标签:举例 报错 可视化 大型数据库 数字类型 第一个 key 目录 sel
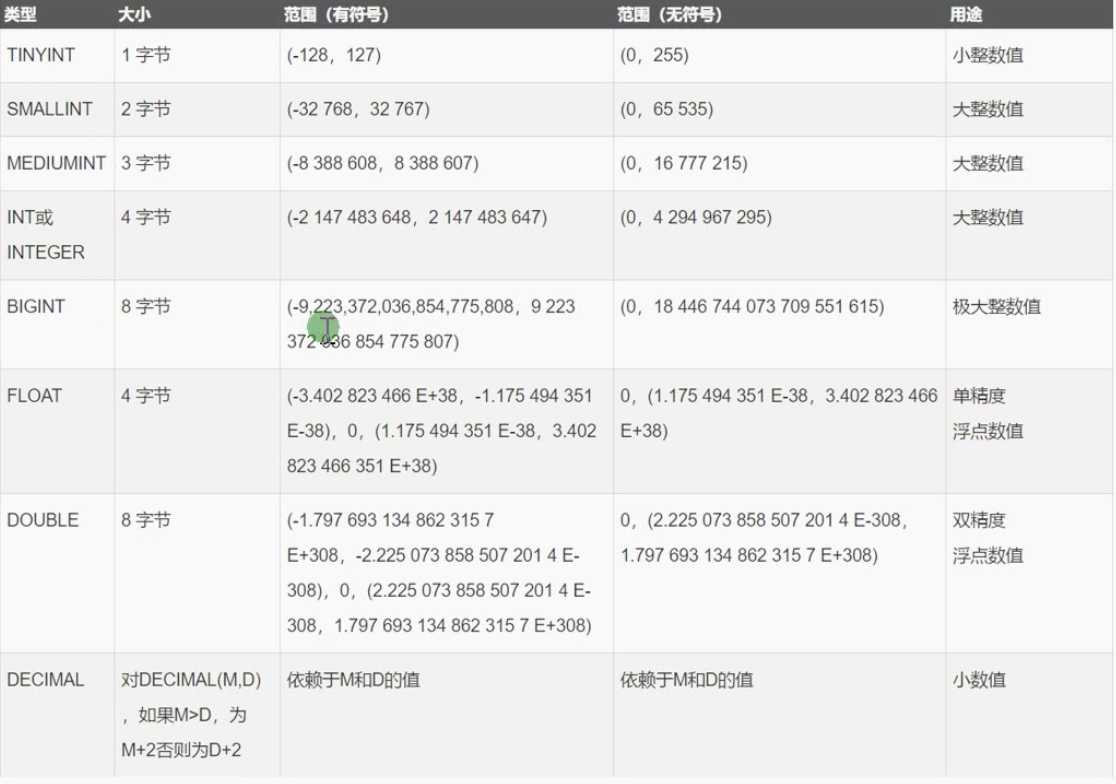
使用原则:根据业务来决定,一般来时能用小范围的就别用大范围的。
常用的:DATATIME 和 TIMESTAMP两个
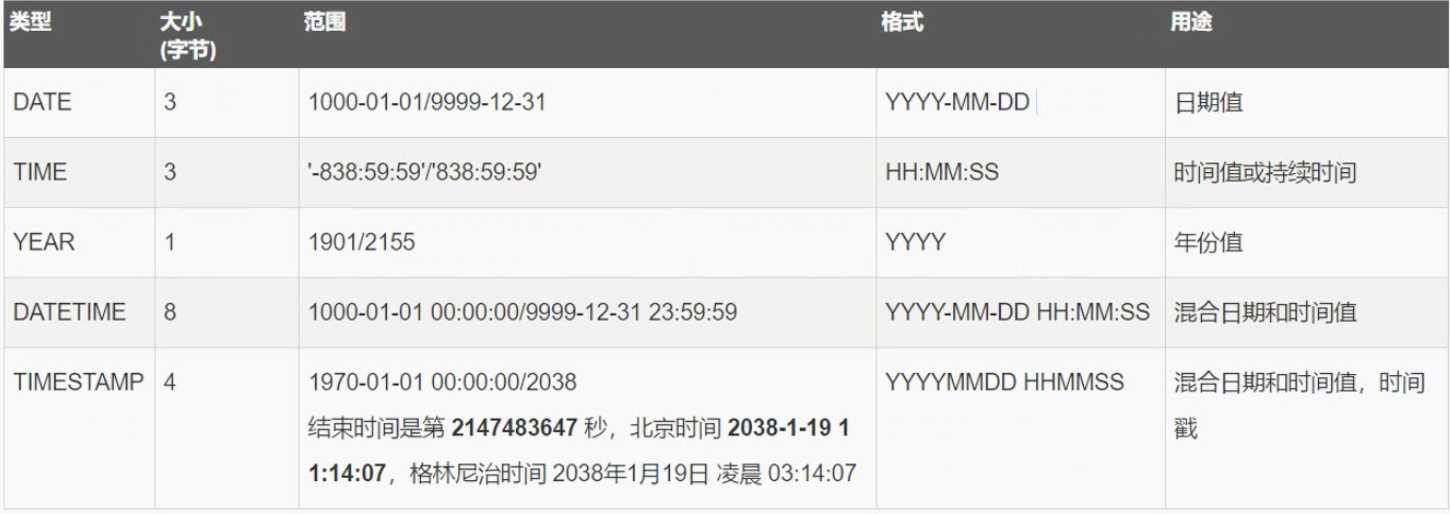
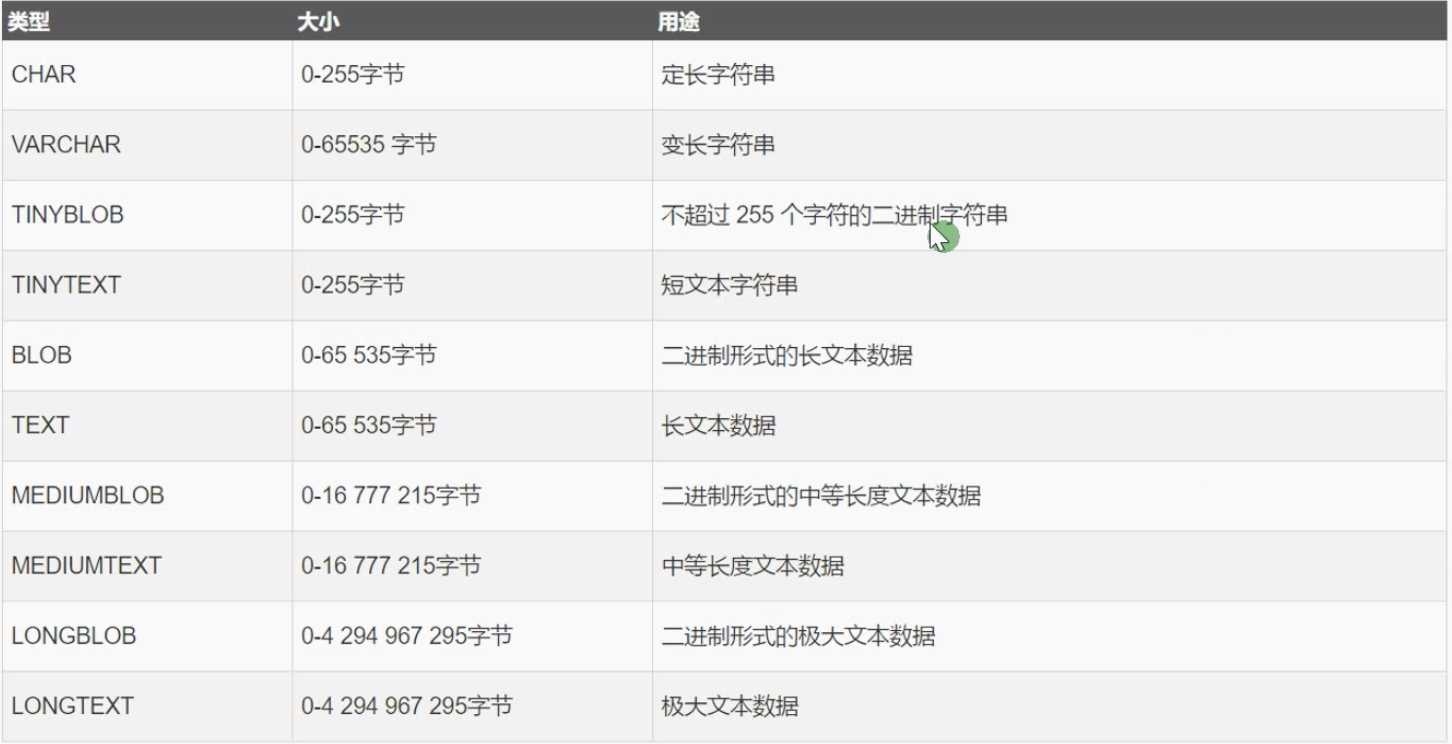
常用的:CHAR 和 VARCHAR 两个
因为可视化操作效率高,所以通过Navicat来创建,当然也可以通过命令行来创建表
id:一般要设置为自动递增
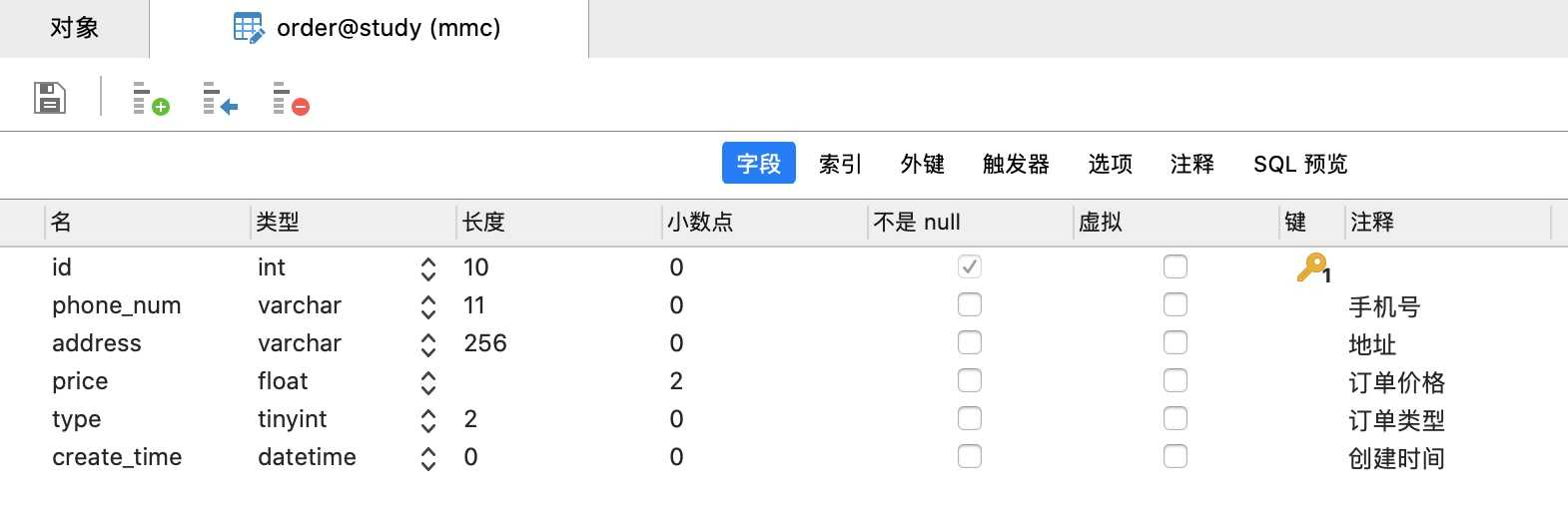
CREATE TABLE `order` ( `id` int(10) NOT NULL AUTO_INCREMENT, `phone_num` varchar(11) DEFAULT NULL COMMENT ‘手机号‘, `address` varchar(256) DEFAULT NULL COMMENT ‘地址‘, `price` decimal(10,0) DEFAULT NULL COMMENT ‘订单价格‘, `type` tinyint(2) DEFAULT NULL COMMENT ‘订单类型‘, `create_time` datetime DEFAULT NULL COMMENT ‘创建时间‘, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8;
id 一般不需要用户来操作
INSERT INTO `order` (phone_num,address,price,type,create_time) VALUES (‘13331039702‘,‘北京‘,‘19.9‘, ‘1‘,‘2019-10-16 18:00:09‘);
INSERT INTO `order` (phone_num,address,price,type,create_time) VALUES
(‘13331039702‘,‘北京‘,‘19.9‘, ‘1‘,‘2019-10-16 18:00:09‘),
(‘13331039703‘,‘上海‘,‘119.9‘, ‘2‘,‘2019-10-18 19:00:09‘),
(‘13331039704‘,‘广州‘,‘129.9‘, ‘2‘,‘2019-10-19 20:00:09‘);
DELETE FROM `order` WHERE id = 1;
SELECT * FROM `order` WHERE address=‘北京‘;
SELECT phone_num, price FROM `order` WHERE address=‘北京‘;
SELECT * FROM `order` WHERE phone_num LIKE ‘13331%‘;
SELECT * FROM `order` WHERE phone_num LIKE ‘%9703‘;
SELECT * FROM `order` WHERE phone_num LIKE ‘%1039%‘;
