标签:ase return 逻辑 image inf linear 三次 无限 cto
几乎在每一种编程语言中,都有数组这个数据类型。不过,它不仅仅是一种编程语言中的数据类型,还是一种最基础的数据结构。尽管数组看起来非常基础、简单,但是我们真的理解了它的精髓吗?在大部分编程语言中,数组都是从 0 开始编号的。为什么数组要从 0 开始编号,而不是从 1 开始呢?从 1 开始不是更符合人类的思维习惯吗?
带着以上问题,我们来分析数组。
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
想彻底掌握数组的概念,要抓住几个关键词。
顾名思义,线性表中的数据像一根线一样串联在一起。每个线性表上的数据最多只有前和后两个方向。除了数组,链表、队列、栈等也是线性表结构。
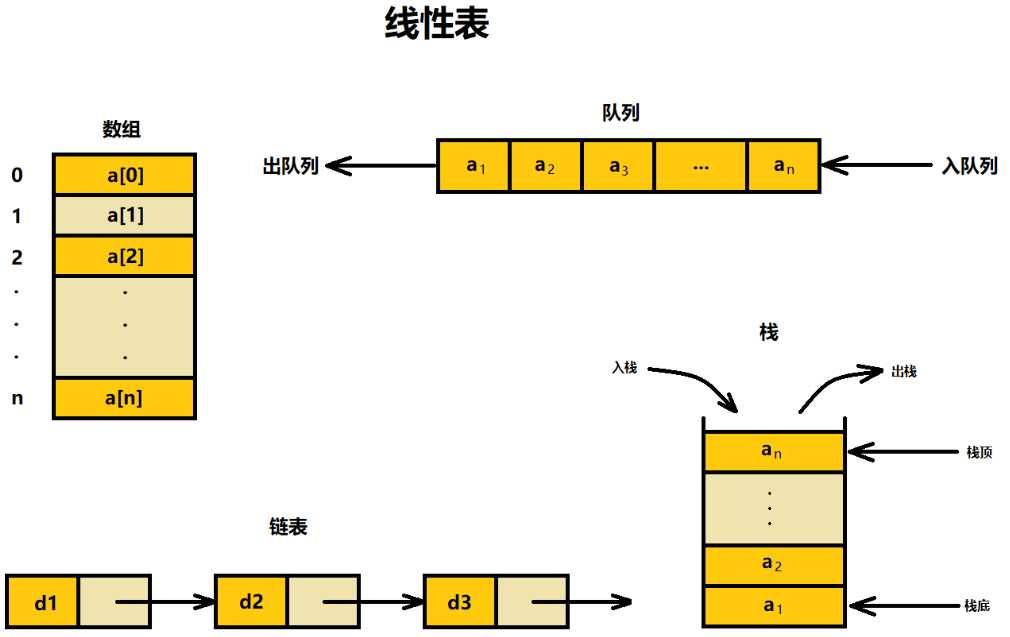
所谓非线性,是因为在非线性表中,数据之间并不是简单的前后关系。比如二叉树、堆、图等。
这两个限定条件使得数组具备“随机访问”的能力。但这两个限定条件也让数组的很多操作变得非常低效,比如要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据迁移。
接下来,我们看看数组是如何实现根据下标随机访问数组元素的。以一个长度为 10 的 int 类型的数组 int[] a = new int[10] 来举例。在下图中,计算机给数组 a[10] 分配了一块连续内存空间 1000~1039,其中,内存块的首地址为 base_address = 1000。
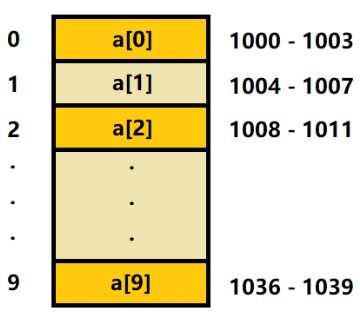
每个内存单元都有对应地址,计算机就是通过这些地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,首先会通过下面的寻址公式,计算出存储该元素的内存地址。其中 data_type_size 表示数组中每个元素的大小。示例数组中存储的是 int 类型数据,所以 data_type_size 就为 4 个字节。
1 a[i]_address = base_address + i * data_type_size
有个常见的误区需要注意,面试常常会问数组和链表的区别,很多人都回答说,“链表适合插入、删除,时间复杂度 O(1);数组适合查找,查找时间复杂度为 O(1)”。实际这是不准确的,数组确实适合查找操作,但是查找的时间复杂度并不为 O(1)。即便是排好序的数组,你用二分查找,时间复杂度也是 O(logn)。所以,正确的表述应该是,数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)。
前面提到,数组为了保持内存数据的连续性,会导致插入、删除这两个操作比较低效。我们接下来就看看,导致低效的原因是什么?有哪些改进方法?
