标签:learn att otl image mes 散点图 算法 lag 向上取整
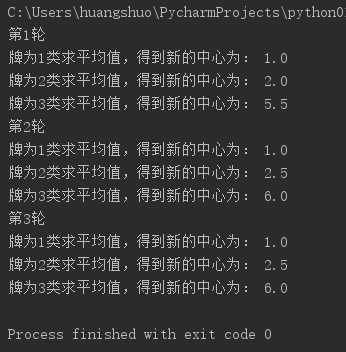
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
选取32张牌,分3类。
第1轮:聚类中心为1,2,3。

第2轮:聚类中心为1,2,6(5.5向上取整)。

第3轮:聚类中心为1,2,6(5.5向上取整)。

# 扑克牌手动演练k均值聚类过程:选择32张牌,3类 sum11 = 0 sum12 = 0 sum13 = 0 print("第1轮") for i in range(1, 2): sum11 = sum11+i*4 print("牌为1类求平均值,得到新的中心为:", sum11 / 4) for i in range(2, 3): sum12 = sum12+i*4 print("牌为2类求平均值,得到新的中心为:", sum12 / 4) for i in range(3, 9): sum13 = sum13+i*4 print("牌为3类求平均值,得到新的中心为:", sum13 / 24) sum21 = 0 sum22 = 0 sum23 = 0 print("第2轮") for i in range(1, 2): sum21 = sum21+i*4 print("牌为1类求平均值,得到新的中心为:", sum21 / 4) for i in range(2, 4): sum22 = sum22+i*4 print("牌为2类求平均值,得到新的中心为:", sum22 / 8) for i in range(4, 9): sum23 = sum23+i*4 print("牌为3类求平均值,得到新的中心为:", sum23 / 20) sum31 = 0 sum32 = 0 sum33 = 0 print("第3轮") for i in range(1, 2): sum31 = sum31+i*4 print("牌为1类求平均值,得到新的中心为:", sum31 / 4) for i in range(2, 4): sum32 = sum32+i*4 print("牌为2类求平均值,得到新的中心为:", sum32 / 8) for i in range(4, 9): sum33 = sum33+i*4 print("牌为3类求平均值,得到新的中心为:", sum33 / 20)
运行结果:
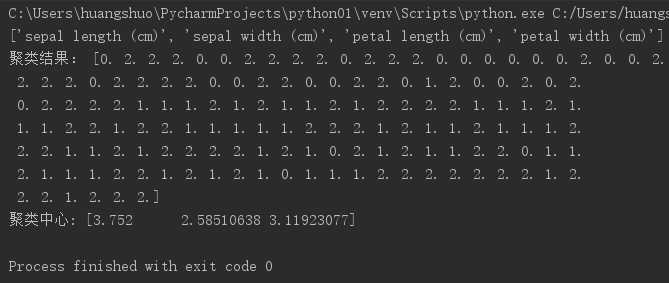
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
import numpy as np from sklearn.datasets import load_iris import matplotlib.pyplot as plt from pylab import mpl # 指定字体,解决plot不能显示中文的问题 mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] iris = load_iris() print(iris.feature_names) # 特征名称 n = len(iris.data) # 鸢尾花花瓣数据的长度 x = iris.data[:, 1] # 鸢尾花花瓣长度数据 k = 3 # 类簇个数 y = np.zeros(n) # 初始化数组 # 初始聚类中心数组 # 选择前k个样本作为初始类中心 def initcenter(x, k): # # 初始聚类中心数组 # 选择前k个样本作为初始类中心 return x[0:k] def nearest(kc, i): d = (abs(kc - i)) #距离绝对值 w = np.where(d == np.min(d)) return w[0][0] def xclassify(x, y, kc): for i in range(x.shape[0]): # 对数组的每个值分类 y[i] = nearest(kc, x[i]) return y # 更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值; def kcmean(x, y, kc, k): li = list(kc) flag = False for i in range(k): m = np.where(y==i) n = np.mean(x[m]) if li[i] !