select * from `order` where price BETWEEN 9 and 20; -- [9,20]闭区间,包含
select * from `order` where price in (19.9, 119.9); -- 查询到内容必须是()内的值
select * from `order` where price not IN (20, 30,40); -- 查到的结果不是()内容的值
UPDATE `order` SET address = ‘杭州‘ WHERE id=3; -- 修改单个字段
UPDATE `order` SET address = ‘杭州‘,type = 2 WHERE id=4; -- 修改多个字段
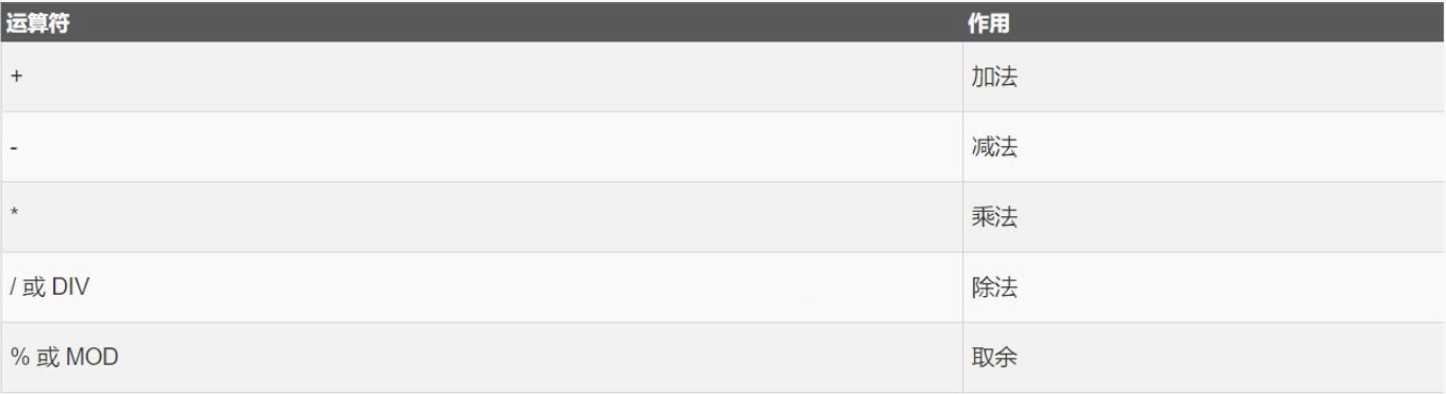

max(最大)、min(最小)、avg(平均)、sum(求和)、count(总数)
SELECT MAX(price) FROM `order` WHERE address = ‘北京‘; -- 符合条件的最大值
SELECT MIN(price) FROM `order` WHERE address = ‘北京‘; -- 符合条件的最小值
SELECT SUM(price) FROM `order` WHERE address = ‘北京‘; -- 符合条件的总和
SELECT AVG(price) FROM `order` WHERE address = ‘北京‘; -- 符合条件的平均值
SELECT COUNT(*) FROM `order` WHERE address = ‘杭州‘; -- 统计符合条件的数据的行数
根据某个字段把查询出来的结果进行排序
-- 按照价格字段排序
SELECT * FROM `order` ORDER BY price; -- 默认是按照升序排列的
SELECT * FROM `order` ORDER BY price ASC; -- asc表示升序,同默认
SELECT * FROM `order` ORDER BY price DESC; -- desc表示倒序
去除重复的数据
-- 把价格相同的数据进行去重
SELECT DISTINCT(price) FROM `order` ;
如果只想查询几条(10,20)数据,可以通过limit进行限制
在分页功能中大量使用
SELECT * FROM `order` LIMIT 4; -- 从查询结果里只取前4条数据
SELECT * FROM `order` LIMIT 0,3; -- 0表示从第一个位置开始往后取3条数据
SELECT * FROM `order` LIMIT 3,4; -- 3表示从第三个位置开始取4条数据,不包给3的位置
按照表中的某一个或者某多个字段,将数据进行分组,一般用于将数据进行分类汇总
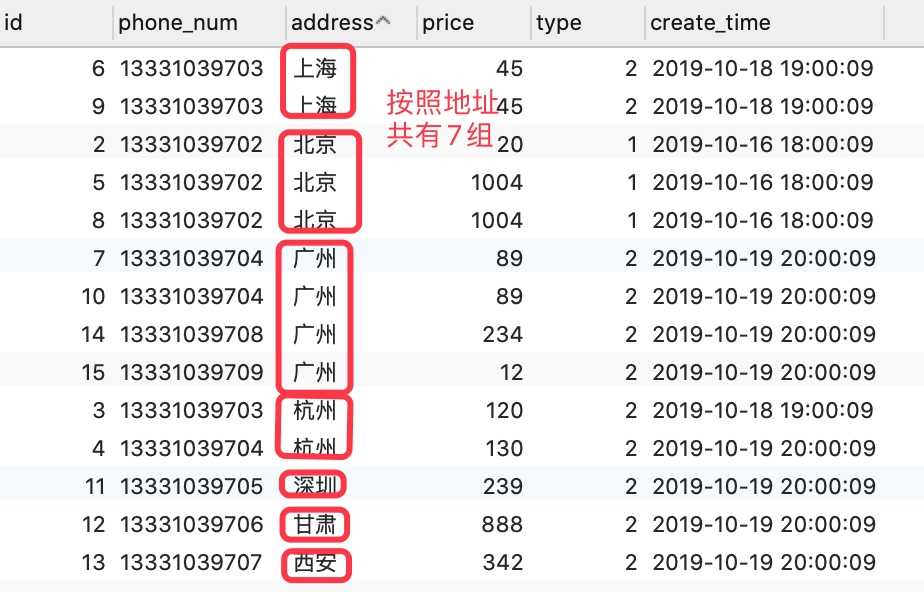
需求1:得出每个城市下面的总价格
解析: 需要先根据address进行分组,然后通过聚合函数 sum来求出每个城市的总价格
