标签:插入 print main tle end 获取 xlsx str none
统计某一文件夹下所有表格数据并写入一个新的表格
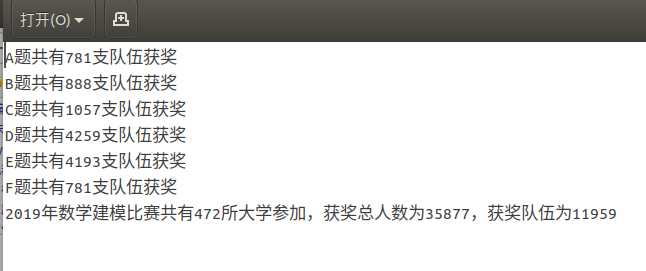
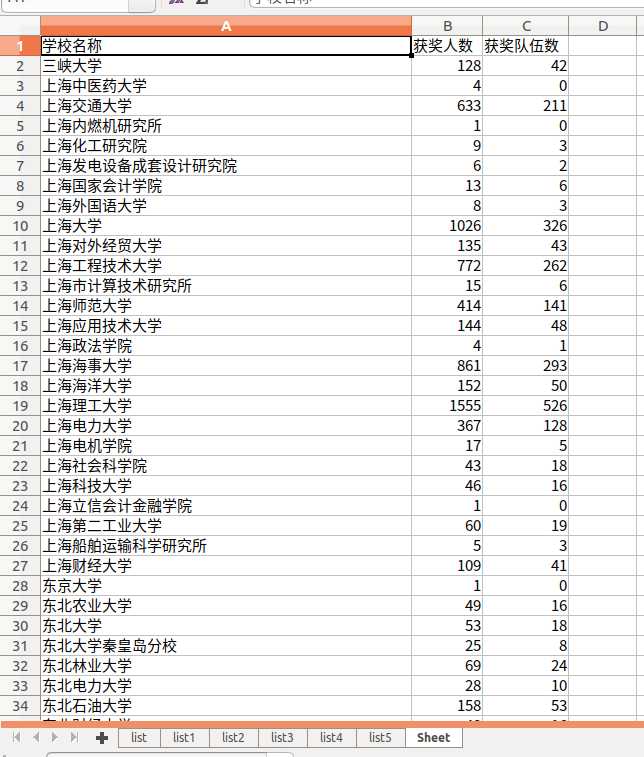
统计了2019年6道赛题每道赛题每个大学的获奖情况以及所有赛题每个大学的获奖情况,队伍数只统计队长所在学校,我这里F题和A题的获奖名单是相同的
1 import openpyxl 2 import os 3 4 5 class ExceltoExcel(): 6 7 def __init__(self, file, new_sheet): 8 self.universityData = {} 9 self.wb = openpyxl.load_workbook(file) 10 # self.wb_new =openpyxl.Workbook() # 新建一个表格来存储生成的数据 11 self.sheet = self.wb.active 12 self.new_sheet = new_sheet # 新表单 13 self.maxrow = self.sheet.max_row 14 self.maxcol = self.sheet.max_column 15 16 17 def excel_to_dict(self): 18 ‘‘‘ 19 统计每个大学全部的获奖数量,分别列出是几等奖和对应的数量 20 {‘同济大学‘:{‘一等奖‘:{‘team‘:1,‘num‘=3},‘二等奖‘:{‘team‘:2,‘num‘=6},‘三等奖‘:{‘team‘:1,‘num‘=3},‘成功参与奖‘:{‘team‘:1,‘num‘=3}}, 21 ‘清华大学‘:{‘一等奖‘:{‘team‘:1,‘num‘=3},‘二等奖‘:{‘team‘:1,‘num‘=3},‘三等奖‘:{‘team‘:1,‘num‘=3},‘成功参与奖‘:{‘team‘:1,‘num‘=3}},...} 22 统计所有人数 23 Fill in universityData with each rewardship‘s popularity 24 ‘‘‘ 25 # tolal_team = self.maxrow 26 for row in range(2, self.maxrow + 1): 27 # 取每个单元格的数据 28 sheet_col = [‘F‘, ‘H‘, ‘J‘] 29 rewardcell = self.sheet[‘D‘ + str(row)].value # D列奖项 30 rewards = [‘一等奖‘, ‘二等奖‘, ‘三等奖‘, ‘成功参与奖‘] 31 for k in sheet_col: 32 university = self.sheet[k + str(row)].value # 每列大学的名称 33 # team = self.sheet[‘C‘ + str(row)].value # C列队伍 34 # 确定键值 35 self.universityData.setdefault(university, {}) 36 for reward in rewards: 37 if reward == rewardcell: 38 self.universityData[university].setdefault(rewardcell, {‘team‘: 0, ‘num‘: 0}) 39 self.universityData[university][rewardcell][‘num‘] += 1 # 统计各个奖项的所有人数 40 else: 41 self.universityData[university].setdefault(reward, {‘team‘: 0, ‘num‘: 0}) 42 43 if k == ‘F‘: 44 self.universityData[university][rewardcell][‘team‘] += 1 # 只统计队长所在大学 45 self.universityData = sorted(self.universityData.items(), key=lambda item: item[0]) # 按照键值排序返回元祖 46 self.universityData = dict(self.universityData) # 将元祖转换成字典 47 total_sum.append(self.universityData) 48 # total_sum[str(self.new_sheet.title)] = self.universityData # 在字典total_sum中添加新的键,每个表单的字典作为值进行存储 49 # print(‘universityData‘, self.universityData) 50 # print(type(self.universityData)) 51 return self.universityData, total_sum 52 53 # 查找单个键 54 def find(self, target, dictData, notFound=‘没找到‘): 55 # 倒序查找第一个出现的需要查找的键的值 56 queue = [dictData] # 将字典存入列表 57 while len(queue) > 0: 58 data = queue.pop() # data是在queue中取出的最后一个元素,也就是原始字典;此时的queue为空列表[] 59 print(‘data‘, data) 60 for key, value in data.items(): 61 if key == target: 62 return value 63 elif type(value) == dict: 64 queue.append(value) 65 return notFound 66 67 # 有多个同名键在字典里时,可以用这个方法 68 def findAll(self, target, dictData, notFound=None): 69 # 倒序查找所有出现的需要查找的键的值 70 if notFound is None: 71 notFound = [] 72 queue = [dictData] 73 result = [] 74 while len(queue) > 0: 75 data = queue.pop() 76 for key, value in data.items(): 77 if key == target: 78 result.append(value) 79 elif type(value) == dict: 80 queue.append(value) 81 if not result: result = notFound 82 return result 83 84 def write_list_to_excel(self, dictData, num_list, team_list): 85 list_slice = [] # 人数切片 86 team_slice = [] # 队伍切片 87 sublist_sum = [] # 每个人数切片的和 88 team_sum = [] # 每个队伍切片的和 89 k = 0 90 row_1 = [‘学校名称‘,‘一等奖‘,‘二等奖‘,‘三等奖‘,‘成功参与奖‘,‘总人数‘,‘队伍数量‘] 91 for i in range(len(row_1)): 92 self.new_sheet.cell(row=1,column=i+1,value=row_1[i]) 93 university_name = [] 94 for key in dictData.keys(): 95 university_name.append(key) 96 for index, name in enumerate(university_name): 97 self.new_sheet[‘A‘+str(index+2)] = name 98 while k < len(num_list): 99 sub_list = num_list[k:k+4] # 人数子集 100 team_sub = team_list[k:k+4] # 队伍子集 101 list_slice.append(sub_list) # 切片后存入列表 102 team_slice.append(team_sub) 103 sumlist = sum(sub_list) # 计算每个子集的和 104 teamsum = sum(team_sub) 105 sublist_sum.append(sumlist) # 将每个子集的和加入列表 106 team_sum.append(teamsum) 107 k += 4 108 if k > len(num_list): 109 break 110 for row in range(2, len(university_name)+2): 111 for col in range(2, 6): 112 self.new_sheet.cell(column=col, row=row, value=list_slice[row-2][col-2]) 113 self.new_sheet.cell(column=6, row=row, value=sublist_sum[row-2]) 114 self.new_sheet.cell(column=7, row=row, value=team_sum[row - 2]) 115 return university_name, list_slice, sublist_sum, team_sum 116 117 118 class TotalData(ExceltoExcel): 119 def __init__(self): 120 super(TotalData,self).__init__(file, new_sheet) 121 self.sheet_summary = wb_new[‘Sheet‘] # 获取要写入的表单 122 123 def sum(self, totalsum): 124 keys = [] # 包含6个字典中所有的键 125 # alldata = [] # 每个大学在所有表单中的获奖情况 126 all_num = [] # 每个大学所有获奖人数的总和 127 all_team = [] # 每个大学所有获奖队伍总数,只统计队长所在的队伍 128 row_1 = [‘学校名称‘, ‘获奖人数‘, ‘获奖队伍数‘] 129 for i in range(len(row_1)): 130 self.sheet_summary.cell(row=1,column=i+1,value=row_1[i]) 131 for elements in totalsum: # 循环遍历每个表单字典 132 for element in elements.keys(): 133 # keys()方法返回包含所有键的列表,values()方法返回所有值的列表,.items()方法返回包含键值对的元祖 134 keys.append(element) # 键为每个大学的名称,keys中包含所有表单所有大学的名称 135 all_key = list(set(keys)) # 去除列表中的重复元素 136 all_key.sort() 137 # print(‘all_key‘, all_key) 138 for key in all_key: 139 # print(‘key‘, key) 140 one_num = [] # 用来存储每一个大学每个赛题的获奖人数总和 141 one_team = [] # 用来存储每一个大学每个赛题的获奖队伍总和 142 # i为要查找的键,此处是大学名称,在全部的大字典中查找大学,列出每个表单中同一个大学对应的在6个赛题中的获奖情况 143 # print(‘self.totalsum1‘, self.totalsum) 144 result_in_alldata = self.findAll(key, list_to_dict(totalsum)) 145 result_in_alldata.reverse() 146 # print(‘alldata‘, result_in_alldata) 147 # alldata.append(result_in_alldata) 148 for data in