function Llist() {
this.head = new Node("1");
this.head.next = this.head;
this.remove = remove;
this.insert = insert;
this.find = find;
this.display = display;
//..........
}
function find(number) {
var curr = this.head;
while (curr.item != number) {
curr = curr.next;
}
return curr;
}
function insert(element, newElement) {
var preNode = this.find(element);
var current = new Node(newElement);
current.next = preNode.next;
preNode.next = current;
}
function remove() {
var current = this.head;
console.log("remove");
//跳过两个,杀死一个
while(current.next.next != null && current.item!=current.next.next.item){
var temp = current.next.next;
current.next.next = temp.next;
current = temp.next;
temp.next = null;
}
return current;
}
function display(flag,current) {
var crr = this.head;
if(flag){
while(crr.next.item!="1"){
console.log(crr.item);
crr=crr.next;
}
}else{ //最后只剩两个直接输出
console.log(current.item);
console.log(current.next.item);
}
}
var Clist = new Llist();
//输入排序
for (var i = 1; i < 41; i++){
Clist.insert(i.toString(),(i + 1).toString());
}
//先输出所有
Clist.display(1,null);
//通过remove返回最后杀死后的结果其中一个节点
Clist.display(0,Clist.remove()); //16,31
组织代码的方式要学习体会;
7.自我理解
1)数组便于查询和修改,但是不方便新增和删除
2)链表适合新增和删除,但是不适合查询,根据业务情况使用合适的数据结构和算法是在大数据量和高并发时必须要考虑的问题
标签:释放 mic OLE article 序列 二次 就会 希尔 链表
原文地址:https://www.cnblogs.com/zhangchaocoming/p/12670550.html