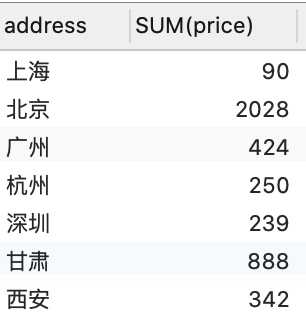
-- 根据单个条件分组 SELECT address, SUM(price) from `order` GROUP BY address;查询结果如下
需求2:得出每个城市下面不同的type的总金额
解析:分析需要根据城市和type进行分组,然后通过聚合函数求出总函数
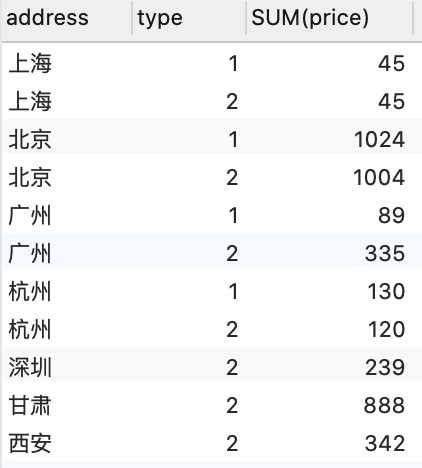
-- 根据多个条件分组 SELECT address, type, SUM(price) from `order` GROUP BY address, type;
注意:
使用 group by 的sql语句,select 后的字段,只能是group by后的字段,如果想要展示其他列,必须要给该列使用聚合函数;
否则默认展示分组里的第一行数据。

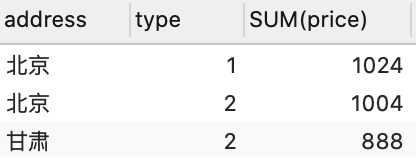
having对分组之后的数据进行过滤
需求:对Order表的数据,按照区域和类型分组,展示每个区域订单总金额>400的数据
SELECT address, type, SUM(price) from `order`
GROUP BY address, type HAVING SUM(price)>400;
SQL语句的执行顺序
from 哪个表 where 什么条件 group by 分组条件 having 过滤条件select 要查询的字段 order by 排序条件
MySql主键(Primary Key)是唯一标识表中每一行的列或者一组列。当地定义表的主键时,必须遵循以下规则:
主要作用:
CREATE TABLE `order` (
`id` int(10) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`phone_num` varchar(11) DEFAULT NULL COMMENT ‘手机号‘,
`address` varchar(256) DEFAULT NULL COMMENT ‘地址‘,
`price` decimal(10,0) DEFAULT NULL COMMENT ‘订单价格‘,
`type` tinyint(2) DEFAULT NULL COMMENT ‘订单类型‘,
`create_time` datetime DEFAULT NULL COMMENT ‘创建时间‘,
) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8;
外键表示一个表中的一个字段被另一个表中的一个字段引用,外键可以在数据库层面保证数据的完整性。
外键的主要是用来做数据约束的。
举例:
在order表里有个user_id 字段,这个字段是来自于 user表的。
order表里所有的user_id的值都必须在user表里。
下面order表里出现一个user_id的值是8在user表里没有的,说明程序有问题了。这种问题就可以在数据库层面通过外键来约束,如果要给order表插入的数据里user_id在user表里不存在,就会报错,无法插入成功。
