标签:cluster new t 地址 之间 prope 分布 更新 max 可靠
Kafka是一个开源的分布式消息引擎/消息中间件,同时Kafka也是一个流处理平台。Kakfa支持以发布/订阅的方式在应用间传递消息,同时并基于消息功能添加了Kafka Connect、Kafka Streams以支持连接其他系统的数据(Elasticsearch、Hadoop等)
Kafka最核心的最成熟的还是他的消息引擎,所以Kafka大部分应用场景还是用来作为消息队列削峰平谷。另外,Kafka也是目前性能最好的消息中间件。
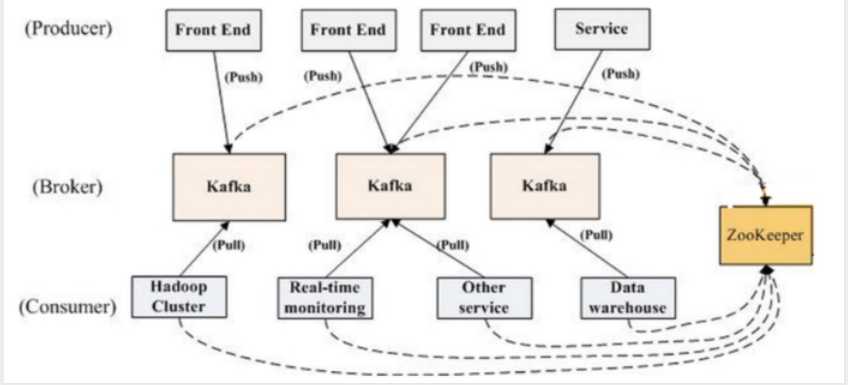
在Kafka集群(Cluster)中,一个Kafka节点就是一个Broker,消息由Topic来负载,可以存储在1个或多个Partition中,发布消息的应用为Producer、消费消息的应用为Consumer,多个Consumer可以促成Consumer Group共同消费一个Topic中的消息。
Broker: Kafka节点
Topic: 主题,用来承载消息
Partition: 分区,用于主题分片存储
Producer: 生产者,向主题发布消息的应用
Consumer: 消费者,从主题订阅消息的应用
Consumer Group: 消费者组,由多个消费者组成.
常用命令:
kafka-server-start.sh //用于启动服务
kafka-console-consumer.sh //常用于测试
kafka-console-producer.sh //常用语测试
kafka-topics.sh //常用
用法:> bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*
这个命令后面可以有多个参数,第一个是可选参数,该参数可以让当前命令以后台服务方式执行,第二个必须是 Kafka 的配置文件。后面还可以有多个--override开头的参数,其中的property可以是Broker Configs中提供的所有参数。这些额外的参数会覆盖配置文件中的设置。
> bin/kafka-server-start.sh -daemon config/server.properties --override broker.id=0 --override log.dirs=/tmp/kafka-logs-1 --override listeners=PLAINTEXT://:9092 --override advertised.listeners=PLAINTEXT://192.168.16.150:9092
> bin/kafka-server-start.sh -daemon config/server.properties --override broker.id=1 --override log.dirs=/tmp/kafka-logs-2 --override listeners=PLAINTEXT://:9093 --override advertised.listeners=PLAINTEXT://192.168.16.150:9093
上面这种用法只是用于演示,真正要启动多个Broker 应该针对不同的 Broker 创建相应的 server.properties 配置。
这个命令只是简单的将消息输出到标准输出中,该命令支持的参数如下。
option Description
------ -----------
--blacklist <String: blacklist> Blacklist of topics to exclude from
consumption.
--bootstrap-server <String: server to REQUIRED (unless old consumer is
connect to> used): The server to connect to.
--consumer-property <String: A mechanism to pass user-defined
consumer_prop> properties in the form key=value to
the consumer.
--consumer.config <String: config file> Consumer config properties file. Note
that [consumer-property] takes
precedence over this config.
--csv-reporter-enabled If set, the CSV metrics reporter will
be enabled
--delete-consumer-offsets If specified, the consumer path in
zookeeper is deleted when starting up
--enable-systest-events Log lifecycle events of the consumer
in addition to logging consumed
messages. (This is specific for
system tests.)
--formatter <String: class> The name of a class to use for
formatting kafka messages for
display. (default: kafka.tools.
DefaultMessageFormatter)
--from-beginning If the consumer does not already have
an established offset to consume
from, start with the earliest
message present in the log rather
than the latest message.
