标签:效果 解决 运行时 文件 算法 表示 相关 linu 后台服务
在这里简单介绍一些进程调度相关的算法策略,虽然了解这些对于使用Linux来说不会有很大帮助,但是却能帮助我们了解进程调度追求的是什么,它和生活中的很多案例都类似。
进程调度的两个关键性指标是:响应时间和周转时间。
性能和公平在调度算法中往往是矛盾的,优化性能必然会降低公平,追求公平必然会丢失性能,调度算法就在这两者之间进行权衡。
为了一步步推进调度算法,先做几个不现实的假设,在后面会不断的放宽这些假设:
假设现在有A、B、C三个进程同时启动,每个进程总共运行10s。假设首先调度到进程A,再调度到进程B,最后调度到进程C,示意图如图(左)。
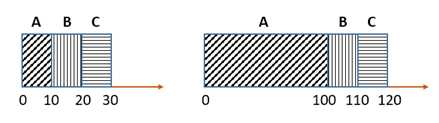
可轻松计算出:
平均周转时间 = (10+20+30)/3=20s
平均响应时间 = (0+10+10)/3=6.67s
现在放宽假设1,不再认为每个进程的执行时长是相等的。假设,进程A执行时长为100秒,进程B和进程C执行时长仍为10秒,示意图如图(右)。那么:
平均周转时间 = (100+110+120)/3=110s
平均响应时间 = (0+100+110)/3=70s
FIFO的缺点已经出现了,如果耗时较少的进程被放在耗时更长的进程之后,那么短进程将做出无谓的等待。
这个现象在生活中很常见,例如超市收银台结账时,如果我们只是买了一件商品,但发现队伍前面有个人的购物车里堆满了商品,我们在心里肯定想让收银员先为我们结账,因为在我们看来,我们的结账速度是非常快的。所以,超市里这种结账方式的效率是非常低的,如果超市里开放一个零散的结账通道,只给那些购物数量少的用户结账,那么就可以提高收银效率,但超市肯定是不会设置这种通道的,因为超市里无法对用户选择哪个收银通道做出限制,用户也不会遵守这种限制。
不过零散结账通道的模式,正是下一种要介绍的调度算法:最短任务优先。
见名知意,最短任务优先(shortest job first)表示最短的进程先执行。
例如,上面的示例,进程A执行100秒,进程B和进程C执行10秒,A最长,所以最后执行。那么SJF调度算法的示意图如图(左):
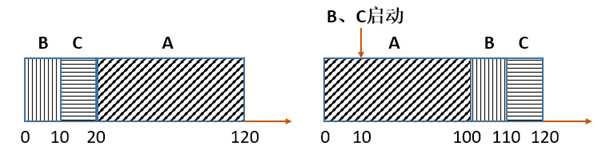
那么:
平均周转时间 = (10+20+120)/3=50s
平均响应时间 = (0+10+20)/3=10s
在目前的假设前提下,这是很好的结果。
但是,如果继续放宽假设2,进程不再同时启动,而是随时启动,那么最糟糕的情况是进程A先启动然后被调度选中,然后再启动进程B和C(假设在10秒的时候启动),这时又回到了最糟糕的状态,进程B和C必须等待耗时最长的进程A执行完成,如图(右)。那么:
平均周转时间 = (100+(110-10)+(120-10))/3=103.3s
平均响应时间 = (0+(100-10)+(110-10))/3=63.3s
于是假设,如果进程是可以抢占的,那么短任务就可以在启动的时候直接运行,而不需要等待耗时长的进程执行完,这是最短完成时间优先(shortest time-to-completion first,STCF)调度算法。
要保证STCF调度算法生效,必须放宽假设3,即不再要求进程一旦被调度选中就必须执行完,而是可以中断,然后由操作系统决定调度哪个进程,对于该算法来说,显然是调度完成时间最短的进程。