user表
order表
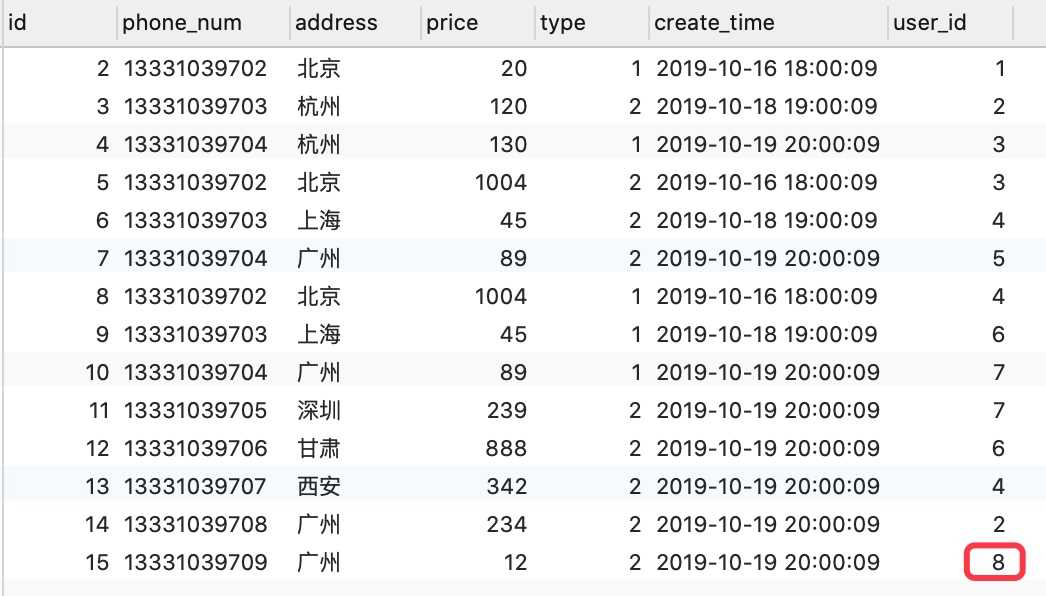
哪个表引用了其他表里的字段,就要给哪个表设置外键。
举例order表里的user_id字段是引用的user表里的id字段,所有需要给order表设置外键。
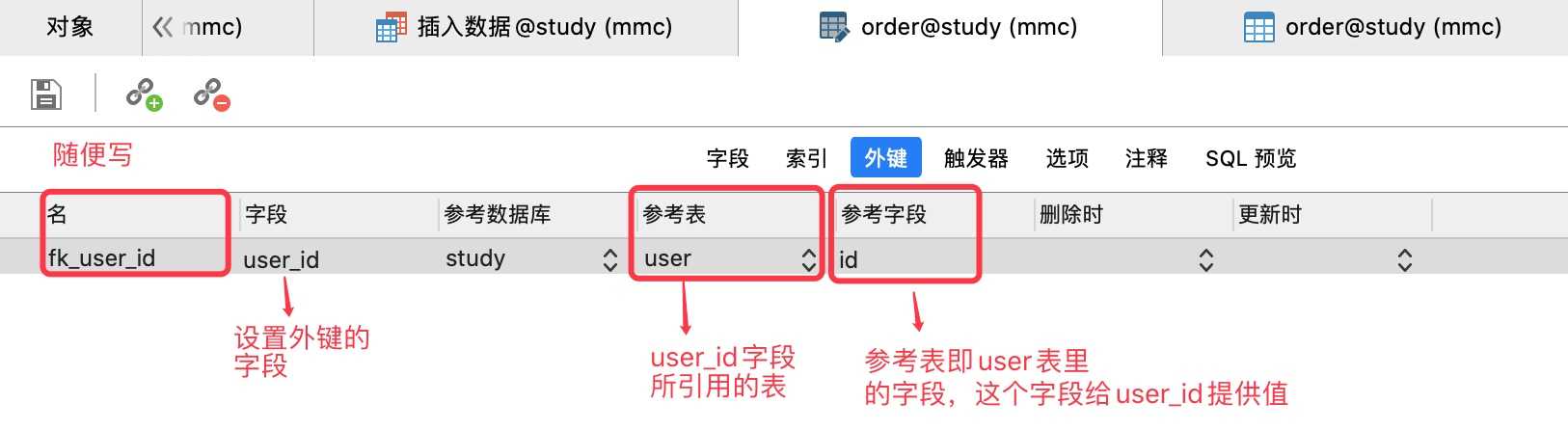
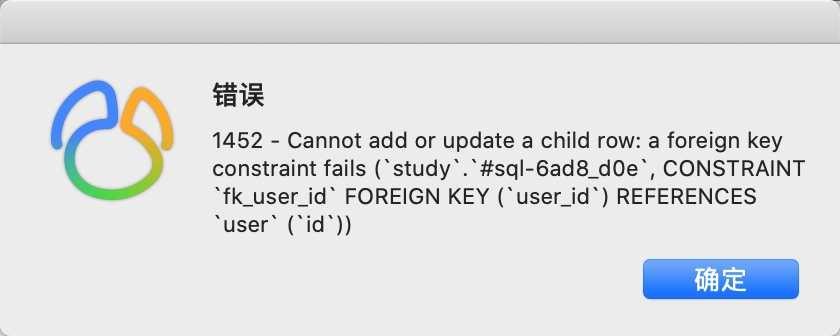
按照上面的设置保存的时候报下面的错误,这是因为在order表里有一个数据,它的user_id值是8,但是在user表里没有id为8的数据,所以会报错。
解决办法:在order表里删除这条数据再保存就可以了
CREATE TABLE `order` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`phone_num` varchar(11) DEFAULT NULL COMMENT ‘手机号‘,
`address` varchar(256) DEFAULT NULL COMMENT ‘地址‘,
`price` decimal(10,0) DEFAULT NULL COMMENT ‘订单价格‘,
`type` tinyint(2) DEFAULT NULL COMMENT ‘订单类型‘,
`create_time` datetime DEFAULT NULL COMMENT ‘创建时间‘,
`user_id` int(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_user_id` (`user_id`),
CONSTRAINT `fk_user_id` FOREIGN KEY (`user_id`) REFERENCES `user` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=16 DEFAULT CHARSET=utf8;
1.先在order表里插入一条数据,user_id在user表里不存在,会报下面的错误,数据不能插入
INSERT into `order` (user_id, address) VALUES (14, ‘上海‘);
错误提示
1452 - Cannot add or update a child row: a foreign key constraint fails (`study`.`order`, CONSTRAINT `fk_user_id` FOREIGN KEY (`user_id`) REFERENCES `user` (`id`)), Time: 0.036000s
2.在user表里删除一个在order表里有订单的用户,会删除失败,报下面的错误提示。
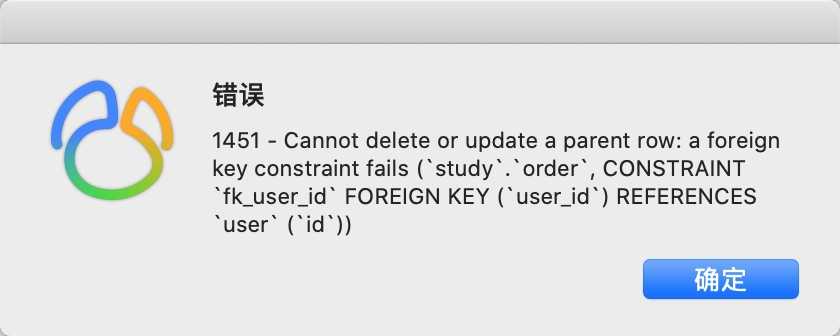
如果要删除这个用户,必须先从order表里把这个用户的订单数据删除掉才可以。
以某字段为条件,取左表和右表中同时存在相同数据的行,相当于两个表的交集