--key-deserializer <String:
deserializer for key>
--max-messages <Integer: num_messages> The maximum number of messages to
consume before exiting. If not set,
consumption is continual.
--metrics-dir <String: metrics If csv-reporter-enable is set, and
directory> this parameter isset, the csv
metrics will be outputed here
--new-consumer Use the new consumer implementation.
This is the default.
--offset <String: consume offset> The offset id to consume from (a non-
negative number), or ‘earliest‘
which means from beginning, or
‘latest‘ which means from end
(default: latest)
--partition <Integer: partition> The partition to consume from.
--property <String: prop> The properties to initialize the
message formatter.
--skip-message-on-error If there is an error when processing a
message, skip it instead of halt.
--timeout-ms <Integer: timeout_ms> If specified, exit if no message is
available for consumption for the
specified interval.
--topic <String: topic> The topic id to consume on.
--value-deserializer <String:
deserializer for values>
--whitelist <String: whitelist> Whitelist of topics to include for
consumption.
--zookeeper <String: urls> REQUIRED (only when using old
consumer): The connection string for
the zookeeper connection in the form
host:port. Multiple URLS can be
given to allow fail-over.
--bootstrap-server 必须指定,通常--topic也要指定查看的主题。如果想要从头查看消息,还可以指定--from-beginning参数。
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
还可以通过下面的命令指定分区查看:
>> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning --partition 0
这个命令可以将文件或标准输入的内容发送到Kafka集群。该命令参数如下。
Option Description
------ -----------
--batch-size <Integer: size> Number of messages to send in a single
batch if they are not being sent
synchronously. (default: 200)
--broker-list <String: broker-list> REQUIRED: The broker list string in
the form HOST1:PORT1,HOST2:PORT2.
--compression-codec [String: The compression codec: either ‘none‘,
compression-codec] ‘gzip‘, ‘snappy‘, or ‘lz4‘.If
specified without value, then it
defaults to ‘gzip‘
--key-serializer <String: The class name of the message encoder
encoder_class> implementation to use for
serializing keys. (default: kafka.
serializer.DefaultEncoder)
--line-reader <String: reader_class> The class name of the class to use for
reading lines from standard in. By
default each line is read as a
separate message. (default: kafka.
tools.
ConsoleProducer$LineMessageReader)
--max-block-ms <Long: max block on The max time that the producer will
send> block for during a send request
(default: 60000)
--max-memory-bytes <Long: total memory The total memory used by the producer
in bytes> to buffer records waiting to be sent
to the server. (default: 33554432)
--max-partition-memory-bytes <Long: The buffer size allocated for a
memory in bytes per partition> partition. When records are received
which are smaller than this size the
producer will attempt to
optimistically group them together
until this size is reached.
(default: 16384)
--message-send-max-retries <Integer> Brokers can fail receiving the message
for multiple reasons, and being
unavailable transiently is just one
of them. This property specifies the
number of retires before the
producer give up and drop this
message. (default: 3)
--metadata-expiry-ms <Long: metadata The period of time in milliseconds
expiration interval> after which we force a refresh of
metadata even if we haven‘t seen any
leadership changes. (default: 300000)
--old-producer Use the old producer implementation.
--producer-property <String: A mechanism to pass user-defined
producer_prop> properties in the form key=value to
the producer.
--producer.config <String: config file> Producer config properties file. Note
that [producer-property] takes
precedence over this config.
--property <String: prop> A mechanism to pass user-defined
properties in the form key=value to
the message reader. This allows
custom configuration for a user-
defined message reader.
--queue-enqueuetimeout-ms <Integer: Timeout for event enqueue (default:
queue enqueuetimeout ms> 2147483647)
--queue-size <Integer: queue_size> If set and the producer is running in
asynchronous mode, this gives the
maximum amount of messages will
queue awaiting sufficient batch
size. (default: 10000)
--request-required-acks <String: The required acks of the producer
request required acks> requests (default: 1)
--request-timeout-ms <Integer: request The ack timeout of the producer
timeout ms> requests. Value must be non-negative
and non-zero (default: 1500)
--retry-backoff-ms <Integer> Before each retry, the producer
refreshes the metadata of relevant
topics. Since leader election takes
a bit of time, this property
specifies the amount of time that
the producer waits before refreshing
the metadata. (default: 100)
--socket-buffer-size <Integer: size> The size of the tcp RECV size.
