标签:超过 不同的 第一个 最大 长度 image 运算 作者 固定
版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖。如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/12664044.html 作者:窗户 QQ/微信:6679072 E-mail:6679072@qq.com
所谓众数,源于这样的一个题目:一个长度为len的数组,其中有个数出现的次数大于len/2,如何找出这个数。
基于排序
排序是第一感觉,就是把这个数组排序一下,再遍历一遍得到结果。
C语言来写基本如下:
int find(int a, int len) { sort(a, len); return traverse(a, len); }
排序有时间复杂度为O(nlogn)的算法,比如快速排序、归并排序、堆排序,而遍历一遍排序后的数组得到结果是时间线性复杂度,也就是O(n)。所以整个算法时间复杂度是O(nlogn)。
寻找更好的算法
上面的算法实在太简单,很多时候我们第一感就可以出来的东西未必靠谱。
我们是不是可以找到一种线性时间级别的算法,也就是Θ(n)时间级别的算法?Θ是上下界一致的符号。其实我们很容易证明,不存在比线性时间级别低的算法,也就是时间o(n),小o不同于大O,是指低阶无穷大。证明大致如下:
如果一个算法可以以o(n)的时间复杂度解决上述问题。因为是比n更低阶的无穷大,那么一定存在一个长度为N的数组,在完成这个算法之后,数组内被检测的元素小于N/2。假设算法运算的结果为a,然后,我们把这个数组在运算该算法时没有检测的元素全部替换为成同一个不是算法所得结果a的数b。然后新的数组,再通过算法去运算,因为没有检测的数不会影响其算法结果,结果自然还是a,可实际上,数组超过N/2次出现的数是b。从而导致矛盾,所以针对该问题的o(n)时间算法不存在。
我们现在可以开始想点更加深入点的东西。
我们首先会发现,如果一个数组中有两个不同的数,将数组去掉这两个数,得到一个新数组,那么这个新数组依然和老数组一样存在相同的众数。这一条很容易证明:
假设数组为a,长度为len,众数为x,出现的次数为t,当然满足t>len/2。假设其中有两个数y和z,y≠z。去掉这两个数,剩下的数组长度为len-2。如果这两个数都不等于众数x,也就是x≠y且x≠z,那么x在新的数组中出现的次数依然是t,t>len/2>(len-2)/2,所以t依然是新的数组里的众数。而如果这两个数中存在x,那么自然只有一个x,则剩下的数组中x出现的次数是t-1,t-1>len/2-1=(len-2)/2,所以x依然是新数组的众数。
有了上述的思路,我们会去想,如何找到这一对对的不同的数呢。
我们可以记录数字num和其重复的次数times,遍历一遍数组,按照以下流程图来。
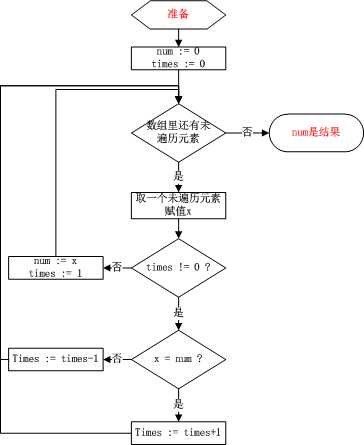
num/times一直记录着数字和其重复次数,times加1和减1都是随着数组新来的数是否和num相同来决定,减1的情况其实就取决于上面证明的那个命题,找到一对不相同的数字,去掉这两个,剩下的数组的众数不变。
关于在于证明最后的结果是所求的众数。如果后面的结果不是众数,那么众数每出现一次,就得与一个不是众数的数一起“抵消”,所以数组中不是众数的数的数量不会少于众数的数量,然而这不是现实。于是上述算法成立,它有着线性时间复杂度O(n),常数空间复杂度O(1)。
C语言代码基本如下:
int find(int *a, int len) {
int i, num = 0, times = 0;for(i=0;i<len;i++) { if(times > 0) { if(num == a[i]) times++; else times--; } else { num = a[i]; times = 1; } } return num; }
如果用Scheme编写,程序可以简洁如下:
(define (find s) (car (fold-right (lambda (n r) (if (zero? (cdr r)) (cons n 1) (cons (car r) ((if (eq? n (car r)) + -) (cdr r) 1)))) ‘(() . 0) s)))
升级之后的问题
上面的众数是出现次数大于数组长度的1/2的,如果将这里的1/2改成1/3,要找出来怎么做呢?
