标签:数据 均值 iris 价值 规划 alt sha ima learn
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
第一次聚类中心为3,7,11

第二次聚类中心为(2,7,12)

第三次的聚类中心(3,7,11),重复步骤还是如此,最终聚类中心为(3,7,11)
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import load_iris from sklearn.cluster import KMeans iris = load_iris().data sl =iris[:,2] X = sl.reshape(-1,1) X.shape est = KMeans(n_clusters=3) est.fit(X) est.predict([[3.5]]) y_kmeans = est.predict(X) est.cluster_centers_ est.labels_ plt.scatter(X[:,0],X[:,0],c=y_kmeans,s=50,cmap="rainbow") plt.show()
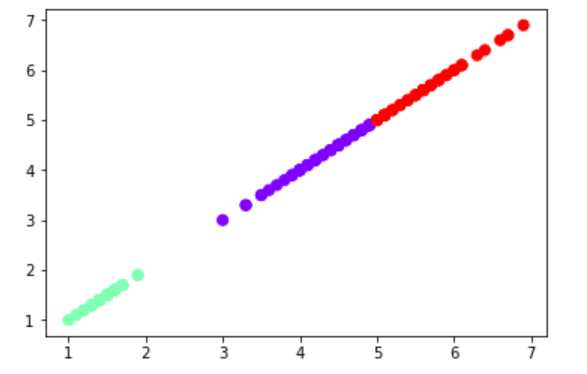
4). 鸢尾花完整数据做聚类并用散点图显示.
import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris data=load_iris() x=data.data y=KMeans(n_clusters=3) y.fit(x) y_pre=y.predict(x) plt.scatter(x[:,2],x[:,3],c=y_pre,s=100,cmap=‘rainbow‘,alpha=0.5) plt.show()
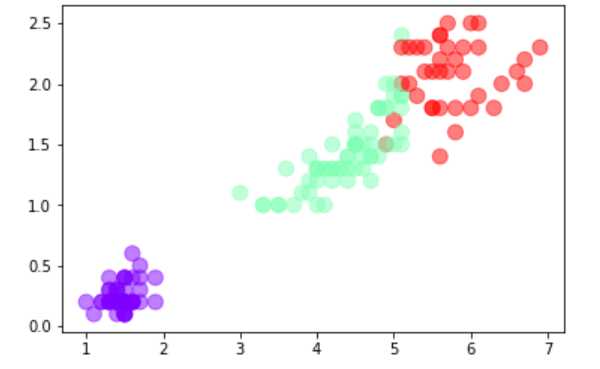
5).想想k均值算法中以用来做什么?
聚类能过帮助营销人员改善他们的客户群(在其目标区域内工作),并根据客户的购买历史、兴趣或活动监控来对客户类别做进一步细,对客户进行分类有助于公司针对特定客户群制定特定的广告。面向大众公开的乘车信息的数据集,为我们提供了大量关于交通、运输时间、高峰乘车地点等有价值的数据集。分析这些数据有助于我们对城市的交通模式进行深入的了解,来帮助我们做城市未来规划。
标签:数据 均值 iris 价值 规划 alt sha ima learn
原文地址:https://www.cnblogs.com/MRJ1/p/12716143.html