标签:整数 kmeans 算法 准备 旅行 ase print http sha
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
from sklearn.datasets import load_iris import numpy as np import matplotlib.pyplot as plt # 数据准备 iris = load_iris() data = iris.data[:, 1] # 获取鸢尾花花瓣长度 k = 3 # 类中心个数,最终分类的类别数 n = len(data) # 样本个数 center = np.random.choice(data, k) # 随机选取data中的k个数据初始类中心 dist = np.zeros(n) # 每个样本到类中心的距离 new_center = np.zeros(k) # 新的类中心 d = np.zeros(k) # 定义一个存放距离的数组 while True: # 求距离 for i in range(n): for j in range(k): d[j] = (abs(center[j] - data[i])) # 计算到中心的距离 # 聚类 dist[i] = np.argmin(d) # 求新类中心 for c in range(k): index = dist == c new_center[c] = np.mean(data[index]) #判定结束 if np.all(center == new_center): break else: center = new_center print(‘最终聚类结果:‘, dist) # 散点图 plt.scatter(data, data, c=dist, s=50, cmap="rainbow") plt.show()
结果:
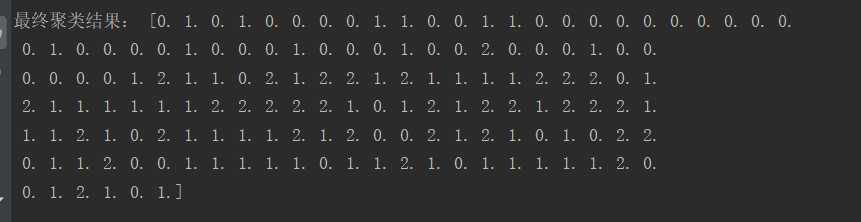
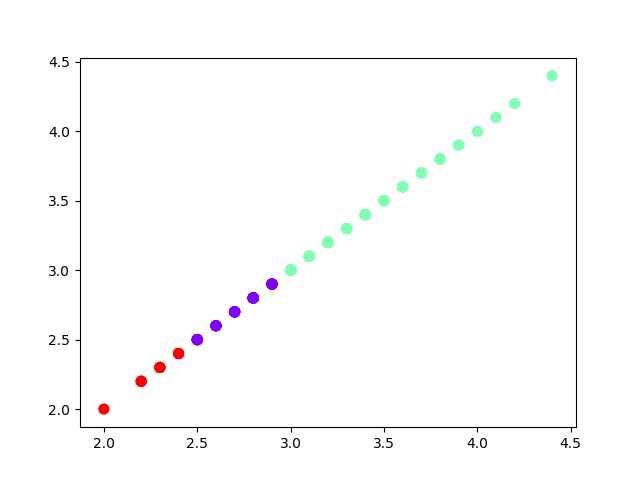
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
from sklearn.datasets import load_iris import matplotlib.pyplot as plt from sklearn.cluster import KMeans iris = load_iris() data = iris.data[:, 1] x = data.reshape(-1, 1) x.shape est = KMeans(n_clusters=3) est.fit(x) y = est.predict(x) plt.scatter(x[:, 0], x[:, 0], c=y, s=50, cmap="rainbow") plt.show()
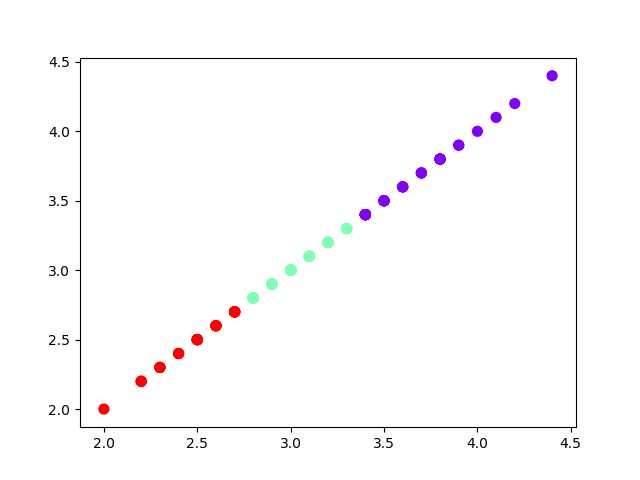
4). 鸢尾花完整数据做聚类并用散点图显示.
from sklearn.datasets import load_iris import matplotlib.pyplot as plt from sklearn.cluster import KMeans iris = load_iris() data = iris.data est = KMeans(n_clusters=3) est.fit(data) y = est.predict(data) plt.scatter(data[:, 2], data[:, 3], c=y, s=50, cmap="rainbow") plt.show()
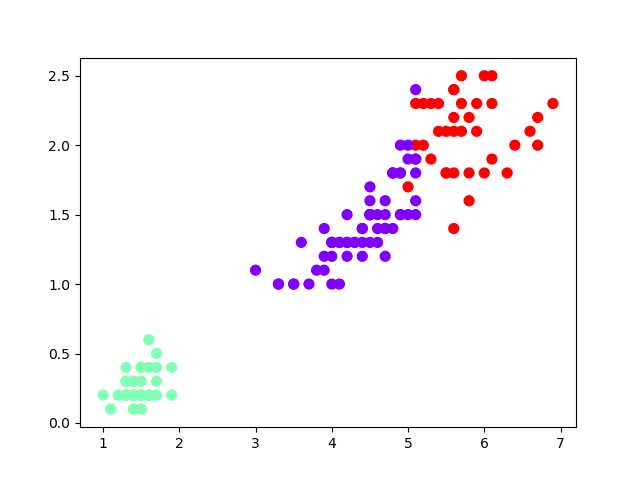
5).想想k均值算法中以用来做什么?
K-means算法通常可以应用于维数、数值都很小且连续的数据集,比如:从随机分布的事物集合中将相同事物进行分组。
1.物品传输优化
使用K-means算法的组合找到无人机最佳发射位置和遗传算法来解决旅行商的行车路线问题,优化无人机物品传输过程。
2.识别犯罪地点
使用城市中特定地区的相关犯罪数据,分析犯罪类别、犯罪地点以及两者之间的关联,可以对城市或区域中容易犯罪的地区做高质量的勘察。
标签:整数 kmeans 算法 准备 旅行 ase print http sha
原文地址:https://www.cnblogs.com/momo-er/p/12698655.html