(default: 102400)
--sync If set message send requests to the
brokers are synchronously, one at a
time as they arrive.
--timeout <Integer: timeout_ms> If set and the producer is running in
asynchronous mode, this gives the
maximum amount of time a message
will queue awaiting sufficient batch
size. The value is given in ms.
(default: 1000)
--topic <String: topic> REQUIRED: The topic id to produce
messages to.
--value-serializer <String: The class name of the message encoder
encoder_class> implementation to use for
serializing values. (default: kafka.
serializer.DefaultEncoder)
其中 --broker-list 和 --topic 是两个必须提供的参数。
使用标准输入方式。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
从文件读取:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test < file-input.txt
相比上面几个偶尔使用的命令来说,kafka-topics.sh 相对就比较重要。该命令包含以下参数。
Create, delete, describe, or change a topic.
Option Description
------ -----------
--alter Alter the number of partitions,
replica assignment, and/or
configuration for the topic.
--config <String: name=value> A topic configuration override for the
topic being created or altered.The
following is a list of valid
configurations:
cleanup.policy
compression.type
delete.retention.ms
file.delete.delay.ms
flush.messages
flush.ms
follower.replication.throttled.
replicas
index.interval.bytes
leader.replication.throttled.replicas
max.message.bytes
message.format.version
message.timestamp.difference.max.ms
message.timestamp.type
min.cleanable.dirty.ratio
min.compaction.lag.ms
min.insync.replicas
preallocate
retention.bytes
retention.ms
segment.bytes
segment.index.bytes
segment.jitter.ms
segment.ms
unclean.leader.election.enable
See the Kafka documentation for full
details on the topic configs.
--create Create a new topic.
--delete Delete a topic
--delete-config <String: name> A topic configuration override to be
removed for an existing topic (see
the list of configurations under the
--config option).
--describe List details for the given topics.
--disable-rack-aware Disable rack aware replica assignment
--force Suppress console prompts
--help Print usage information.
--if-exists if set when altering or deleting
topics, the action will only execute
if the topic exists
--if-not-exists if set when creating topics, the
action will only execute if the
topic does not already exist
--list List all available topics.
--partitions <Integer: # of partitions> 正在创建或更改主题的分区数
(警告:如果为具有密钥的主题
(分区)增加了分区
消息的逻辑或排序将受到影响
--replica-assignment <String: A list of manual partition-to-broker
broker_id_for_part1_replica1 : assignments for the topic being
broker_id_for_part1_replica2 , created or altered.
broker_id_for_part2_replica1 :
broker_id_for_part2_replica2 , ...>
--replication-factor <Integer: 正在创建的主题中每个分区的复制因子。
replication factor>
--topic <String: topic> The topic to be create, alter or
describe. Can also accept a regular
expression except for --create option
--topics-with-overrides if set when describing topics, only
show topics that have overridden
configs
--unavailable-partitions if set when describing topics, only
show partitions whose leader is not
available
--under-replicated-partitions if set when describing topics, only
show under replicated partitions
--zookeeper <String: urls> REQUIRED: The connection string for
the zookeeper connection in the form
host:port. Multiple URLS can be
given to allow fail-over.
下面是几种常用的 topic 命令。
描述主题的配置
bin/kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type topics --entity-name test_topic
设置保留时间
# Deprecated way
bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic test_topic --config retention.ms=1000
# Modern way
bin/kafka-configs.sh --zookeeper localhost:2181 --alter --entity-type topics --entity-name test_topic --add-config retention.ms=1000
如果您需要删除主题中的所有消息,则可以利用保留时间。首先将保留时间设置为非常低(1000 ms),等待几秒钟,然后将保留时间恢复为上一个值。
注意:默认保留时间为24小时(86400000毫秒)。
删除主题
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic test_topic
注意:需要在Broker的配置文件server.properties中配置 delete.topic.enable=true 才能删除主题。
主题信息
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test_topic
添加分区
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic test_topic --partitions 3
创建主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic test_topic
列出主题
bin/kafka-topics.sh --list --zookeeper localhost:2181
topic 相关内容来源:http://ronnieroller.com/kafka/cheat-sheet
命令那么多,怎么记?
Kafka 的命令行工具提供了非常丰富的提示信息,所以只需要记住上面大概的几个用法,知道怎么写就行。当需要用到某个命令时,通过命令提示进行操作。
比如说,如何使用 kafka-configs.sh 查看主题(Topic)的配置?
