标签:时间 isa 写入 contain sql语句 ons 标准 查找 sql解析
以前我要查找数据都是使用like后来发现mysql中也有正则表达式了并且感觉性能要好于like,下面我来给大家分享一下mysql REGEXP正则表达式使用详解,希望此方法对大家有帮助。
在开始这个话题之前我们首先来做一个小实验,比较一下REGEXP和Like他们两个哪个效率高,如果效率太低,我们就没有必要做过多的研究了,实验的代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
<?phpRequire("config.php");//函数:计时函数//用法:Echo Runtime(1);Function Runtime($mode=0){ Static $s; IF(!$mode){ $s=microtime(); Return; } $e=microtime(); $s=Explode(" ", $s); $e=Explode(" ", $e); Return Sprintf("%.2f ms",($e[1]+$e[0]-$s[1]-$s[0])*1000);}//以下测试结果为2300 ms至2330 ms之间For($i=0;$i<10000;$i++){ $Rs=$Mysql->Get("SELECT * FROM `hotel` where address REGEXP ‘^连江县|桃园市‘");}//以下测试结果为2300 ms至2330 ms之间For($i=0;$i<10000;$i++){ $Rs=$Mysql->Get("SELECT * FROM `hotel` where address like ‘连江县%‘ or address like ‘%桃园市%‘");}Echo Runtime(1); |
实验的结果很让人惊喜,那就是他们两个的效率几乎差不多,上下浮动差不了几十毫秒,那么我们就有必要对REGEXP做深入研究了,因为他能够大大的缩短sql语句的长度.对于很长的查询条件来说用这种查询可以很好的缩短sql长度.
MySQL采用Henry Spencer的正则表达式实施,其目标是符合POSIX 1003.2。请参见附录C:感谢。MySQL采用了扩展的版本,以支持在SQL语句中与REGEXP操作符一起使用的模式匹配操作。请参见3.3.4.7节,“模式匹配”。
在本附录中,归纳了在MySQL中可用于REGEXP操作的特殊字符和结构,并给出了一些示例。本附录未包含可在Henry Spencer的regex(7)手册页面中发现的所有细节。该手册页面包含在MySQL源码分发版中,位于regex目录下的regex.7文件中。
正则表达式描述了一组字符串。最简单的正则表达式是不含任何特殊字符的正则表达式。例如,正则表达式hello匹配hello。
非平凡的正则表达式采用了特殊的特定结构,从而使得它们能够与1个以上的字符串匹配。例如,正则表达式hello|word匹配字符串hello或字符串word。
作为一个更为复杂的示例,正则表达式B[an]*s匹配下述字符串中的任何一个:Bananas,Baaaaas,Bs,以及以B开始、以s结束、并在其中包含任意数目a或n字符的任何其他字符串。
对于REGEXP操作符,正则表达式可以使用任何下述特殊字符和结构:
^匹配字符串的开始部分。
mysql> SELECT ‘fo\nfo‘ REGEXP ‘^fo$‘;
-> 0
mysql> SELECT ‘fofo‘ REGEXP ‘^fo‘;
-> 1
$匹配字符串的结束部分。
mysql> SELECT ‘fo\no‘ REGEXP ‘^fo\no$‘;
-> 1
mysql> SELECT ‘fo\no‘ REGEXP ‘^fo$‘;
-> 0
.匹配任何字符(包括回车和新行)。
mysql> SELECT ‘fofo‘ REGEXP ‘^f.*$‘;
-> 1
mysql> SELECT ‘fo\r\nfo‘ REGEXP ‘^f.*$‘;