所以,FIFO和SJF都是非抢占式的调度算法,而STCF是抢占式的调度算法。

回到STCF调度算法,当运行进程A的时候,在第10秒的时候进程B和进程C启动,STCF调度示意图如图所示。
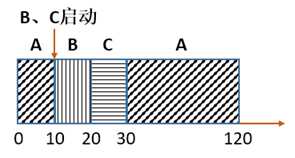
于是计算:
平均周转时间 = (120+(20-10)+(30-10))/3=50s
平均响应时间 = (0+0+10)/3=3.3s
目前为止,该算法已经对两个指标都达到了最佳效果,特别是响应时间大幅减小。这主要归功于抢占式,只要是抢占式的,那么平均响应时间就不会比非抢占的差。
虽然抢占式的最短完成时间优先调度算法已经不错,但对于它的响应时间,其实还能更优化,只需在最短完成时间有限的调度算法上添加一个功能:指定每个进程最多只运行一段固定的时间,调度时轮询每一个进程。也就是轮询(Round-Robin,RR)调度算法。
这段固定的时间长度,就是时间片。要使用时间片的功能,必然需要时钟中断,且时间片的长度必须为时钟周期的倍数,例如时钟中断是每10秒中断一次,那么时间片可以是10s、20s、100s等。
仍然接前面最短完成时间优先调度的例子,但现在添加2s的时间片并假设A、B、C这3个进程同时启动,那么采用RR调度算法的示意图如图。

计算:
平均周转时间 = (120+(30-2)+30)/3=59.3s
平均响应时间 = (0+2+4)/3=3s
时间片的长度对于RR调度算法是至关重要的。时间片越短,RR在响应时间上表现越好,但是时间片太短也是有问题的,因为上下文切换频繁意味着它的代价越高。时间片也不能太长,时间片越长,RR在响应时间上表现越差,交互性越差。所以需要权衡时间片的长短(当然,这是内核开发人员需要考虑的,我们用户直接享受成果),在允许的条件下让时间片足够长。
提示:增加时间片长度可降低成本
增加时间片长度,可以摊销上下文切换的成本。例如,时间片长度为10ms,上下文切换需要1ms,那么大概会花费10%的时间用在上下文切换上,但如果将时间片设置为100ms,则只会花费大约1%的时间用在上下文切换上,于是时间片带来的上下文切换成本就被摊销了。
如果只关注平均响应时间,那么RR算法非常好,因为它在乎的时间片这段间隔时长,时间片越短,(不考虑上下文切换成本)RR越优秀,换句话说,每一个进程都能有机会快速被选中,它的交互性非常好。
但是,RR会在每个进程执行过程中间穿插其它进程,从而延伸每个进程,导致RR算法在平均周转时间上表现很差,甚至可以说RR在平均周转时间指标上是最差的算法。

在前面的调度算法中,一直都假设进程不会执行IO,这是不现实的。所以,这里将IO问题考虑到调度算法中。
站在我们角度上考虑,这其实也不是问题,我们早已经知道解决方案是在IO等待时将CPU分配给其它进程。但是,站在调度器的角度上考虑,在调度进程时必须需要将这个因素考虑进去。所以,这里仍然花一点笔墨简单描述下这个问题。
一方面,调度程序需要在进程开始IO时做出决定,因为在IO期间进程是不消耗CPU的,它将一直阻塞等待直到IO完成,这时调度器需要调度另外一个进程去使用CPU。
另一方面,调度程序需要在IO完成时做出决定,因为IO完成时会发送中断,从而回到操作系统,操作系统处理中断时会将IO完成对应的那个进程放回到就绪队列中,然后调度器调度下一个要执行的进程,当然也可能会直接调度到该进程。