首先,在命令行中输入bin/kafka-configs.sh,然后或输出下面的命令提示信息。
Add/Remove entity config for a topic, client, user or broker
Option Description
------ -----------
--add-config <String> Key Value pairs of configs to add. Square brackets
can be used to group values which contain commas:
‘k1=v1,k2=[v1,v2,v2],k3=v3‘. The following is a
list of valid configurations: For entity_type
‘topics‘:
cleanup.policy
compression.type
delete.retention.ms
file.delete.delay.ms
flush.messages
flush.ms
follower.replication.throttled.replicas
index.interval.bytes
leader.replication.throttled.replicas
max.message.bytes
message.format.version
message.timestamp.difference.max.ms
message.timestamp.type
min.cleanable.dirty.ratio
min.compaction.lag.ms
min.insync.replicas
preallocate
retention.bytes
retention.ms
segment.bytes
segment.index.bytes
segment.jitter.ms
segment.ms
unclean.leader.election.enable
For entity_type ‘brokers‘:
follower.replication.throttled.rate
leader.replication.throttled.rate
For entity_type ‘users‘:
producer_byte_rate
SCRAM-SHA-256
SCRAM-SHA-512
consumer_byte_rate
For entity_type ‘clients‘:
producer_byte_rate
consumer_byte_rate
Entity types ‘users‘ and ‘clients‘ may be specified
together to update config for clients of a
specific user.
--alter Alter the configuration for the entity.
--delete-config <String> config keys to remove ‘k1,k2‘
--describe List configs for the given entity.
--entity-default Default entity name for clients/users (applies to
corresponding entity type in command line)
--entity-name <String> Name of entity (topic name/client id/user principal
name/broker id)
--entity-type <String> Type of entity (topics/clients/users/brokers)
--force Suppress console prompts
--help Print usage information.
--zookeeper <String: urls> REQUIRED: The connection string for the zookeeper
connection in the form host:port. Multiple URLS
can be given to allow fail-over.
从第一行可以看到这个命令可以修改 topic, client, user 或 broker 的配置。
如果要设置 topic,就需要设置 entity-type 为topics,输入如下命令:
> bin/kafka-configs.sh --entity-type topics
