标签:mat name 关闭 参数 二分 内容 format 手工注入 sch
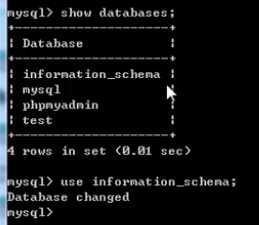
元数据库:information——schema其中存储着其他所有数据库的信息
其中的表非常多
schemata:存放所有数据库的名字
tables:用于存放所有数据表的名字
columns:存放所有字段的名字
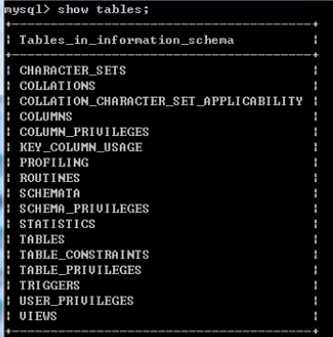
这些表里面存放的信息非常多,如果用select * from tables; 查询会出现非常多劫过而且很杂乱 所以不使用这种查询
discribe table;查看table中的字段
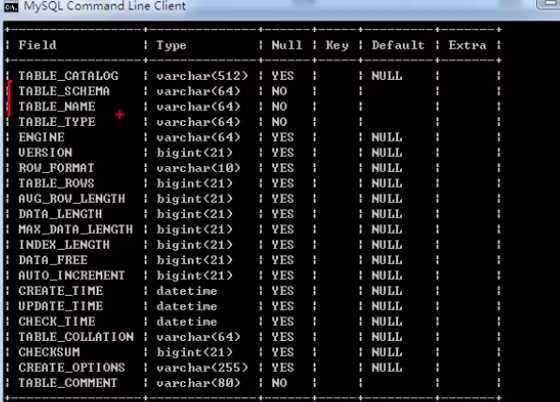
其中有两个固定的字段:table_name(存放表的名字)table_schema(存放数据库的名字)
查看test数据库中有哪些表:select table_name from information_schema.tables where table_schema= "test";
查看hack数据表中包含了哪些字段:select column_name from information_schema.columns where table_name= "hack";
下面是跟着视频做的实验

npmserv必须放在根目录下解压,并且关闭其他的使用80端口的软件(实验环境win2003)
打开政府网站(虚拟机的ip)
找到一个参数传递的页面判断是否为注入点:后面加and1=1(页面显示正常)and1-2(页面显示不正常)就是典型的注入点。
使用order by x(x位数字)来猜测字段(使用二分法)实验中当order by 5显示正常,order by 6 显示不正常:所以字段数量为5
然后使用联合查询 union select 1 ,2,3,4,5做一个联合查询

后面不需要指定表的名字(与access不同的地方)然后页面就会显示可显字段

在url和联合查询中间加上and1=2,因为1=2不成立所以前面的内容就不会显示,只会显示后面的联合查询内容,如图:

现在我们知道2,3为可显字段,就可以在2,3的位置上进行操作,比如查看mysql版本:version()


这样就会在2的位置上显示mysql的版本,为什么要关心版本,因为开头的元数据库只有5.0以后的版本才有,大部分都是5.0以后的

接下来就可以显示当前的数据库和当前用户

再利用这句话来查看有哪些表

在table_ name 旁边加上1345 因为23才为可显字段

group_concat()函数可以显示所有内容不会只显示一个:group_concat(table_name)
 其中的表,很明显admin使我们要的
其中的表,很明显admin使我们要的

再根据这句话来查询有哪些字段

步骤和上面爆破表相似,得到username和password两个字段,然后再查询两个字段的内容就行了

标签:mat name 关闭 参数 二分 内容 format 手工注入 sch
原文地址:https://www.cnblogs.com/noob199/p/12683315.html