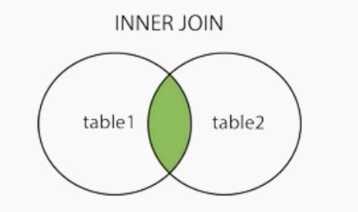
需求:查询一下order表里每个订单所属的用户信息
SELECT * FROM `order` INNER JOIN `user` ON order.user_id = user.id;
-- `order` o: 表示给order表取个别名为o
SELECT * FROM `order` o INNER JOIN `user` u ON o.user_id = u.id;
查询到的结果
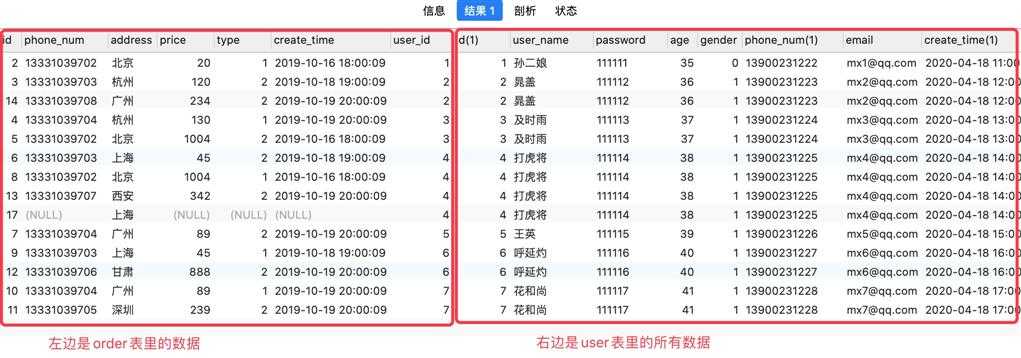
总结:
内连接会把两个表里都存在的数据查询出来,即取的两个表的交集数据。
以某字段为连接条件,取左表中的全部数据+右表与该字段对应的数据,可能会有某些数据在左表存在但是右表不存在的情况。
通俗理解就是:左连接是以左表为基础,左表表里符合条件的数据都展示,但是对应的行在右表的表里可能没有数据。
SELECT * FROM `order` o LEFT JOIN `user` u ON o.user_id = u.id;
以某字段为连接条件,取右表中的全部数据+左表与该字段对应的数据,可能会有某些数据在右表存在但是左表不存在的情况。
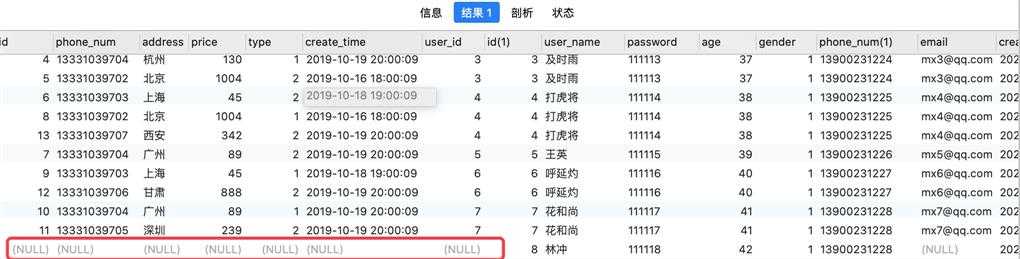
SELECT * FROM `order` o RIGHT JOIN `user` u ON o.user_id = u.id;
查询结果:
以右表为基础,左边的表里可能没有数据
多个select语句进行嵌套,嵌套的位置可以在select后,from后,where后。
需求:查询地址为北京的用户的邮箱
- 可以用上面的连接查询来实现
- 也可以通过嵌套查询来实现。先查出北京的用户的id,然后从用户表里查到邮箱
这里演示第二种方法
-- 放在where后
SELECT user_name,email FROM `user` WHERE id in (SELECT user_id FROM `order` WHERE address = ‘北京‘);
-- 放在from ,一定要起个别名,这里是m,否则会报错
SELECT m.address from (SELECT address,price FROM `order`) m;
-- 放在select后,(SELECT address from `order` WHERE user_id=1)查到的数据只能是一行,并且是一列
SELECT (SELECT address from `order` WHERE user_id=1), phone_num from `user`;
可以将多个select语句的结果合并为一个,合并后会删除重复的数据。
是可以把两个完全独立的表的查询的结果进行合并;而连接和嵌套则是对有关联的表进行查询和关联。
可以将多个select语句的结果合并为一个,合并后不会删除重复的数据
注意:union 和 union all 语句中,两个select查询的字段数量必须一样
-- 从user表里查询手机号
SELECT phone_num from user;