Command must include exactly one action: --describe, --alter
命令提示需要指定一个操作(不只是上面提示的两个操作),增加--describe试试:
> bin/kafka-configs.sh --entity-type topics --describe
[root@localhost kafka_2.11-0.10.2.1]# bin/kafka-configs.sh --entity-type topics --describe
Missing required argument "[zookeeper]"
继续增加 --zookeeper:
> bin/kafka-configs.sh --entity-type topics --describe --zookeeper localhost:2181
Configs for topic ‘__consumer_offsets‘ are segment.bytes=104857600,cleanup.policy=compact,compression.type=producer
由于没有指定主题名,这里显示了__consumer_offsets的信息。下面指定一个topic试试。
> bin/kafka-configs.sh --entity-type topics --describe --zookeeper localhost:2181 --entity-name test
Configs for topic ‘test‘ are
此时显示了test主题的信息,这里是空。
因为Kafka完善的命令提示,可以很轻松的通过提示信息来进行下一步操作,运用熟练后,基本上很快就能实现自己想要的命令。
kafka的配置分为 broker、producter、consumer三个不同的配置
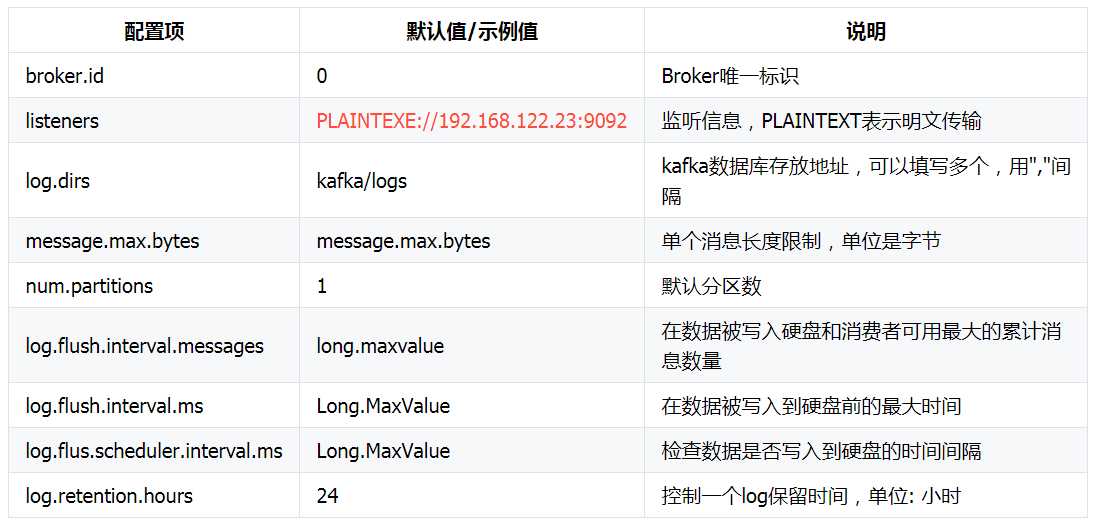
最为核心的三个配置 broker.id、log.dir、zookeeper.connect 。
------------------------------------------- 系统 相关 -------------------------------------------
##每一个broker在集群中的唯一标示,要求是正数。在改变IP地址,不改变broker.id的话不会影响consumers
broker.id =1
##kafka数据的存放地址,多个地址的话用逗号分割 /tmp/kafka-logs-1,/tmp/kafka-logs-2
log.dirs = /tmp/kafka-logs
##提供给客户端响应的端口
port =6667
##消息体的最大大小,单位是字节
message.max.bytes =1000000
## broker 处理消息的最大线程数,一般情况下不需要去修改
num.network.threads =3
## broker处理磁盘IO 的线程数 ,数值应该大于你的硬盘数
num.io.threads =8
## 一些后台任务处理的线程数,例如过期消息文件的删除等,一般情况下不需要去做修改
background.threads =4
## 等待IO线程处理的请求队列最大数,若是等待IO的请求超过这个数值,那么会停止接受外部消息,算是一种自我保护机制
queued.max.requests =500
##broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接口上,并将其中之一发送到ZK,一般不设置
host.name
## 打广告的地址,若是设置的话,会提供给producers, consumers,其他broker连接,具体如何使用还未深究
advertised.host.name
## 广告地址端口,必须不同于port中的设置
advertised.port
## socket的发送缓冲区,socket的调优参数SO_SNDBUFF
socket.send.buffer.bytes =100*1024
## socket的接受缓冲区,socket的调优参数SO_RCVBUFF
socket.receive.buffer.bytes =100*1024
## socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
socket.request.max.bytes =100*1024*1024
------------------------------------------- LOG 相关 -------------------------------------------
## topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖
log.segment.bytes =1024*1024*1024
## 这个参数会在日志segment没有达到log.segment.bytes设置的大小,也会强制新建一个segment 会被 topic创建时的指定参数覆盖
log.roll.hours =24*7
## 日志清理策略 选择有:delete和compact 主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖
log.cleanup.policy = delete
## 数据存储的最大时间 超过这个时间 会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据
## log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖
log.retention.minutes=7days
指定日志每隔多久检查看是否可以被删除,默认1分钟
log.cleanup.interval.mins=1
## topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes 。-1没有大小限制
## log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖
log.retention.bytes=-1
## 文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略
log.retention.check.interval.ms=5minutes
## 是否开启日志压缩
log.cleaner.enable=false
## 日志压缩运行的线程数
log.cleaner.threads =1
## 日志压缩时候处理的最大大小
log.cleaner.io.max.bytes.per.second=None
## 日志压缩去重时候的缓存空间 ,在空间允许的情况下,越大越好
log.cleaner.dedupe.buffer.size=500*1024*1024
## 日志清理时候用到的IO块大小 一般不需要修改
log.cleaner.io.buffer.size=512*1024
## 日志清理中hash表的扩大因子 一般不需要修改
log.cleaner.io.buffer.load.factor =0.9
## 检查是否处罚日志清理的间隔
log.cleaner.backoff.ms =15000
## 日志清理的频率控制,越大意味着更高效的清理,同时会存在一些空间上的浪费,会被topic创建时的指定参数覆盖
log.cleaner.min.cleanable.ratio=0.5
## 对于压缩的日志保留的最长时间,也是客户端消费消息的最长时间,同log.retention.minutes的区别在于一个控制未压缩数据,一个控制压缩后的数据。会被topic创建时的指定参数覆盖
log.cleaner.delete.retention.ms =1day
## 对于segment日志的索引文件大小限制,会被topic创建时的指定参数覆盖
log.index.size.max.bytes =10*1024*1024
## 当执行一个fetch操作后,需要一定的空间来扫描最近的offset大小,设置越大,代表扫描速度越快,但是也更好内存,一般情况下不需要搭理这个参数
log.index.interval.bytes =4096
## log文件"sync"到磁盘之前累积的消息条数
## 因为磁盘IO操作是一个慢操作,但又是一个"数据可靠性"的必要手段
## 所以此参数的设置,需要在"数据可靠性"与"性能"之间做必要的权衡.
## 如果此值过大,将会导致每次"fsync"的时间较长(IO阻塞)
## 如果此值过小,将会导致"fsync"的次数较多,这也意味着整体的client请求有一定的延迟.
## 物理server故障,将会导致没有fsync的消息丢失.
log.flush.interval.messages=None
## 检查是否需要固化到硬盘的时间间隔
log.flush.scheduler.interval.ms =3000
## 仅仅通过interval来控制消息的磁盘写入时机,是不足的.
## 此参数用于控制"fsync"的时间间隔,如果消息量始终没有达到阀值,但是离上一次磁盘同步的时间间隔
## 达到阀值,也将触发.
log.flush.interval.ms = None
## 文件在索引中清除后保留的时间 一般不需要去修改
log.delete.delay.ms =60000
## 控制上次固化硬盘的时间点,以便于数据恢复 一般不需要去修改
log.flush.offset.checkpoint.interval.ms =60000
------------------------------------------- TOPIC 相关 -------------------------------------------
## 是否允许自动创建topic ,若是false,就需要通过命令创建topic
auto.create.topics.enable =true
## 一个topic ,默认分区的replication个数 ,不得大于集群中broker的个数
default.replication.factor =1
## 每个topic的分区个数,若是在topic创建时候没有指定的话 会被topic创建时的指定参数覆盖
num.partitions =1
实例 --replication-factor3--partitions1--topic replicated-topic :名称replicated-topic有一个分区,分区被复制到三个broker上。
----------------------------------复制(Leader、replicas) 相关 ----------------------------------
## partition leader与replicas之间通讯时,socket的超时时间
controller.socket.timeout.ms =30000
## partition leader与replicas数据同步时,消息的队列尺寸
controller.message.queue.size=10
## replicas响应partition leader的最长等待时间,若是超过这个时间,就将replicas列入ISR(in-sync replicas),并认为它是死的,不会再加入管理中
replica.lag.time.max.ms =10000
## 如果follower落后与leader太多,将会认为此follower[或者说partition relicas]已经失效
## 通常,在follower与leader通讯时,因为网络延迟或者链接断开,总会导致replicas中消息同步滞后
## 如果消息之后太多,leader将认为此follower网络延迟较大或者消息吞吐能力有限,将会把此replicas迁移
## 到其他follower中.
## 在broker数量较少,或者网络不足的环境中,建议提高此值.
replica.lag.max.messages =4000
##follower与leader之间的socket超时时间
replica.socket.timeout.ms=30*1000
## leader复制时候的socket缓存大小
replica.socket.receive.buffer.bytes=64*1024