-> 1
a*匹配0或多个a字符的任何序列。
mysql> SELECT ‘Ban‘ REGEXP ‘^Ba*n‘;
-> 1
mysql> SELECT ‘Baaan‘ REGEXP ‘^Ba*n‘;
-> 1
mysql> SELECT ‘Bn‘ REGEXP ‘^Ba*n‘;
-> 1
a+匹配1个或多个a字符的任何序列。
mysql> SELECT ‘Ban‘ REGEXP ‘^Ba+n‘;
-> 1
mysql> SELECT ‘Bn‘ REGEXP ‘^Ba+n‘;
-> 0
a?匹配0个或1个a字符。
mysql> SELECT ‘Bn‘ REGEXP ‘^Ba?n‘;
-> 1
mysql> SELECT ‘Ban‘ REGEXP ‘^Ba?n‘;
-> 1
mysql> SELECT ‘Baan‘ REGEXP ‘^Ba?n‘;
-> 0
de|abc匹配序列de或abc。
mysql> SELECT ‘pi‘ REGEXP ‘pi|apa‘;
-> 1
mysql> SELECT ‘axe‘ REGEXP ‘pi|apa‘;
-> 0
mysql> SELECT ‘apa‘ REGEXP ‘pi|apa‘;
-> 1
mysql> SELECT ‘apa‘ REGEXP ‘^(pi|apa)$‘;
-> 1
mysql> SELECT ‘pi‘ REGEXP ‘^(pi|apa)$‘;
-> 1
mysql> SELECT ‘pix‘ REGEXP ‘^(pi|apa)$‘;
-> 0
(abc)*匹配序列abc的0个或多个实例。
mysql> SELECT ‘pi‘ REGEXP ‘^(pi)*$‘;
-> 1
mysql> SELECT ‘pip‘ REGEXP ‘^(pi)*$‘;
-> 0
mysql> SELECT ‘pipi‘ REGEXP ‘^(pi)*$‘;
-> 1
{1}, {2,3}
{n}或{m,n}符号提供了编写正则表达式的更通用方式,能够匹配模式的很多前述原子(或“部分”)。m和n均为整数。
a*可被写入为a{0,}。
a+可被写入为a{1,}。
a?可被写入为a{0,1}。
更准确地讲,a{n}与a的n个实例准确匹配。a{n,}匹配a的n个或更多实例。a{m,n}匹配a的m~n个实例,包含m和n。
m和n必须位于0~RE_DUP_MAX(默认为255)的范围内,包含0和RE_DUP_MAX。如果同时给定了m和n,m必须小于或等于n。
mysql> SELECT ‘abcde‘ REGEXP ‘a[bcd]{2}e‘;
-> 0
mysql> SELECT ‘abcde‘ REGEXP ‘a[bcd]{3}e‘;
-> 1
mysql> SELECT ‘abcde‘ REGEXP ‘a[bcd]{1,10}e‘;
-> 1
[a-dX], [^a-dX]
匹配任何是(或不是,如果使用^的话)a、b、c、d或X的字符。两个其他字符之间的“-”字符构成一个范围,与从第1个字符开始到第2个字符之间的所有字符匹配。例如,[0-9]匹配任何十进制数字 。要想包含文字字符“]”,它必须紧跟在开括号“[”之后。要想包含文字字符“-”,它必须首先或最后写入。对于[]对内未定义任何特殊含义的任何字符,仅与其本身匹配。
mysql> SELECT ‘aXbc‘ REGEXP ‘[a-dXYZ]‘;
-> 1
mysql> SELECT ‘aXbc‘ REGEXP ‘^[a-dXYZ]$‘;
-> 0
mysql> SELECT ‘aXbc‘ REGEXP ‘^[a-dXYZ]+$‘;
-> 1
mysql> SELECT ‘aXbc‘ REGEXP ‘^[^a-dXYZ]+$‘;
-> 0
mysql> SELECT ‘gheis‘ REGEXP ‘^[^a-dXYZ]+$‘;
-> 1
mysql> SELECT ‘gheisa‘ REGEXP ‘^[^a-dXYZ]+$‘;
-> 0
[.characters.]