-- 从order表里查询手机号
SELECT phone_num from `order`;
-- 把上面两个表的查询结果合并然后去重
SELECT phone_num from user UNION SELECT phone_num from `order`;
-- 把两个表的查询结果合并但是不去重
SELECT phone_num from user UNION ALL SELECT phone_num from `order`;
练习:统计每个地区订单总金额占全国订单总金额的比例,按照倒序排列,取占比最高的前3位。
-- 分解:每个地区的总金额
SELECT address, SUM(price) as region_price from `order` GROUP BY address;
-- 分解:全国的总金额
SELECT SUM(price) as all_price FROM `order`;
-- 最终结果
SELECT
tmp.address,
tmp.region_price / tmp.all_price * 100 AS ratio
FROM
( SELECT address, SUM( price ) AS region_price, ( SELECT SUM( price ) FROM `order` ) AS all_price FROM `order` GROUP BY address ) tmp
ORDER BY
ratio DESC
LIMIT 3;
MySql表字段添加索引可以单独提高MySQL的查询速度。数据库就好像一本字典,那么索引就是字典的目录。一般会针对where条件后面的字段添加索引
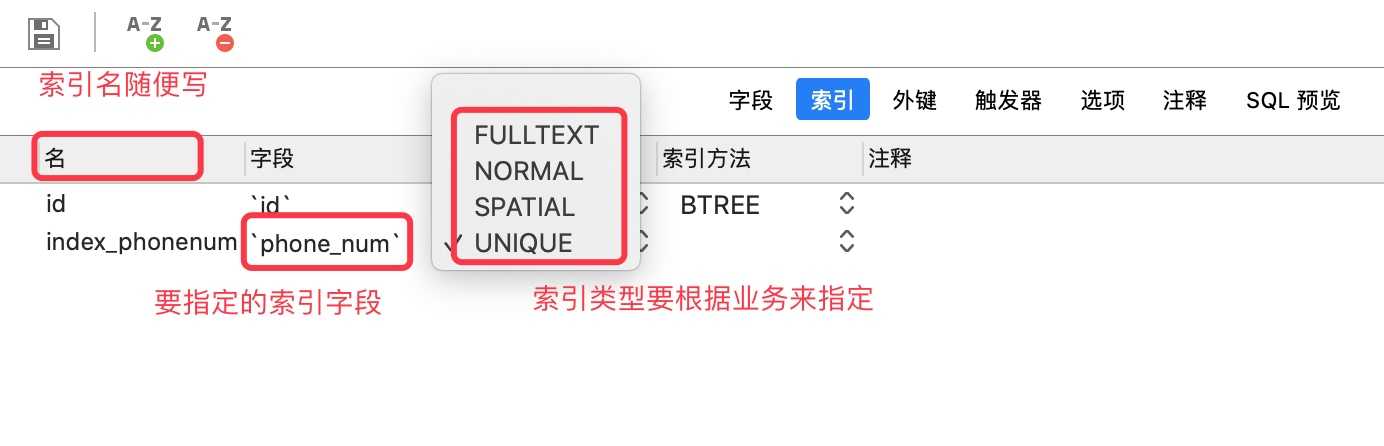
-- user:是表名
-- phone_num_index:是索引名称,随便起名字的
-- phone_num:索引字段
ALTER TABLE `user` ADD INDEX phone_num_index(phone_num);

ALTER TABLE `user` ADD UNIQUE INDEX phone_num_index(phone_num);

-- 根据索引名去删除索引的
DROP INDEX phone_num_index on `user`;
MySQL 可以通过 SQL语句快速复制表,并完成数据的复制。
主要是对表进行备份,复制出来的表可以进行数据测试,处理等,避免对原始表的污染
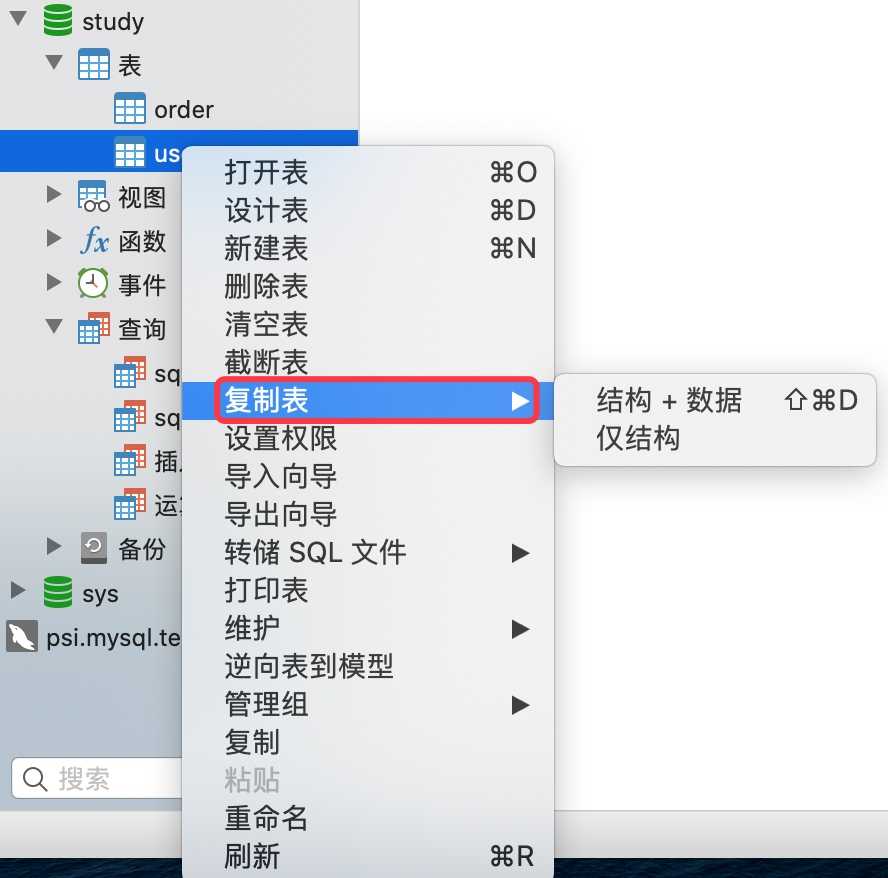
create table user_copy like user;
insert into user_copy select * from user;
1.concat()函数
作用:将两个或多个字符串组成或者拼接成一个字符串
-- 固定字符串拼接
SELECT CONCAT(‘test‘,2,‘ok‘);
-- 动态字符串拼接
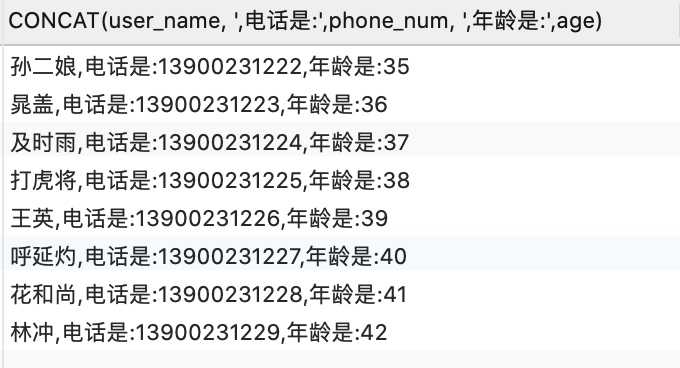