## replicas每次获取数据的最大大小
replica.fetch.max.bytes =1024*1024
## replicas同leader之间通信的最大等待时间,失败了会重试
replica.fetch.wait.max.ms =500
## fetch的最小数据尺寸,如果leader中尚未同步的数据不足此值,将会阻塞,直到满足条件
replica.fetch.min.bytes =1
## leader 进行复制的线程数,增大这个数值会增加follower的IO
num.replica.fetchers=1
## 每个replica检查是否将最高水位进行固化的频率
replica.high.watermark.checkpoint.interval.ms =5000
## 是否允许控制器关闭broker ,若是设置为true,会关闭所有在这个broker上的leader,并转移到其他broker
controlled.shutdown.enable =false
## 控制器关闭的尝试次数
controlled.shutdown.max.retries =3
## 每次关闭尝试的时间间隔
controlled.shutdown.retry.backoff.ms =5000
## 是否自动平衡broker之间的分配策略
auto.leader.rebalance.enable =false
## leader的不平衡比例,若是超过这个数值,会对分区进行重新的平衡
leader.imbalance.per.broker.percentage =10
## 检查leader是否不平衡的时间间隔
leader.imbalance.check.interval.seconds =300
## 客户端保留offset信息的最大空间大小
offset.metadata.max.bytes
----------------------------------ZooKeeper 相关----------------------------------
##zookeeper集群的地址,可以是多个,多个之间用逗号分割 hostname1:port1,hostname2:port2,hostname3:port3
zookeeper.connect = localhost:2181
## ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大
zookeeper.session.timeout.ms=6000
## ZooKeeper的连接超时时间
zookeeper.connection.timeout.ms =6000
## ZooKeeper集群中leader和follower之间的同步实际那
zookeeper.sync.time.ms =2000
配置的修改
其中一部分配置是可以被每个topic自身的配置所代替,例如
新增配置
bin/kafka-topics.sh --zookeeper localhost:2181--create --topic my-topic --partitions1--replication-factor1--config max.message.bytes=64000--config flush.messages=1
修改配置
bin/kafka-topics.sh --zookeeper localhost:2181--alter --topic my-topic --config max.message.bytes=128000
删除配置 :
bin/kafka-topics.sh --zookeeper localhost:2181--alter --topic my-topic --deleteConfig max.message.bytes
最为核心的配置是group.id、zookeeper.connect
## Consumer归属的组ID,broker是根据group.id来判断是队列模式还是发布订阅模式,非常重要
group.id
## 消费者的ID,若是没有设置的话,会自增
consumer.id
## 一个用于跟踪调查的ID ,最好同group.id相同
client.id = group id value
## 对于zookeeper集群的指定,可以是多个 hostname1:port1,hostname2:port2,hostname3:port3 必须和broker使用同样的zk配置
zookeeper.connect=localhost:2182
## zookeeper的心跳超时时间,查过这个时间就认为是dead消费者
zookeeper.session.timeout.ms =6000
## zookeeper的等待连接时间
zookeeper.connection.timeout.ms =6000
## zookeeper的follower同leader的同步时间
zookeeper.sync.time.ms =2000
## 当zookeeper中没有初始的offset时候的处理方式 。smallest :重置为最小值 largest:重置为最大值 anythingelse:抛出异常
auto.offset.reset = largest
## socket的超时时间,实际的超时时间是:max.fetch.wait + socket.timeout.ms.
socket.timeout.ms=30*1000
## socket的接受缓存空间大小
socket.receive.buffer.bytes=64*1024
##从每个分区获取的消息大小限制
fetch.message.max.bytes =1024*1024
## 是否在消费消息后将offset同步到zookeeper,当Consumer失败后就能从zookeeper获取最新的offset
auto.commit.enable =true
## 自动提交的时间间隔
auto.commit.interval.ms =60*1000
## 用来处理消费消息的块,每个块可以等同于fetch.message.max.bytes中数值
queued.max.message.chunks =10
## 当有新的consumer加入到group时,将会reblance,此后将会有partitions的消费端迁移到新
## 的consumer上,如果一个consumer获得了某个partition的消费权限,那么它将会向zk注册
##"Partition Owner registry"节点信息,但是有可能此时旧的consumer尚没有释放此节点,
## 此值用于控制,注册节点的重试次数.
rebalance.max.retries =4
## 每次再平衡的时间间隔
rebalance.backoff.ms =2000
## 每次重新选举leader的时间
refresh.leader.backoff.ms
## server发送到消费端的最小数据,若是不满足这个数值则会等待,知道满足数值要求
fetch.min.bytes =1
## 若是不满足最小大小(fetch.min.bytes)的话,等待消费端请求的最长等待时间
fetch.wait.max.ms =100
## 指定时间内没有消息到达就抛出异常,一般不需要改
consumer.timeout.ms = -1
比较核心的配置:metadata.broker.list、request.required.acks、producer.type、serializer.class