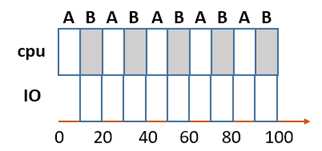
假设有A、B两个进程,各自都需要50ms的CPU时间,但是A每运行10ms就执行一次10ms的IO,而B没有IO操作,并且调度程序要求先执行完A再执行B。如图。
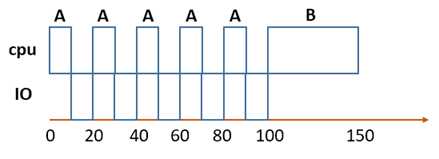
无需计算,也知道这是非常不理想的调度方式。因为在进行IO的时候,CPU完全闲置了,仅只是在那里空转。
所以,更好的方式是在进程A进行IO的时候,同时将CPU分配给进程B,如图。
到目前为止,非抢占式的SJF和STCF调度算法都是优化周转时间,通过先运行短任务首先,而抢占式的RR则是优化响应时间,通过划分运行时间片实现。它们都遵守了一个假设:每个进程的执行时长是已知的,但这是最不现实的假设,因为我们根本不可能会提前知道一个进程要做的工作需要耗费多少时间。那么如何合理地调度进程?在计算机领域里,这种优化未知问题的场景有时候非常关键,例如CPU的分支预测、缓存算法以及进程调度等等。解决这类问题的思路就是观察历史,从历史数据中推测未来。既然是预测,自然会有预测失败的时候,而预测失败的代价可能会比正常情况下更大,所以需要不断优化预测问题的方式,并提供预测失败时的挽救手段,尽量减小代价。
下面将介绍一种在进程执行时长未知情况下的调度算法:多级反馈队列(Multi-level Feedback Queue,MLFQ)。
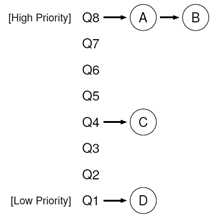
多级反馈队列通过使用不同优先级的多个队列来实现,它的基本规则是:每个进程只能存在于一个队列中,而一个队列中可以包含多个进程;同一队列中的进程具有相同的优先级;调度器优先调度最高优先级队列中的进程,并对该队列中的进程采用RR调度算法轮询调度每个进程。
下图是一个多级反馈队列的简单示意图。
MLFQ最大的问题是如何设置每个队列的优先级。因为每个进程的情况是未知的,所以需要根据一些调度指标去观察历史从而预测未来。
例如,对于用户坐在计算机前等待的进程(如等待键盘输入),很可能是一个交互性的进程,应当将它作为高优先级的进程,尽快响应给用户。再例如,对于长时间占用CPU工作的进程,很可能是后台服务类进程,应该降低它的优先级以便为更重要的交互式进程让路。
此外,还必须保证高优先级的进程在运行一段时间后能够降低它的优先级,否则在高优先级队列中的进程完全执行完之前,低优先级队列中的进程将没有机会被选中。正如上图中最高优先级的A和B进程,如果不降低它的优先级,C和D永远无法执行,换句话说,A和B进程垄断了CPU的使用权。
还要考虑IO问题,对于因执行IO而主动放弃CPU的进程,应当让其优先级不变,否则在IO完成时它很可能已经被挤到低优先级的位置,从而得不到较好的响应时间。
提示:CPU密集型和IO密集型进程
根据这里的描述,大概可以做出一个推断:1.IO密集型任务很可能是交互型进程,应该给它高优先级;2.CPU密集型任务很可能是服务类进程,应该给它低优先级。
看上去似乎有悖常理,CPU密集型任务不应该多给它一些CPU时间吗?一方面,在IO过程中(IO速度非常慢),CPU已经为CPU密集型进程工作很长时间了,临时去处理一下完成IO的进程对CPU密集型进程来说影响并不大,毕竟完成IO后的进程在那里嗷嗷待哺。另一方面,IO密集型任务在IO时已经将CPU交给其它进程并工作了足够长的时间,那么在IO完成的时候,于情于理也应该再次拿回CPU。