SELECT CONCAT(user_name, ‘,电话是:‘,phone_num, ‘,年龄是:‘,age) FROM `user`;
查询结果
2.length()函数
作用:获取字符串的长度
SELECT LENGTH(phone_num) FROM `user`;
3.replace()函数
作用:搜索并替换字符串中的子字符串
-- email 替换字段;mx 被替换内容; test 将mx替换成的内容
SELECT REPLACE(email, ‘mx‘,‘test‘) FROM `user`;
4.substring()函数
作用:从具有特定长度的位置开始提取一个子字符串
需求:获取每个用户手机号的后四位
-- phone_num 处理字段;从第8位开始 的 后 4位
SELECT SUBSTRING(phone_num,8,4) FROM `user`;
1.curdate()函数
作用:返回当前日期
SELECT CURRENT_DATE(); -- 结果: 2020-04-19
2.now()函数
作用:返回当前日期和时间
SELECT NOW(); -- 结果:2020-04-19 09:32:09
3.year()函数
作用:返回日期中的年份
SELECT YEAR(create_time) FROM `user`; -- 结果:2020
4.month()函数
作用:返回日期中的月份
SELECT MONTH(create_time) FROM `user` -- 结果:具体月份
5.day()函数
作用:返回日期中的天数
SELECT DAY(create_time) FROM `user`;
6.时分秒函数
SELECT HOUR(create_time) FROM `user`;
SELECT MINUTE(create_time) FROM `user`;
SELECT SECOND(create_time) FROM `user`;
1.rand()函数
作用:返回0~1之间随机小数
SELECT RAND(); -- 0.6606990561454548 每次运行都会变化
SELECT RAND() * 100; -- 66.43990561454548 每次运行都会变化
2.floor()函数
作用:小数取整
SELECT FLOOR(4.99834); -- 4
SELECT FLOOR(RAND() * 100); -- 0~100内的整数
SELECT FLOOR(10 + RAND() * 90); -- 10~100内的整数
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL语句集,它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象
总结:存储过程 = 逻辑 + SQL
while 条件 do
sql语句;
end while;
if 条件 then
sql语句;
else
sql语句;
end if;
需求:构造10000个测试账号。
