标签:谷歌 col 相关 bsp 联网 索引 idt 就是 爬虫
01-Python 零基础入门爬虫开发-爬虫简介
一 什么是爬虫?
网络爬虫(网络蜘蛛 网络机器人)
就是模拟浏览器去访问和获取互联网上信息的一个程序
二 爬虫的分类
通用网络爬虫
百度 谷歌 雅虎... 搜索引擎
特点:关键字获取既定目标 覆盖率很大
聚焦网络爬虫
特点:到互联网上有选择有目的的去抓取特定的目标和相关的主体内容
增量式网络爬虫
特点:只采取增量式的更新或者只爬行新产生或者是已经发生变化的网页
深层网络爬虫
表层
深层 大部分内容是币可以通过静态链接获取到的,隐藏在搜索表单之后的一些数据,有可能需要用户提交一些关键词才可以获得的WEB页面
三 案例演示
聚焦网络爬虫
一个静态为主的web页面 爬取的数据表情包
每张图片都不一样 地址指向它本身 只需找到图片的地址
图片的目标网站 https://qq.yh31.com/zjbq/16100183.html
每张图片所对应的链接只需要在网页源代码中找到就可以了
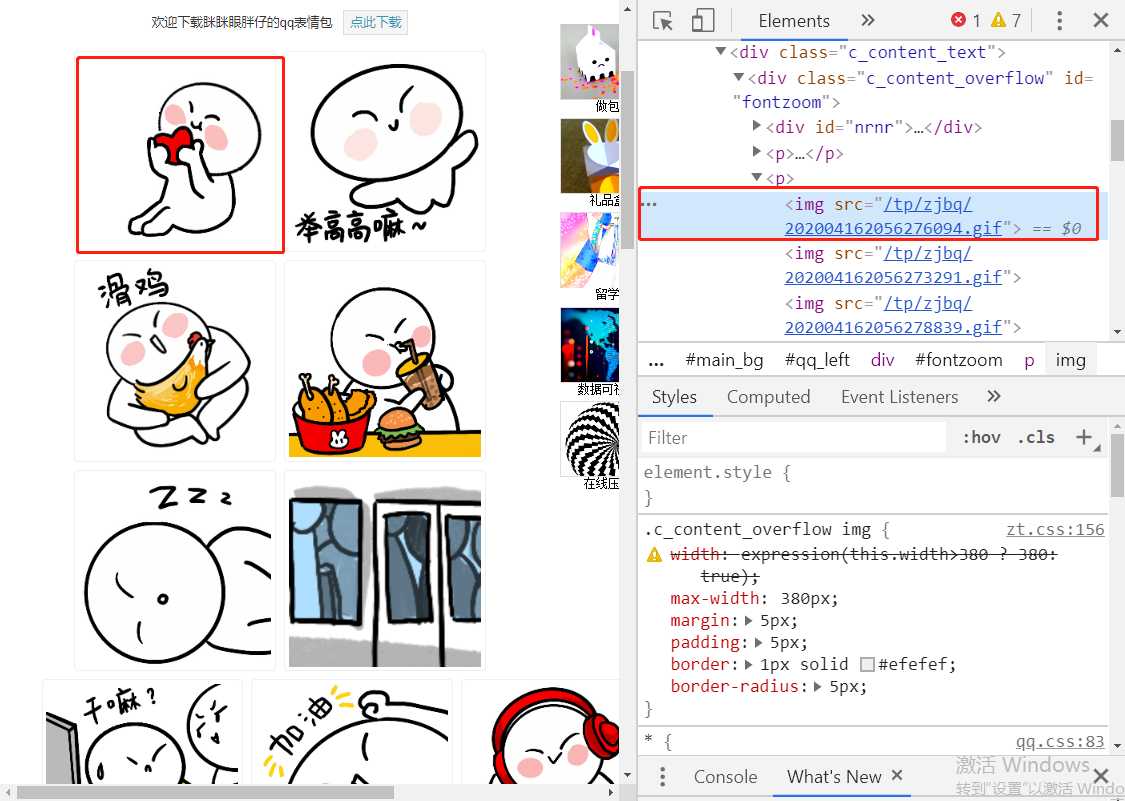
/tp/zjbq/202004162056276094.gif 未找到图片
https://qq.yh31.com/tp/zjbq/202004162056276094.gif 可找到图片
标签:谷歌 col 相关 bsp 联网 索引 idt 就是 爬虫
原文地址:https://www.cnblogs.com/Fairy-02-11/p/12721640.html