例如,数组是[1, 1, 2, 3, 4],那么要找出的众数为1。
再升华一下,如果是1/m,这里的m是一个参数,该怎么找出来呢?这个问题要去之前那个问题要复杂一些,另外我们要意识到,问题升级之后,众数是有可能不止一个的,比如[1, 1, 2, 2, 3]长度为5,1和2都大于5/3。最多有m-1个众数。
思路
如果依然是排序之后再遍历,依然是有效的,可是时间复杂度还是O(nlogn)级别,我们还是期待有着线性时间复杂度的算法。
对于第一个问题,成立的前提是去掉数组里两个不一样的数,众数依然不变。那么对于升级之后的问题,是不是依然有类似的结果。不同于之前,我们现在来看在众数从1/2以上变成1/m以上,我们来看去掉长度为len的数组a里m个互不相同的数,会发生什么。证明过程如下:
同样,我们假设a里有一个众数x,x出现的次数为t,看看去掉m个不一样的数之后x还是不是众数。去掉m个数之后,新的数组长度为len-m。x是众数,所以x的出现次数t > len/m,如果去掉的m个数中没有x,则x在剩余的数组中的出现次数依然是t,t > len/m > (len-m)/m,所以这种情况下x还是众数;如果去掉的m个数中存在x,因为m个数互不相同,所以其中x只有一个,所以x在剩余的数组中的出现次数是t-1,t > len/m,从而t-1 > len/m-1 = (len-m)/m,所以x在剩余的数组里依然是众数。以上对于数组中所有的众数都成立。同理可证,对于数组中不是众数的数,剩余的数组中依然不是众数,实际上,把上面所有的>替换为≤即可。
有了上面的理解,我们可以仿照之前的算法,只是这里改成了长度最多为n-1的链表。比如对于数组[1, 2, 1, 3],众数1超过数组长度4的1/3,过程如下
初始时,空链表[]
检索第一个元素1,发现链表中没有记录num=1的表元,链表的长度没有达到2,所以插入到链表,得到[(num=1,times=1)]
检索第二个元素2,发现链表中没有记录num=2的表元,链表的长度没有达到2,插入到链表,得到[(num=1,times=1), (num=2,times=1)]
检索第三个元素1,发现链表中已经存在num=1的表元,则把该表元times加1,得到[(num=1,times=2), (num=2,times=1)]
检索第四个元素3,发现链表中没有num=3的表元,链表长度已经达到最大,等于2,于是执行消去,也就是每个表元的times减1,并把减为0的表元移出链表,得到[(num=1,times=1)]
以上就是过程,最终得到众数为1。
以上过程最终得到的链表的确包含了所有的众数,这一点很容易证明,因为任何一个众数的times都不可能被完全抵消掉。但是,以上过程实际并不保证最后得到的链表里全都是众数,比如[1,1,2,3,4]最终得到[(num=1,times=1), (num=4,times=1)],但4并不是众数。
所以我们需要得到这个链表之后,再遍历一遍数组,将重复次数记载于链表之中。
Python下使用map/reduce高阶函数来取代过程式下的循环,上述的算法也需要如下这么多的代码。
from functools import reduce def find(a, m): def find_index(arr, test): for i in range(len(arr)): if test(arr[i]): return i return -1 def check(r, n): index = find_index(r, lambda x : x[0]==n) if index >= 0: r[index][1] += 1 return r if len(r) < m-1: return r+[[n,1]] return reduce(lambda arr,x : arr if x[1]==1 else arr+[[x[0],x[1]-1]], r, []) def count(r, n): index = find_index(r, lambda x : x[0]==n) if index < 0: return r r[index][1] += 1 return r return reduce(lambda r,x : r+[x[0]] if x[1]>len(a)//m else r, reduce(count, a, list(map(lambda x : [x[0],0], reduce(check, a, [])))), [])
如果用C语言编写代码会更多一些,不过可以不用链表,改用固定长度的数组效率会高很多,times=0的情况代表着元素不被占用。此处就不实现了,交给有兴趣的读者自己来实现吧。
标签:超过 不同的 第一个 最大 长度 image 运算 作者 固定
原文地址:https://www.cnblogs.com/Colin-Cai/p/12664044.html