=n: li[i]=n flag=True # 聚类中心发生变化 return (np.array(li),flag) # 判断聚类中心和目标函数的值是否发生改变。 # 获取鸢尾花数据集 kc = initcenter(x, k) flag = True while flag: y = xclassify(x, y, kc) kc, flag = kcmean(x, y, kc, k) print("聚类结果:", y) print("聚类中心:", kc) plt.scatter(x, x, c=y, s=50, cmap=‘rainbow‘) plt.title("自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类的散点图") plt.show()
运行结果:
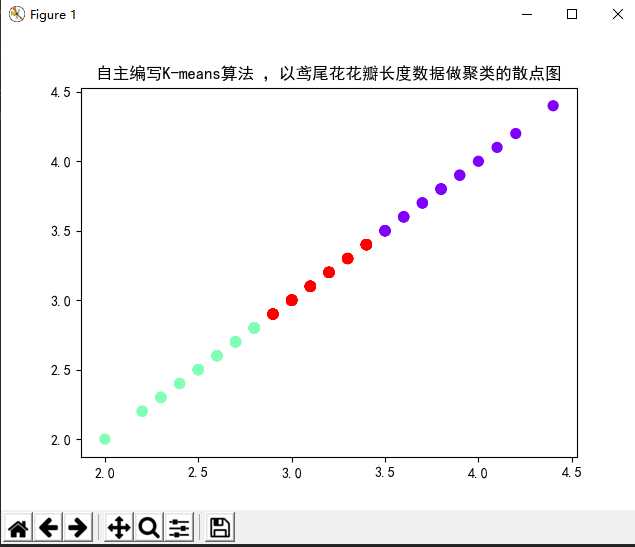
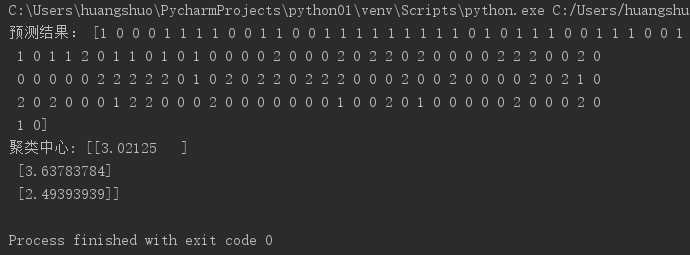
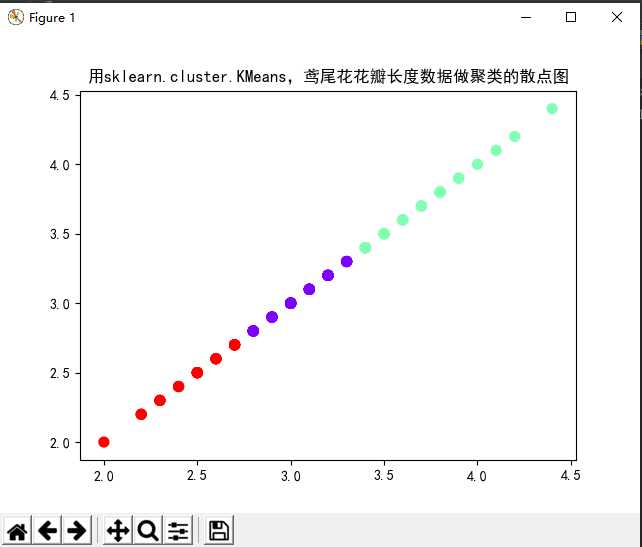
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt from pylab import mpl # 指定字体,解决plot不能显示中文的问题 mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 获取鸢尾花数据集 iris = load_iris() x = iris.data[:, 1].reshape(-1, 1) # 鸢尾花花瓣长度数据 # 直接调用sklearn库实现对鸢尾花数据进行聚类分析 model = KMeans(n_clusters=3) # 构建模型 model.fit(x) # 训练 y = model.predict(x) # 预测每个样本的聚类索引 print("预测结果:", y) kc = model.cluster_centers_ # 聚类中心 print("聚类中心:", kc) plt.scatter(x[:, 0], x[:, 0], c=y, s=50, cmap=‘rainbow‘) plt.title("用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类的散点图") plt.show()
运行结果:
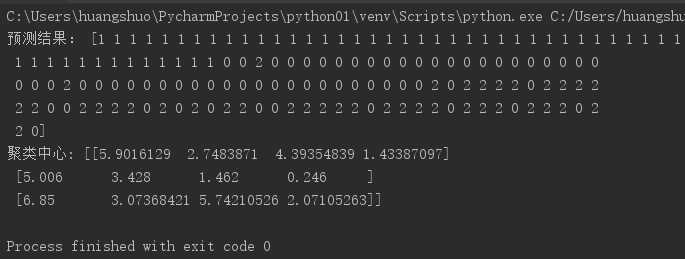
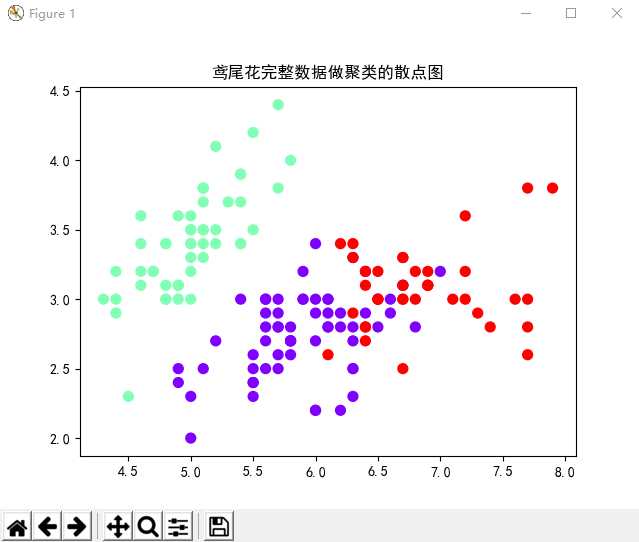
4). 鸢尾花完整数据做聚类并用散点图显示.
from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt from pylab import mpl # 指定字体,解决plot不能显示中文的问题 mpl.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 获取鸢尾花数据集 iris = load_iris() x = iris.data # 鸢尾花花瓣长度数据 # 直接调用sklearn库实现对鸢尾花数据进行聚类分析 model = KMeans(n_clusters=3) # 构建模型 model.fit(x) # 训练 y = model.predict(x) # 预测每个样本的聚类索引 print("预测结果:", y) kc = model.cluster_centers_ # 聚类中心 print("聚类中心:", kc) plt.scatter(x[:, 0], x[:, 1], c=y, s=50, cmap=‘rainbow‘) plt.title("鸢尾花完整数据做聚类的散点图") plt.show()
运行结果:
5).想想k均值算法中以用来做什么?
答:k均值算法可以用来根据对用户的购买历史或浏览记录进行分类,对不同的用户进行不同的推荐;也可以用来根据标签、主题和文档
内容将文档分为多个不同的类别,即可以做文档分类器。
标签:learn att otl image mes 散点图 算法 lag 向上取整
原文地址:https://www.cnblogs.com/hs01/p/12692767.html