?插入数据时,待插入位置的元素和他后面的所有元素都需要向后搬移
?删除数据时,待删除位置后面的所有元素都需要向前搬移。
4.随机访问效率很高,时间复杂度可以达到O(1)
? 因为数组的内存是连续的,想要访问那个元素,直接从数组的首地址向后偏移就可以访问到了。
1 从头部删除、从头部插入的效率低,时间复杂度是o(n),因为需要相应的向前搬移和向后搬移。(需将数组中所有元素都进行相应搬移)
.2 空间利用率不高
内存空间要求高,必须要有足够的连续的内存空间。
二:链表:
1.链表它并不需要一块连续的内存空间,它通过“指针”指向一组零散的内存,空间可扩容,比较常用的是单链表,双链表和循环链表。和数组相比,链表更适合插入、删除操作频繁的场景,查询(访问)的时间复杂度较高。
链表的特点:
所谓链表,链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。 相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
空间不需要提前指定大小,是动态申请的,根据需求动态的申请和删除内存空间,扩展方便,故空间的利用率较高。
链表的缺点:
随机访问效率低,时间复杂度是o(n)
二:面试问题
Q: 数组和链表的底层是用什么写的?
A:数组的底层是Array List,链表的底层是Hashmap
(重要) hasmap冲突和溢出的解释和处理方法:
hashmap出现了Hash冲突的时候采用第二种办法:链地址法(拉链桶)。
补充哈希部分知识:
1.什么是哈希函数?:
哈希函数:一般情况下,需要在关键字与它在表中的存储位置建立一个函数关系,以f(key)作为关键字为key的记录在表中的位置,通常称这个函数f(key)为哈希函数。
额外补充:什么是哈希?
hash:(散列)就是把任意长度的输入,通过散列算法,变成固定程度的输出,该输出就是散列值。这种转换是一种压缩映射,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值。 简单的说就是一种将任意长度的消息压缩到莫伊固定长度的消息摘要的函数
2.什么是哈希冲突?
hash冲突:就是根据key即经过一个函数f(key)得到的结果的作为地址去存放当前的key value键值对(这个是hashmap的存值方式),但是却发现算出来的地址上已经有人先来了。就是说这个地方被抢了啦。这就是所谓的hash冲突啦。
3.怎么解决哈希冲突?
1.开放地址法:

2.拉链桶法:
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。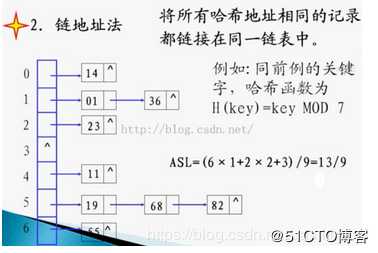
3.再哈希:
同时构造多个哈希函数。当hash1(key)冲突时,再计算hash2(key)直到不再发生冲突
4.建立公共溢出区:
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
补充:什么是哈希表?什么是非哈希表?
非哈希表的特点:关键字在表中的位置和它之间不存在一个确定的关系,查找的过程为给定值一次和各个关键字进行比较,查找的效率取决于和给定值进行比较的次数。
哈希表的特点:关键字在表中位置和它之间存在一种确定的关系。
原文地址:https://blog.51cto.com/14232658/2486832