result_in_alldata: # 依次遍历每道题的获奖情况 149 # print(‘data‘, data) 150 num = self.findAll(‘num‘, data) # 每一个大学在每一个赛题的每一个奖项的获奖人数 151 num.reverse() 152 # print(‘num‘, num) 153 team = self.findAll(‘team‘, data) # 每一个大学在每一个赛题的每一个奖项的获奖队伍数 154 team.reverse() 155 one_num.append(sum(num)) # 每个赛题的获奖人数总和 156 one_team.append(sum(team)) 157 all_num.append(sum(one_num)) # 每个大学所有获奖人数总和 158 all_team.append(sum(one_team)) 159 for row in range(2, len(all_key)+2): 160 self.sheet_summary.cell(column=1, row=row, value=all_key[row - 2]) 161 self.sheet_summary.cell(column=2, row=row, value=all_num[row - 2]) 162 self.sheet_summary.cell(column=3, row=row, value=all_team[row - 2]) 163 164 return all_key, all_num, all_team 165 166 167 def list_to_dict(total_list): 168 new_total_dict = {} 169 for index, dic in enumerate(total_list): 170 new_total_dict[index+1] = dic 171 return new_total_dict 172 173 174 if __name__ == ‘__main__‘: 175 file_path = ‘./file‘ # excel文件路径 176 files = [] # 存储excel文件名 177 list1 = os.listdir(file_path) # 列出excel文件路径下所有的文件 178 list1.sort(key=lambda x: x[4:5]) # 按照题目顺序排序 179 total_sum = [] 180 # print(‘list‘, list) 181 for i in range(len(list1)): 182 item = os.path.join(file_path, list1[i]) 183 files.append(item) 184 # print(‘files‘, files) 185 wb_new = openpyxl.Workbook() # 新建一个表格来存储生成的数据 186 f = open(‘result.txt‘, ‘w‘) 187 for k,file in enumerate(files): 188 new_sheet = wb_new.create_sheet(‘list‘, index=k) # 插入新表单 189 excel = ExceltoExcel(file, new_sheet) 190 dictData, total_sum = excel.excel_to_dict() # 得到当前表格排序后的字典 191 # find_one = excel1.find(‘team‘, dictData) 192 find_num = excel.findAll(‘num‘, dictData) # 查找当前表格每个大学每个奖项的获奖人数 193 find_team = excel.findAll(‘team‘, dictData) # # 查找当前表格每个大学每个奖项的获奖队伍数,只统计队长所在的学校 194 find_num.reverse() # 正序排列 195 find_team.reverse() # 正序排列 196 _, _, _, team_sum = excel.write_list_to_excel(dictData,find_num, find_team) 197 wb_new.save(‘result.xlsx‘) 198 # print(‘university name‘, university) 199 # print(‘list_slice‘, list_slice) 200 # print(‘sublist_sum‘, sublist_sum) 201 title = file.split(‘/‘)[2][4:5] # 字符串分割提取题目,原标题为‘./file/2019A.xlsx‘ 202 print(‘{}题共有{}支队伍获奖‘.format(title, sum(team_sum))) 203 f.write(‘{}题共有{}支队伍获奖\n‘.format(title, sum(team_sum))) 204 # print(‘total_sum‘, total_sum) 205 total_data = TotalData() # total_sum是包含每个表格的所有字典即总共6个字典的列表 206 all_university, num, team = total_data.sum(total_sum) 207 print(‘2019年数学建模比赛共有{}所大学参加,获奖总人数为{},获奖队伍为{}‘.format(len(all_university),sum(num),sum(team))) 208 f.write(‘2019年数学建模比赛共有{}所大学参加,获奖总人数为{},获奖队伍为{}‘.format(len(all_university),sum(num),sum(team))) 209 wb_new.save(‘result.xlsx‘)
【Python】openpyxl统计2019年数学建模获奖情况【2】
标签:插入 print main tle end 获取 xlsx str none
原文地址:https://www.cnblogs.com/DJames23/p/12730387.html