标签:lsp package https 字典 viterbi ring 配置 aic 官方
分词技术就是搜索引擎针对用户提交查询的关键词串进行的查询处理后根据用户的关键词串用各种匹配方法进行分词的一种技术。
中文分词(Chinese Word Segmentation)指的是将一个汉字序列(句子)切分成一个一个的单独的词,分词就是将连续的字序列按照一定的规则重新组合成词序列的过程。
现在分词方法大致有三种:基于字符串配置的分词方法、基于理解的分词方法和基于统计的分词方法。
今天为大家分享一个国内使用人数最多的中文分词工具GoJieba,源代码地址:GoJieba ,官方文档:GoJieba官方文档
 ?
?
官方介绍
模式扩展
主要算法
编码实现
package main
import (
"fmt"
"github.com/yanyiwu/gojieba"
"strings"
)
func main() {
var seg = gojieba.NewJieba()
defer seg.Free()
var useHmm = true
var separator = "|"
var resWords []string
var sentence = "万里长城万里长"
resWords = seg.CutAll(sentence)
fmt.Printf("%s\t全模式:%s \n", sentence, strings.Join(resWords, separator))
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s\t精确模式:%s \n", sentence, strings.Join(resWords, separator))
var addWord = "万里长"
seg.AddWord(addWord)
fmt.Printf("添加新词:%s\n", addWord)
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s\t精确模式:%s \n", sentence, strings.Join(resWords, separator))
sentence = "北京鲜花速递"
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s\t新词识别:%s \n", sentence, strings.Join(resWords, separator))
sentence = "北京鲜花速递"
resWords = seg.CutForSearch(sentence, useHmm)
fmt.Println(sentence, "\t搜索引擎模式:", strings.Join(resWords, separator))
sentence = "北京市朝阳公园"
resWords = seg.Tag(sentence)
fmt.Println(sentence, "\t词性标注:", strings.Join(resWords, separator))
sentence = "鲁迅先生"
resWords = seg.CutForSearch(sentence, !useHmm)
fmt.Println(sentence, "\t搜索引擎模式:", strings.Join(resWords, separator))
words := seg.Tokenize(sentence, gojieba.SearchMode, !useHmm)
fmt.Println(sentence, "\tTokenize Search Mode 搜索引擎模式:", words)
words = seg.Tokenize(sentence, gojieba.DefaultMode, !useHmm)
fmt.Println(sentence, "\tTokenize Default Mode搜索引擎模式:", words)
word2 := seg.ExtractWithWeight(sentence, 5)
fmt.Println(sentence, "\tExtract:", word2)
return
}
运行结果
go build -o gojieba
time ./gojieba
万里长城万里长 全模式:万里|万里长城|里长|长城|万里|里长
万里长城万里长 精确模式:万里长城|万里|长
添加新词:万里长
万里长城万里长 精确模式:万里长城|万里长
北京鲜花速递 新词识别:北京|鲜花|速递
北京鲜花速递 搜索引擎模式: 北京|鲜花|速递
北京市朝阳公园 词性标注: 北京市/ns|朝阳/ns|公园/n
鲁迅先生 搜索引擎模式: 鲁迅|先生
鲁迅先生 Tokenize Search Mode 搜索引擎模式: [{鲁迅 0 6} {先生 6 12}]
鲁迅先生 Tokenize Default Mode搜索引擎模式: [{鲁迅 0 6} {先生 6 12}]
鲁迅先生 Extract: [{鲁迅 8.20023407859} {先生 5.56404756434}]
real 0m1.746s
user 0m1.622s
sys 0m0.124s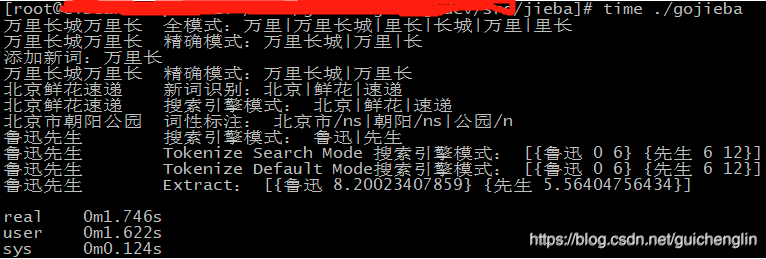
![]() ?
?
性能评测
| 语言 | 源码 | 耗时 |
| C++版本 | CppJieba | 7.5 s |
| Golang版本 | GoJieba | 9.11 s |
| Python版本 | Jieba | 88.7 s |
计算分词过程的耗时,不包括加载词典耗时,CppJieba性能是GoJieba的1.2倍。CppJieba性能详见jieba-performance-comparison,GoJieba由于是C++开发的CppJieba,性能方面仅次于CppJieba,如果追求性能还是可以考虑的。

![]() ?
?
标签:lsp package https 字典 viterbi ring 配置 aic 官方
原文地址:https://www.cnblogs.com/guichenglin/p/12718424.html