在括号表达式中(使用[和]),匹配用于校对元素的字符序列。字符为单个字符或诸如新行等字符名。在文件regexp/cname.h中,可找到字符名称的完整列表。
mysql> SELECT ‘~‘ REGEXP ‘[[.~.]]‘;
-> 1
mysql> SELECT ‘~‘ REGEXP ‘[[.tilde.]]‘;
-> 1
[=character_class=]
在括号表达式中(使用[和]),[=character_class=]表示等同类。它与具有相同校对值的所有字符匹配,包括它本身,例如,如果o和(+)均是等同类的成员,那么[[=o=]]、[[=(+)=]]和[o(+)]是同义词。等同类不得用作范围的端点。
[:character_class:]
在括号表达式中(使用[和]),[:character_class:]表示与术语类的所有字符匹配的字符类。标准的类名称是:
|
alnum |
文字数字字符 |
|
alpha |
文字字符 |
|
blank |
空白字符 |
|
cntrl |
控制字符 |
|
digit |
数字字符 |
|
graph |
图形字符 |
|
lower |
小写文字字符 |
|
|
图形或空格字符 |
|
punct |
标点字符 |
|
space |
空格、制表符、新行、和回车 |
|
upper |
大写文字字符 |
|
xdigit |
十六进制数字字符 |
它们代表在ctype(3)手册页面中定义的字符类。特定地区可能会提供其他类名。字符类不得用作范围的端点。
mysql> SELECT ‘justalnums‘ REGEXP ‘[[:alnum:]]+‘;
-> 1
mysql> SELECT ‘!!‘ REGEXP ‘[[:alnum:]]+‘;
-> 0
[[:<:]], [[:>:]]
这些标记表示word边界。它们分别与word的开始和结束匹配。word是一系列字字符,其前面和后面均没有字字符。字字符是alnum类中的字母数字字符或下划线(_)。
mysql> SELECT ‘a word a‘ REGEXP ‘[[:<:]]word[[:>:]]‘;
-> 1
mysql> SELECT ‘a xword a‘ REGEXP ‘[[:<:]]word[[:>:]]‘;
-> 0
要想在正则表达式中使用特殊字符的文字实例,应在其前面加上2个反斜杠“\”字符。MySQL解析程序负责解释其中一个,正则表达式库负责解释另一个。例如,要想与包含特殊字符“+”的字符串“1+2”匹配,在下面的正则表达式中,只有最后一个是正确的:
mysql> SELECT ‘1+2‘ REGEXP ‘1+2‘;
-> 0
mysql> SELECT ‘1+2‘ REGEXP ‘1\+2‘;
-> 0
mysql> SELECT ‘1+2‘ REGEXP ‘1\\+2‘;
-> 1
以下是可用于随REGEXP操作符的表的模式。
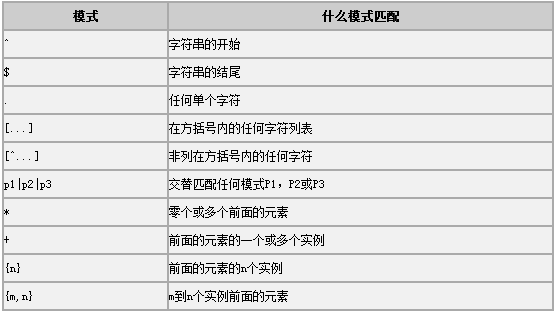
应用示例,查找用户表中Email格式错误的用户记录:
|
1
2
3
|
SELECT * FROM usersWHERE email NOT REGEXP ‘^[A-Z0-9._%-]+@[A-Z0-9.-]+.[A-Z]{2,4}$‘ |
MySQL数据库中正则表达式的语法,主要包括各种符号的含义。
(^)字符
匹配字符串的开始位置,如“^a”表示以字母a开头的字符串。
|
1
2
3
4
5
6
7
8
|
mysql> select ‘xxxyyy‘ regexp ‘^xx‘;+-----------------------+| ‘xxxyyy‘ regexp ‘^xx‘ |+-----------------------+| 1 |+-----------------------+1 row in set (0.00 sec) |
查询xxxyyy字符串中是否以xx开头,结果值为1,表示值为true,满足条件。
($)字符
匹配字符串的结束位置,如“X^”表示以字母X结尾的字符串。
(.)字符
这个字符就是英文下的点,它匹配任何一个字符,包括回车、换行等。
(*)字符
星号匹配0个或多个字符,在它之前必须有内容。如:
|
1
|
mysql> select ‘xxxyyy‘ regexp ‘x*‘; |
这个SQL语句,正则匹配为true。
(+)字符
加号匹配1个或多个字符,在它之前也必须有内容。加号跟星号的用法类似,只是星号允许出现0次,加号则必须至少出现一次。
(?)字符
问号匹配0次或1次。
实例:
现在根据上面的表,可以装置各种不同类型的SQL查询以满足要求。在这里列出一些理解。考虑我们有一个表为person_tbl和有一个字段名为名称:
查询找到所有的名字以‘st‘开头
|
1
|
mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘^st‘; |
查询找到所有的名字以‘ok‘结尾
|
1
|
mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘ok$‘; |
查询找到所有的名字包函‘mar‘的字符串
|
1
|
mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘mar‘; |
查询找到所有名称以元音开始和‘ok‘结束 的
|
1
|
mysql> SELECT name FROM person_tbl WHERE name REGEXP ‘^[aeiou]|ok$‘; |
一个正则表达式中的可以使用以下保留字
^
所匹配的字符串以后面的字符串开头
|
1
2
|
mysql> select "fonfo" REGEXP "^fo$"; -> 0(表示不匹配) mysql> select "fofo" REGEXP "^fo"; -> 1(表示匹配) |
$
所匹配的字符串以前面的字符串结尾
|
1
2
3
|
mysql> select "fono" REGEXP "^fono$"; -> 1(表示匹配) mysql> select "fono" REGEXP "^fo$"; -> 0(表示不匹配) . |
匹配任何字符(包括新行)
|
1
2
|
mysql> select "fofo" REGEXP "^f.*"; -> 1(表示匹配) mysql> select "fonfo" REGEXP "^f.*"; -> 1(表示匹配) |
a*
匹配任意多个a(包括空串)
|
1
2
3
|
mysql> select "Ban" REGEXP "^Ba*n"; -> 1(表示匹配) mysql> select "Baaan" REGEXP "^Ba*n"; -> 1(表示匹配) mysql> select "Bn" REGEXP "^Ba*n"; -> 1(表示匹配) |
a+
匹配任意多个a(不包括空串)
|
1
2
|
mysql> select "Ban" REGEXP "^Ba+n"; -> 1(表示匹配) mysql> select "Bn" REGEXP "^Ba+n"; -> 0(表示不匹配) |
a?
匹配一个或零个a
|
1
2
3
|
mysql> select "Bn" REGEXP "^Ba?n"; -> 1(表示匹配) mysql> select "Ban" REGEXP "^Ba?n"; -> 1(表示匹配) mysql> select "Baan" REGEXP "^Ba?n"; -> 0(表示不匹配) |
de|abc
匹配de或abc
|
1
2
3
4
5
6
|
mysql> select "pi" REGEXP "pi|apa"; -> 1(表示匹配) mysql> select "axe" REGEXP "pi|apa"; -> 0(表示不匹配) mysql> select "apa" REGEXP "pi|apa"; -> 1(表示匹配) mysql> select "apa" REGEXP "^(pi|apa)$"; -> 1(表示匹配) mysql> select "pi" REGEXP "^(pi|apa)$"; -> 1(表示匹配) mysql> select "pix" REGEXP "^(pi|apa)$"; -> 0(表示不匹配) |
(abc)*
匹配任意多个abc(包括空串)
|
1
2
3
|
mysql> select "pi" REGEXP "^(pi)*$"; -> 1(表示匹配) mysql> select "pip" REGEXP "^(pi)*$"; -> 0(表示不匹配) mysql> select "pipi" REGEXP "^(pi)*$"; -> 1(表示匹配) |
{1}
{2,3}
这是一个更全面的方法,它可以实现前面好几种保留字的功能
a*
可以写成a{0,}
a+
可以写成a{1,}
a?
可以写成a{0,1}
在{}内只有一个整型参数i,表示字符只能出现i次;在{}内有一个整型参数i,后面跟一个“,”,表示字符可以出现i次或i次以上;在{}内只有一个整型参数i,后面跟一个“,”,再跟一个整型参数j,表示字符只能出现i次以上,j次以下(包括i次和j次)。其中的整型参数必须大于等于0,小于等于 RE_DUP_MAX(默认是255)。 如果有两个参数,第二个必须大于等于第一个
[a-dX]
匹配“a”、“b”、“c”、“d”或“X”
[^a-dX]
匹配除“a”、“b”、“c”、“d”、“X”以外的任何字符。
“[”、“]”必须成对使用
|
1
2
3
4
5
6
|
mysql> select "aXbc" REGEXP "[a-dXYZ]"; -> 1(表示匹配) mysql> select "aXbc" REGEXP "^[a-dXYZ]$"; -> 0(表示不匹配) mysql> select "aXbc" REGEXP "^[a-dXYZ]+$"; -> 1(表示匹配) mysql> select "aXbc" REGEXP "^[^a-dXYZ]+$"; -> 0(表示不匹配) mysql> select "gheis" REGEXP "^[^a-dXYZ]+$"; -> 1(表示匹配) mysql> select "gheisa" REGEXP "^[^a-dXYZ]+$"; -> 0(表示不匹配) |
标签:时间 isa 写入 contain sql语句 ons 标准 查找 sql解析
原文地址:https://www.cnblogs.com/wxb-km/p/12718985.html