假设数组的长度为 n,现在,如果我们需要将一个数据插入到数组中的第 k 个位置。为了把第 k 个位置腾出来,给新来的数据,我们需要将第 k~n 这部分的元素都顺序地往后挪一位。
如果在数组的末尾插入元素,那就不需要移动数据了,这时的时间复杂度为 O(1)。如果在数组的开头插入元素,那所有的数据都需要依次往后移动一位,所以最坏时间复杂度是 O(n)。因为我们在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为 (1+2+…n)/n=O(n)。
如果数组中的数据是有序的,我们在某个位置插入一个新的元素时,就必须按照刚才的方法搬移 k 之后的数据。但是,如果数组中存储的数据并没有任何规律,数组只是被当作一个存储数据的集合。在这种情况下,如果要将某个数据插入到第 k 个位置,为了避免大规模的数据搬移,我们还有一个简单的办法就是,直接将第 k 位的数据搬移到数组元素的最后,把新的元素直接放入第 k 个位置。
为了更好地理解,我们举一个例子。假设数组 a[10]中存储了如下 5 个元素:a,b,c,d,e。
我们现在需要将元素 x 插入到第 3 个位置。我们只需要将 c 放入到 a[5],将 a[2]赋值为 x 即可。最后,数组中的元素如下: a,b,x,d,e,c。

利用这种处理技巧,在特定场景下,在第 k 个位置插入一个元素的时间复杂度就会降为 O(1)。这个处理思想在快排中也会用到,我会在排序那一节具体来讲,这里就说到这儿。
跟插入数据类似,如果我们要删除第 k 个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了。
和插入类似,如果删除数组末尾的数据,则最好情况时间复杂度为 O(1);如果删除开头的数据,则最坏情况时间复杂度为 O(n);平均情况时间复杂度也为 O(n)。
实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率是不是会提高很多呢?
我们继续来看例子。数组 a[10]中存储了 8 个元素:a,b,c,d,e,f,g,h。现在,我们要依次删除 a,b,c 三个元素。

为了避免 d,e,f,g,h 这几个数据会被搬移三次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
如果你了解 JVM,你会发现,这不就是 JVM 标记清除垃圾回收算法的核心思想吗?没错,数据结构和算法的魅力就在于此,很多时候我们并不是要去死记硬背某个数据结构或者算法,而是要学习它背后的思想和处理技巧,这些东西才是最有价值的。如果你细心留意,不管是在软件开发还是架构设计中,总能找到某些算法和数据结构的影子。
我们还是通过示例来分析:
1 int main(int argc, char* argv[]) 2 { 3 int i = 0; 4 int arr[3] = {0}; 5 6 for(; i<=3; i++) 7 { 8 arr[i] = 0; 9 printf("hello world\n"); 10 } 11 12 return 0; 13 }
上述代码的实际运行结果是循环打印“hello world”。这是因为当 i=3 时,数组 a[3] 访问越界。
在 C 语言中,只要不是访问受限的内存,所有内存空间都可以自由访问。所以 a[3] 会被定位到某个不属于此数组的内存地址上。这个地址恰好是存储变量 i 的内存地址,所以 a[3] = 0 就相当于 i = 0,从而导致无限循环。
数组越界在 C 语言中是一段未决行为,没有规定数组访问越界时,编译器应如何处理。访问数组的本质就是访问一段连续内存,只要数组通过偏移计算得到的内存地址是可用的,程序就不会抱错。但此时,通常会出现莫名其妙的逻辑错误。所以,一定要警惕数组越界。
当然,并非所有的语言都像 C 一样,把数组越界检查的工作丢给程序员来做。譬如 Java 本身就会做越界检查,当发生越界时,会抛出 java.lang.ArrayIndexOutOfBoundsException。
针对数组类型,很多语言都提供了容器类,比如 Java 中的 ArrayList、C++ STL 中的 vector。在项目开发中,什么时候适合用数组,什么时候适合用容器呢?我们以 Java 为例来进行分析。
ArrayList 最大的优势就是可以将很多数组操作的细节封装起来。比如前面提到的数组插入、删除数据时需要搬移其他数据等。另外,它还有一个优势,就是支持动态扩容。
数组本身在定义的时候需要预先指定大小,因为需要分配连续的内存空间。如果我们申请了大小为 10 的数组,当第 11 个数据需要存储到数组中时,我们就需要重新分配一块更大的空间,将原来的数据复制过去,然后再将新的数据插入。
如果使用 ArrayList,我们就完全不需要关心底层的扩容逻辑,ArrayList 已经帮我们实现好了。每次存储空间不够的时候,它都会将空间自动扩容为 1.5 倍大小。
有一点需要注意:扩容操作涉及内存申请和数据搬移,是比较耗时的。如果事先能确定需要存储的数据大小,最好在创建 ArrayList 的时候事先指定数据大小,这样可以省掉很多次内存申请和数据搬移操作。
1. Java ArrayList 无法存储基本类型,比如 int、long,需要封装为 Integer、Long 类,而 Autoboxing、Unboxing 则有一定的性能消耗,所以如果特别关注性能,或者希望使用基本类型,就可以选用数组。
2. 如果数据大小事先已知,并且对数据的操作非常简单,用不到 ArrayList 提供的大部分方法,也可以直接使用数组。
3. 当要表示多维数组时,用数组往往会更加直观。比如 Object[][] array;而用容器的话则需要这样定义:ArrayList<ArrayList<object> > array。
总而言之,对于业务开发,损耗一点性能,也不影响系统整体的性能,所以图个方便,直接使用容器就足够了。对于非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。如果用 a 来表示数组的首地址,a[0] 就是偏移为 0 的位置,也就是首地址,a[k]就表示偏移 k 个 type_size 的位置,所以计算 a[k] 的内存地址只需要用这个公式:
1 a[k]_address = base_address + k * type_size
如果数组从 1 开始,公式则应是:
1 a[k]_address = base_address + (k-1)*type_size
从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。
此外,从 0 开始,更多是历史原因。C 语言数组下标从 0 开始,之后的语言也大多沿用了这种做法。
【数据结构与算法之美】04-数组:为什么很多编程语言中数组都从0开始编号?
标签:ase return 逻辑 image inf linear 三次 无限 cto
原文地址:https://www.cnblogs.com/murongmochen/p/12705225.html