标签:操作 简单 oracle数据库 数据格式 网络 高性能 字段 分区 集群
大数据时代到来,短视频和大量图片导致数据表非常大,频繁的查询导致传统的关系型数据库难以满足需求,因此非关系型数据库就应运而生。Redis数据库是NoSQL是一种,在分布式数据库的CAP原理中,Redis满足强一致性和高可用性,强一致性就是要保证数据的质量,高可用性即稳定性,本文简单介绍了非关系型数据库是什么、能干嘛,与关系型数据库的区别。
一、NoSQL定义
NoSQL(Not Only SQL),意即“不仅仅是SQL”,泛指非关系型数据库。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,例如谷歌或Facebook每天为他们的用户收集万亿比特的数据,这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
二、NoSQL的优势
1.易扩展
NoSQL数据库种类繁多,但有一个共同的特点是去掉关系数据库的关系型特性。数据间无关系,这样就非常容易拓展,无形之间在架构层面上带来了可扩展的能力。
2.大数据量高性能
NoSQL数据库具有非常高的读写性能,尤其在大数据量下,一秒钟写8万,读16万次
3.多样灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以根据存储自定义数据格式,而在关系型数据库里增删字段,比如在存储微信用户信息的表里添加一个手机号字段,简直就是噩梦。
4.RDBMS和NoSQL
关系型数据库&非关系型数据库的对比


三、3V+3高
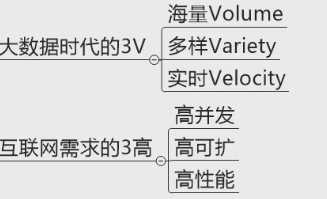
海量:微博
多样:呈现方式是图片、文字等,终端是手机、电脑、pad等。
实时:12306的铁路信息需要做到实时更新,但是做不到绝对的实时,只能做到准实时。
高并发:12306在抢火车票的时候是高并发的
高可扩(扩展性):
横向扩展:针对多台机器,多台机器整合成一个集群
纵向扩展:针对一台机器,2G不够了,插两条4G就变8G,但纵向扩展长期来看总有尽头
四、NoSQL数据模型简介
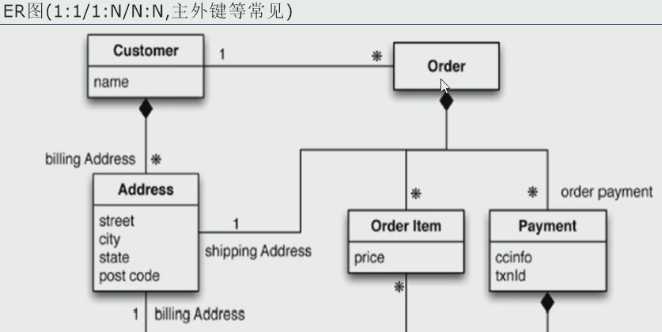
(一)以一个电商客户、订单、订购、地址模型来对比关系型数据库和非关系型数据库数据库
1.关系型数据库:

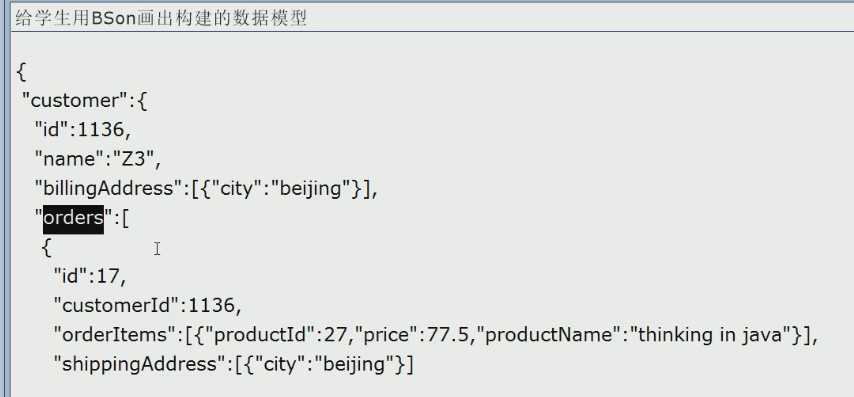
2.非关系型数据库:
就像一个jason串一样,被称为聚合模型
(二)思考
为什么上述情况可以用聚合模型来处理?
1.在关系型数据库里用left join 关联查询,但是涉及多张表,查询语句很长很复杂
2.跨库
3.分布式事务无法支持太多并发
·4.NoSQL只要查到客户信息的ID,所有的信息都放在一起,不用像关系型数据库查很多表

(三)、聚合模型
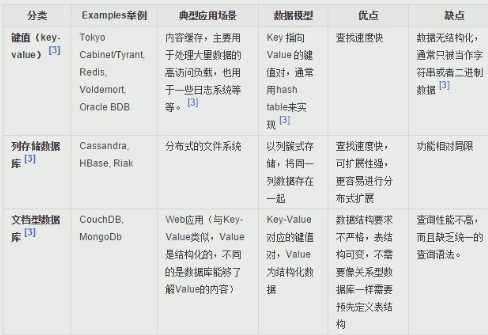
1.KV键-值对
2.文档型数据库(Bson格式比较多):见上截图