其实,CPU密集和IO密集中密集的含义并不是它们亟需CPU或IO,而是描述这类进程需要长时间消耗CPU或IO。此外,大多数优先级调度算法都能够为不同优先级队列分配不同长度的时间片,那么可以给高优先级(IO密集型)队列分配短时间片,给低优先级(CPU密集型)队列分配长时间片。Windows和Solaris正是这么做的,但Linux正好相反,给低优先级任务分配更短时间片,给高优先级任务分配更长时间片。
最后,还要考虑新启动的进程应放在哪个队列中的问题。因为不知道新进程的长短,所以假设它是短任务比较好,这样能快速执行完,所以将新进程放在最高队列中。
至此,MLFQ有了以下几个规则:
根据这些规则,一步步地体会优先级对调度方式的影响。
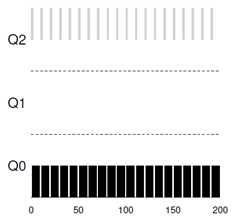
首先,假设只有单个长时间运行的进程A,如果时间片为10ms,那么,该进程的调度方式如图。在这里,进程A具体要运行多长时间(而且这是未知的)不重要,只是关注它经过调度后优先级的变化方式。
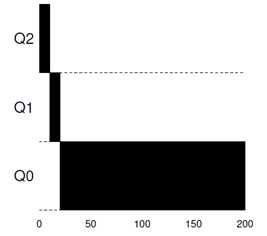
进程A启动时在最高优先级队列Q2中,运行10ms后降低优先级到Q1队列,再10ms之后进入最低优先级队列,之后它将一直在此队列中被调度。
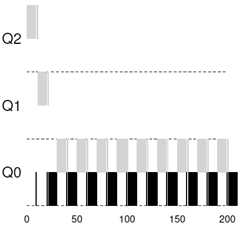
假设现在进程A运行一段时间后,来了一个只需20ms即退出的短进程B(同样的,具体时长不重要,只要它在进程A完成前退出即可),因为运行时间短,所以这个进程很可能是一个交互性的进程。那么调度方式如图。
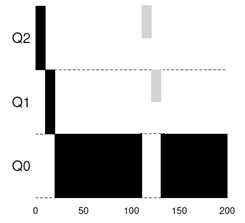
再假设,如果这个短进程B是需要执行IO的,每执行1ms就需要IO一段时间。根据规则,主动让出CPU的进程优先级不变,那么调度方式如图。
在这里,进程B可能IO密集型的进程,因为它多次IO,而进程A可能是CPU密集型的进程,因为它需要长时间运行。
但是这种调度方式有几个非常严重的问题:
基于此,需要修改MLFQ的规则,主要改变的是:保证任何一个进程都不会一直保持某个优先级。修改后的规则为:
上面添加了规则5,并将原来的规则4(a)和4(b)合并成规则4。
首先是规则5,在规则5的要求下,进程不可能会被饿死,因为每隔一段时间后所有进程的优先级都提到了最高且相同。
再是规则4,原来规则4(a)和4(b)最大的问题在于每次调度时都重新计算了时间片,使得可能出现欺骗调度器的行为。但改写成了规则4后,每个进程在某个优先级下都是有时间限制的,不管它是一次性用完还是分成多次用完,只要时间到了就降低优先级。
例如,下图中显示的高优先级进程在随着时间的流逝,它的优先级也不断下降,直到最低级别。根据规则5,等一段时间过后,所有的进程又都回到最高级别,全都被公平对待。
从上面对多级反馈队列调度算法的描述,不难发现优先级是该调度算法决定调度哪个进程的唯一标准。虽然在Linux下使用的调度算法是CFS而不是MLFQ,但是CFS也使用优先级的概念,改变优先级也能达到类似的目标。
标签:效果 解决 运行时 文件 算法 表示 相关 linu 后台服务
原文地址:https://www.cnblogs.com/f-ck-need-u/p/12685798.html