标签:img 选中 learn pyplot 聚类 bow mat k-means 整数
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
没有牌。
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
上学期写的。
from sklearn.datasets import load_iris import numpy as np iris = load_iris() data = iris[‘data‘] data.shape n = len(data) # 样本个数 m = data.shape[1] # 样本属性个数 k = 3 # 类中心个数 dist = np.zeros([n, k+1]) # 初始化距离矩阵,最后一列存放每个样本的类别(归属的类) # 选中心 center = data[:k, :] # 选择前k个样本为初始类中心 center_new = np.zeros([k, m]) # 新的类中心 while True: for i in range(n): for j in range(k): dist[i, j] = np.sqrt(sum((data[i, :] - center[j, :])**2)) # 2、求距离 dist[i, k] = np.argmin(dist[i, :k]) # 3、归类 # 求新类中心 for i in range(k): index = dist[:, k] == i # 求类别为k的样本索引, 判断距离矩阵中最后一列归属为哪一类 center_new[i,:] = data[index, :].mean(axis=0) # 取得k类样本的属性值得均值,作为新的类中心 # 判定结束 if np.all((center == center_new)): break else: center = center_new print(‘150个样本的归类:‘, dist[:, k])
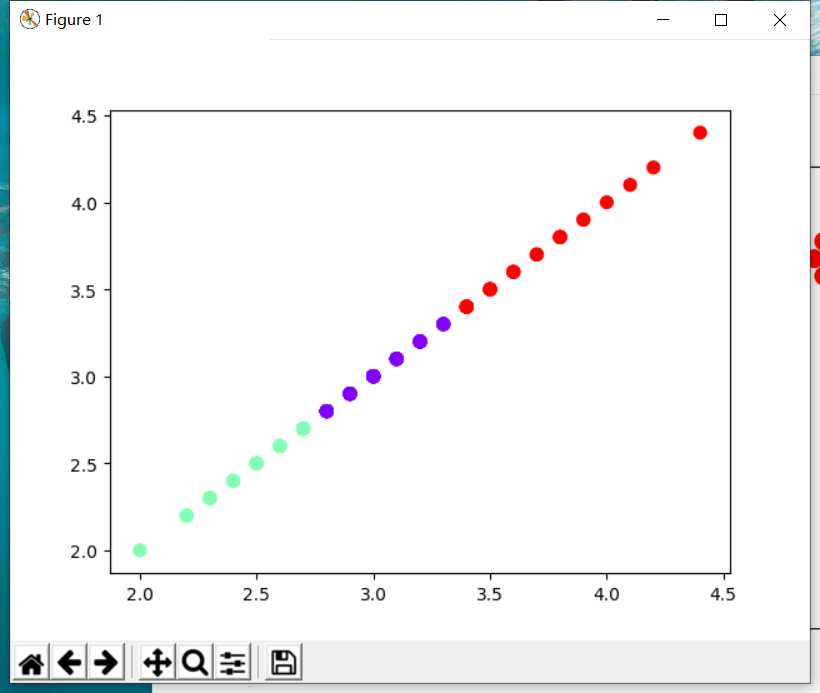
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris iris=load_iris() data=iris.data[:,1] x=data.reshape(-1,1) y=KMeans(n_clusters=3) y.fit(x) y_pre=y.predict(x) plt.scatter(x[:,0],x[:,0],c=y_pre,s=50,cmap=‘rainbow‘) plt.show()
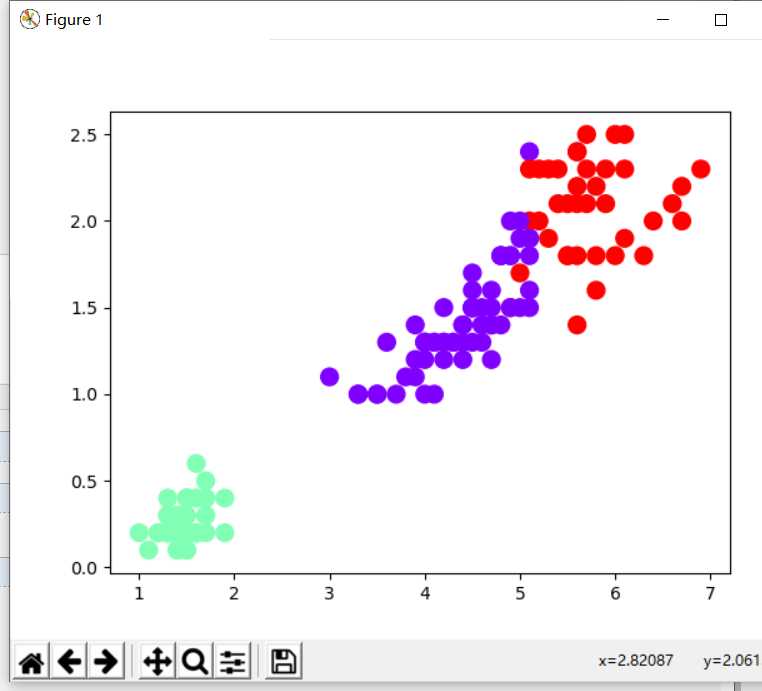
4). 鸢尾花完整数据做聚类并用散点图显示.
import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris data=load_iris() x=data.data y=KMeans(n_clusters=3) y.fit(x) y_pre=y.predict(x) plt.scatter(x[:,2],x[:,3],c=y_pre,s=100,cmap=‘rainbow‘,alpha=1) plt.show()
5).想想k均值算法中以用来做什么?
高中生可以通过平时的成绩聚类分析自己是处于什么层次,高考大概能考到什么学校。
标签:img 选中 learn pyplot 聚类 bow mat k-means 整数
原文地址:https://www.cnblogs.com/xyqzzz/p/12715957.html