Monddb,最像关系型数据库的非关系型数据库
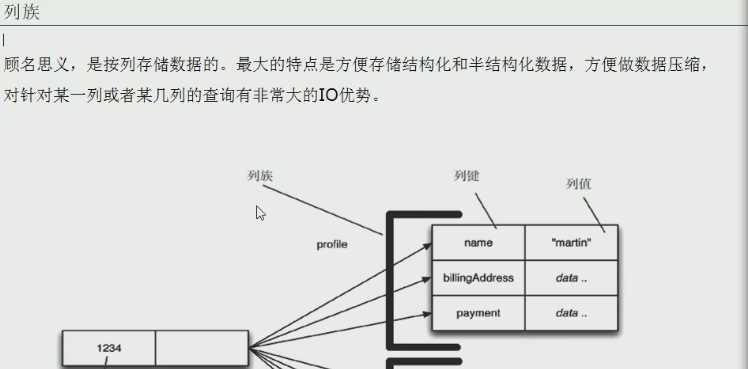
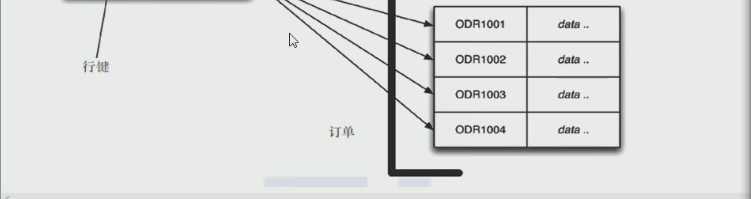
3.列存储数据库:
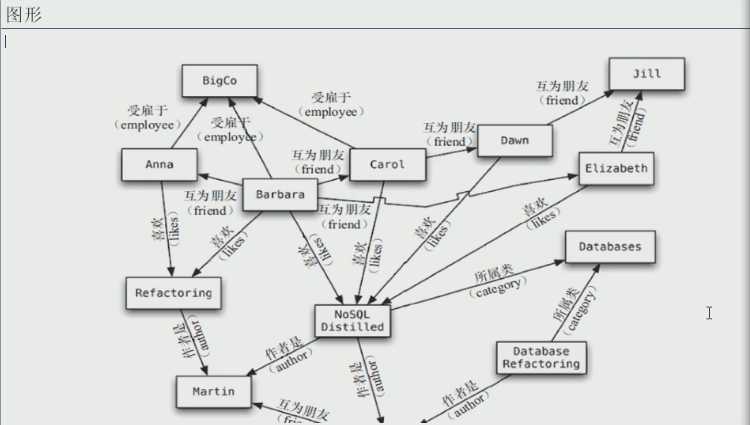
4. 图关系数据库:
就像我们复杂的亲戚人际关系,如:微博上你的好友关注什么话题



五、在分布式数据库中CAP原理CAP+BASE
(一)CAP

ACID:传统的关系型数据库

CAP:NoSQL

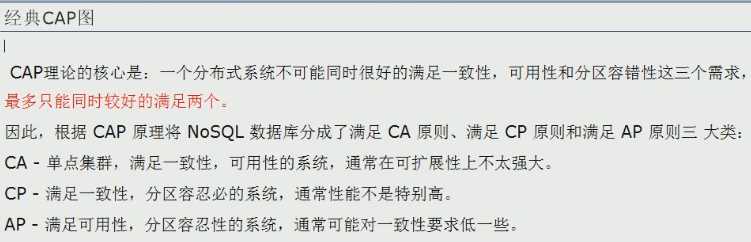
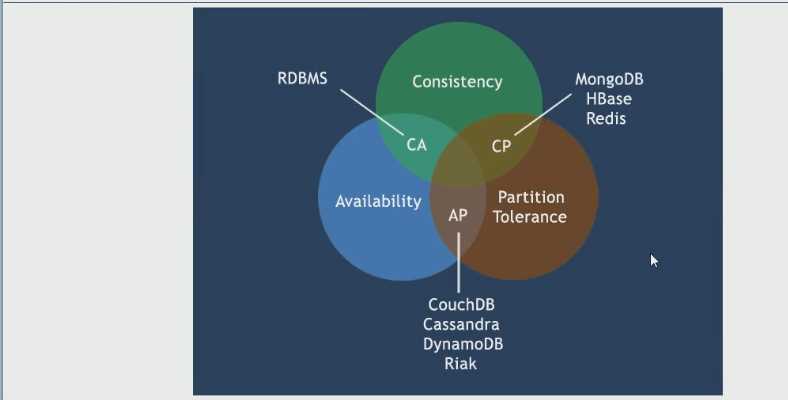
CAP只能三个中满足两个,而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容错性是我们必须要实现的,我们只能在一致性和可用性之间进行权衡。
CA:传统型Oracle数据库
AP:大多数网站架构的选择
CP:Redis、Mongodb
强一致性(C),淘宝商品的点赞数不用做到强一致性;但公司每日的早晚打卡软件就需要做到强一致性,不然影响员工的KPI
高可用性(A),网站不能崩了
分区容忍性(P)
补充:C与A的选择


(二)BASE
双十一当时可能商品点赞数10000,但是只统计到6000,是弱一致性,但是高峰结束之后还是想让数据不那么离谱,所以加上BASE,BASE最重要的就是最终执行

牺牲C,换取AP

集群就相当于之前的负载均衡

(一)Redis-NoSql是什么、能干嘛,与关系型数据库的区别
标签:操作 简单 oracle数据库 数据格式 网络 高性能 字段 分区 集群
原文地址:https://www.cnblogs.com/hydd/p/12676403.html