## 消费者获取消息元信息(topics, partitions and replicas)的地址,配置格式是:host1:port1,host2:port2,也可以在外面设置一个vip
metadata.broker.list
##消息的确认模式
##0:不保证消息的到达确认,只管发送,低延迟但是会出现消息的丢失,在某个server失败的情况下,有点像TCP
##1:发送消息,并会等待leader 收到确认后,一定的可靠性
## -1:发送消息,等待leader收到确认,并进行复制操作后,才返回,最高的可靠性
request.required.acks =0
## 消息发送的最长等待时间
request.timeout.ms =10000
## socket的缓存大小
send.buffer.bytes=100*1024
## key的序列化方式,若是没有设置,同serializer.class
key.serializer.class
## 分区的策略,默认是取模
partitioner.class=kafka.producer.DefaultPartitioner
## 消息的压缩模式,默认是none,可以有gzip和snappy
compression.codec = none
## 可以针对默写特定的topic进行压缩
compressed.topics=null
## 消息发送失败后的重试次数
message.send.max.retries =3
## 每次失败后的间隔时间
retry.backoff.ms =100
## 生产者定时更新topic元信息的时间间隔 ,若是设置为0,那么会在每个消息发送后都去更新数据
topic.metadata.refresh.interval.ms =600*1000
## 用户随意指定,但是不能重复,主要用于跟踪记录消息
client.id=""
------------------------------------------- 消息模式 相关 -------------------------------------------
## 生产者的类型 async:异步执行消息的发送 sync:同步执行消息的发送
producer.type=sync
## 异步模式下,那么就会在设置的时间缓存消息,并一次性发送
queue.buffering.max.ms =5000
## 异步的模式下 最长等待的消息数
queue.buffering.max.messages =10000
## 异步模式下,进入队列的等待时间 若是设置为0,那么要么进入队列,要么直接抛弃
queue.enqueue.timeout.ms = -1
## 异步模式下,每次发送的最大消息数,前提是触发了queue.buffering.max.messages或是queue.buffering.max.ms的限制
batch.num.messages=200
## 消息体的系列化处理类 ,转化为字节流进行传输
serializer.class= kafka.serializer.DefaultEncoder
转载:原文地址 https://blog.csdn.net/wackycrazy/article/details/47810741
环境:

一、安装JDK环境
cd /usr/local/
rz jdk.tar.gz
tar xvf jdk.tar.gz
#准备java环境变量
vim /etc/profile
export JAVA_HOME=/data/soft/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH
(末尾添加)
. /etc/profile
# 二、下载kafka的tar包并安装
## 2.1 创建应用目录,数据目录
mkdir /data/kafka
mkdir /data/logs/kafka
#下载安装包并解压
cd /usr/local/
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.1/kafka_2.12-2.3.1.tgz
tar xf kafka_2.12-2.3.1.tgz
mv kafka_2.12-2.3.1 kafka
# 三、kafka节点配置
Kafka01(zk1)
cd /usr/kafka/kafka/
vim config/server.properties
21 broker.id=0
31 listeners=PLAINTEXT://zk1:9092
123 zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
Kafka02(zk2)
cd /usr/kafka/kafka/
vim config/server.properties
21 broker.id=1
31 listeners=PLAINTEXT://zk2:9092
Kafka02(zk3)
cd /usr/kafka/kafka/
vim config/server.properties
21 broker.id=2
31 listeners=PLAINTEXT://zk3:9092
# 四、启动服务
#进入kafka根目录
cd /usr/kafka/kafka_2.12-2.3.0/
#启动
**nohup ./bin/kafka-server-start.sh config/server.properties &
# 五、kafka测试
# 5.1 创建topic
./bin/kafka-topics.sh --create --bootstrap-server 192.168.144.131:9092 --replication-factor 3 --partitions 1 --topic test-you-io
#Topic在Kafka01上创建后也会同步到集群中另外两个Broker: Kafka02, Kafka03
# 5.2 查看topic
./bin/kafka-topics.sh --list --bootstrap-server 192.168.144.131:9092
test-ken-io
test-you-io
# 5.3 发送消息
#这里我们向Broker(id=0)的Topic=test-ken-io发送消息
(ZK2) ./bin/kafka-console-producer.sh --broker-list 192.168.144.140:9092 --topic test-zhou-io
test by zhou.io
test by men.io
到另外两台机器消费消息,我们可以看到都能收到ZK2消息,这是因为两个消费的命令是建立了两个不同的Consumer,如果我们启动Consumer指定Consumer Group ID就可以作为一个消费组协同工,1个消息同时只会被一个Consumer消费到.
(ZK1)./bin/kafka-console-consumer.sh --bootstrap-server 192.168.144.131:9092 --topic test-zhou-io --from-beginning
test by zhou.io
test by men.io
(ZK3)./bin/kafka-console-consumer.sh --bootstrap-server 192.168.144.131:9092 --topic test-zhou-io --from-beginning
test by zhou.io
test by men.io
标签:cluster new t 地址 之间 prope 分布 更新 max 可靠
原文地址:https://www.cnblogs.com/wangchengshi/p/12684735.html