思路: 注册的账号一般都是保存在数据库里的,所以可以直接在数据库写insert语句插入账号就行。 下面是一条单个数据,插入已经成功了,但是数据是写死的;所以需要通过上面的知识点综合运用,写一个存储过程,来动态生成每个字段对应的值,完成10000条数据的插入。
INSERT INTO `user` (user_name,`password`,age, gender,phone_num,email,create_time)
VALUES (‘白衣秀才‘, ‘123321‘, ‘36‘,‘1‘, ‘13200001000‘, ‘wanglun@163.com‘, NOW());
-- number 是参数,想造多少条数据通过number参数传进去就可以了
CREATE DEFINER=`root`@`%` PROCEDURE `createUsers`(number int)
BEGIN
-- 定义所需要的变量
DECLARE i INT(6) DEFAULT 0; -- 声明变量i,整型,长度为6,起始值为0
DECLARE u_name VARCHAR(10); -- 声明user_name变量,字符串类型,长度10
DECLARE u_age INT(4); -- 声明年龄变量
DECLARE u_gender INT(2); -- 声明年龄变量
DECLARE u_phone_num VARCHAR(11);
DECLARE u_email VARCHAR(20);
WHILE i<number DO
-- 如果i是偶数,性别设置为0;为奇数,就设置为1;这样能实现性别一半对一半
IF i%2=0 THEN
SET u_gender = 0;
ELSE
SET u_gender = 1;
END IF;
-- set 都是赋值操作
set u_name = CONCAT(‘test_‘,i); -- 拼接一个用户名
set u_age = FLOOR(RAND()*100); -- 随机数*100,再取整
SET u_phone_num = CONCAT(‘133310‘,i+10000);-- 构造手机号
SET u_email = CONCAT(u_name,‘@163.com‘);
INSERT INTO `user` (user_name,`password`,age, gender,phone_num,email,create_time)
VALUES (u_name, ‘123321‘, u_age, u_gender, u_phone_num, u_email, NOW());
SET i = i+1; -- 在存储过程里,所有赋值类操作,前面都必须加个set
END WHILE;
END
1.导出整个库
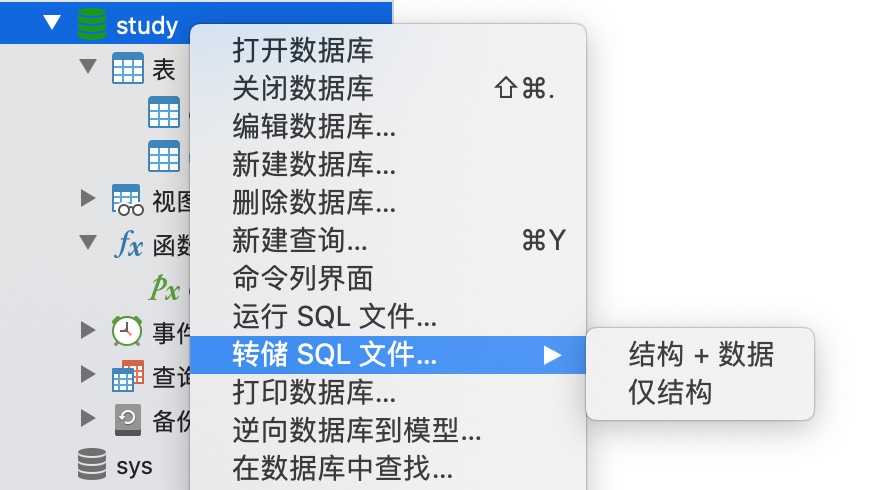
2.导出单张表
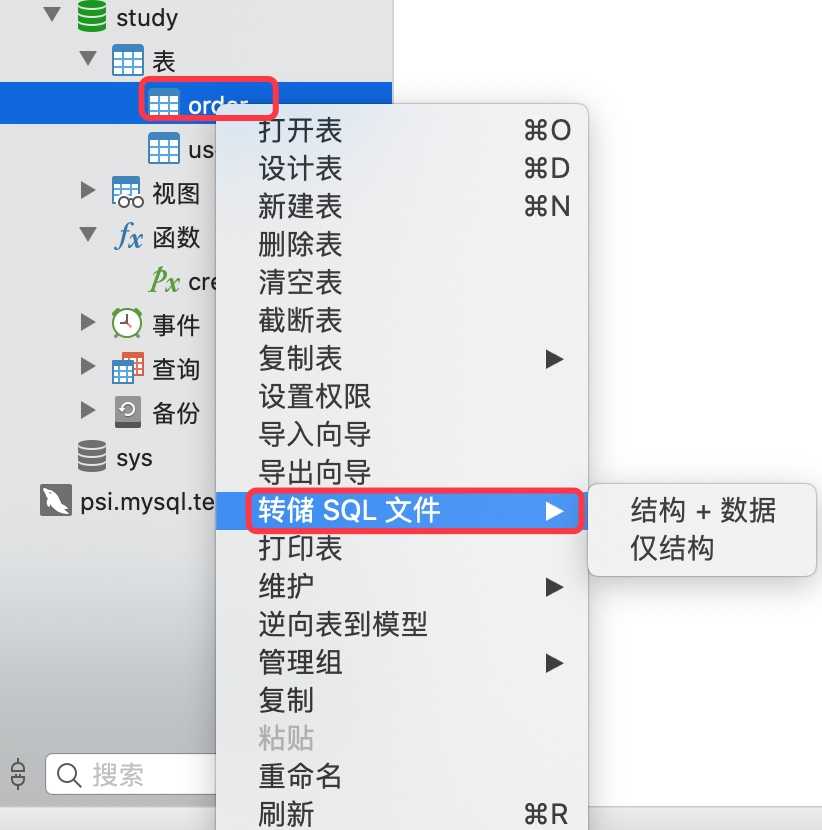
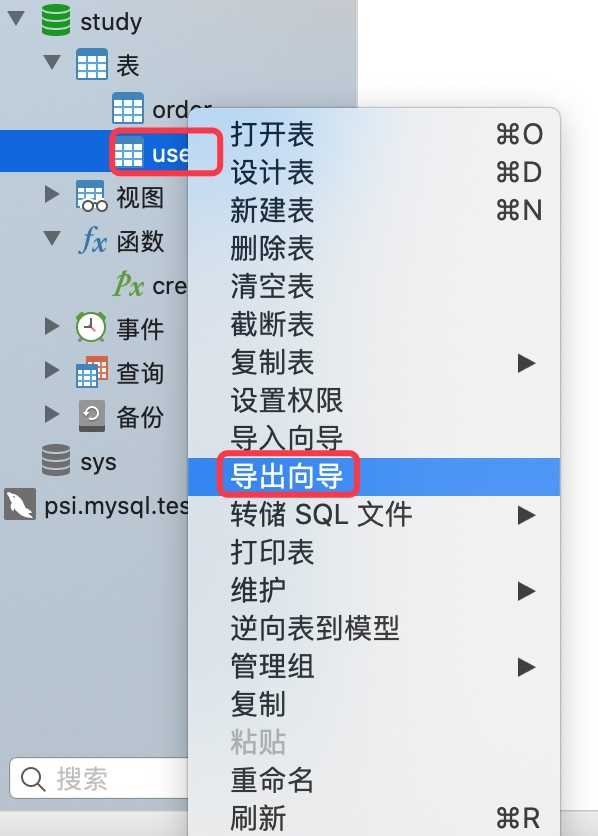
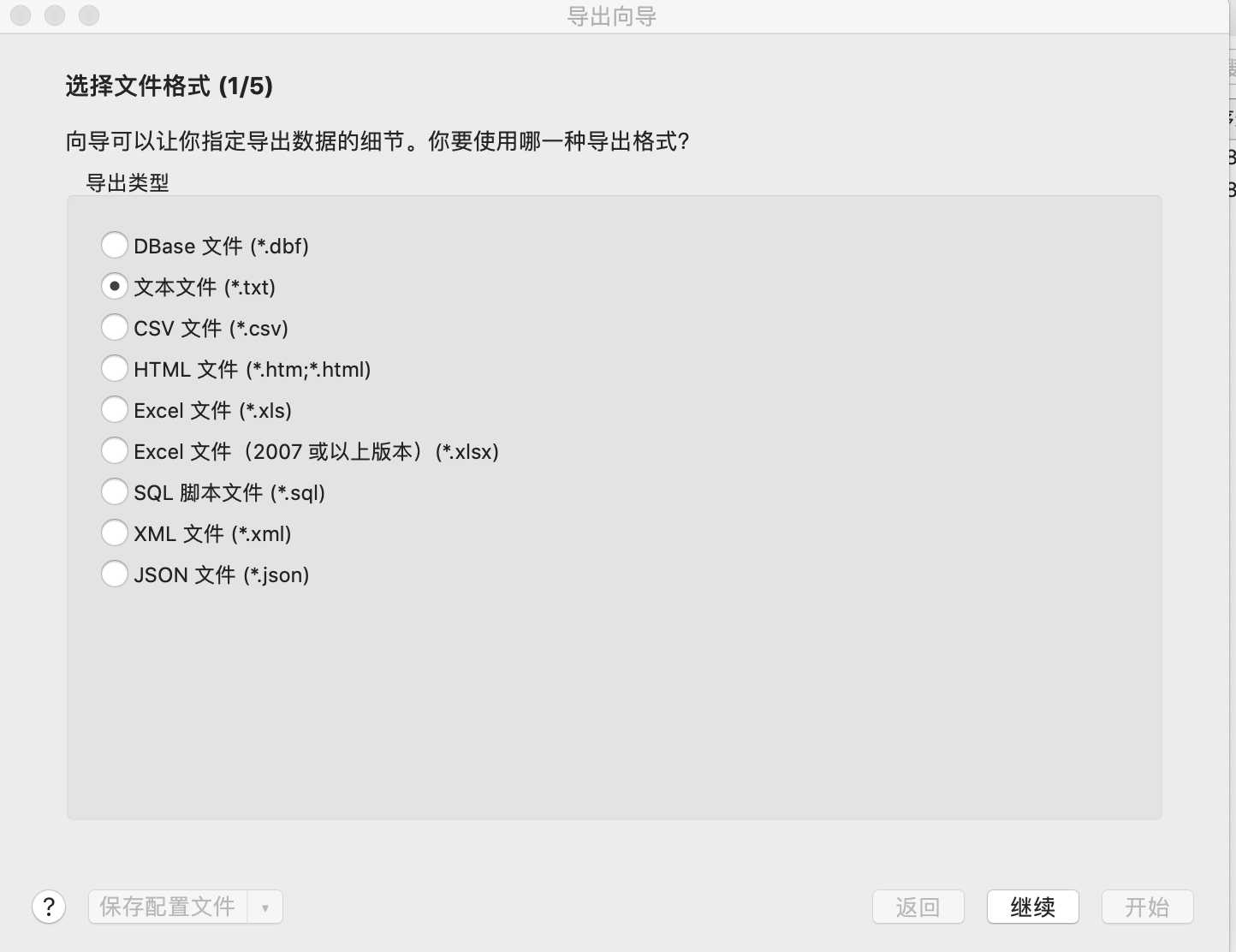
3.导出某些字段(导出向导)
按照下面的图示步骤即可完成
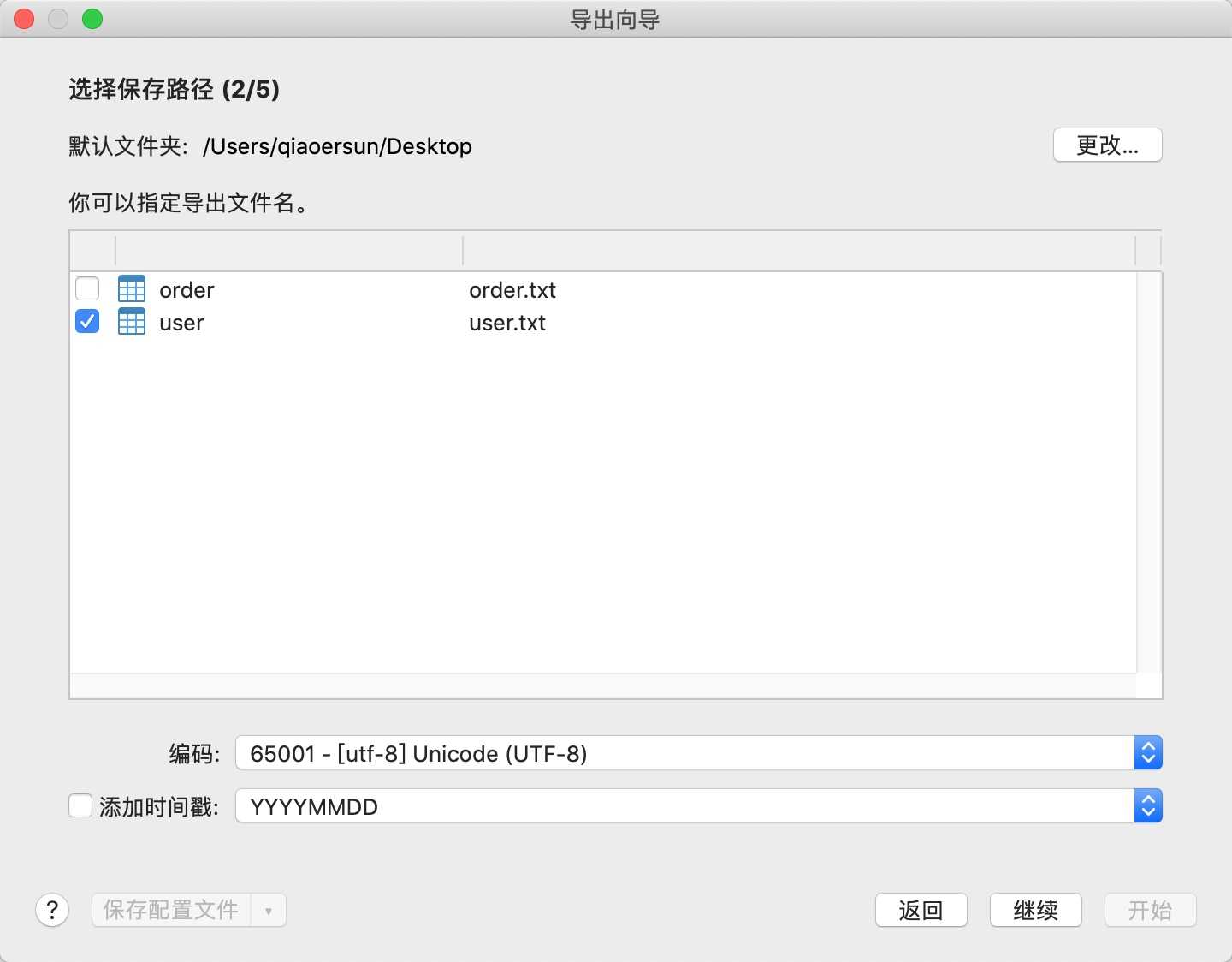
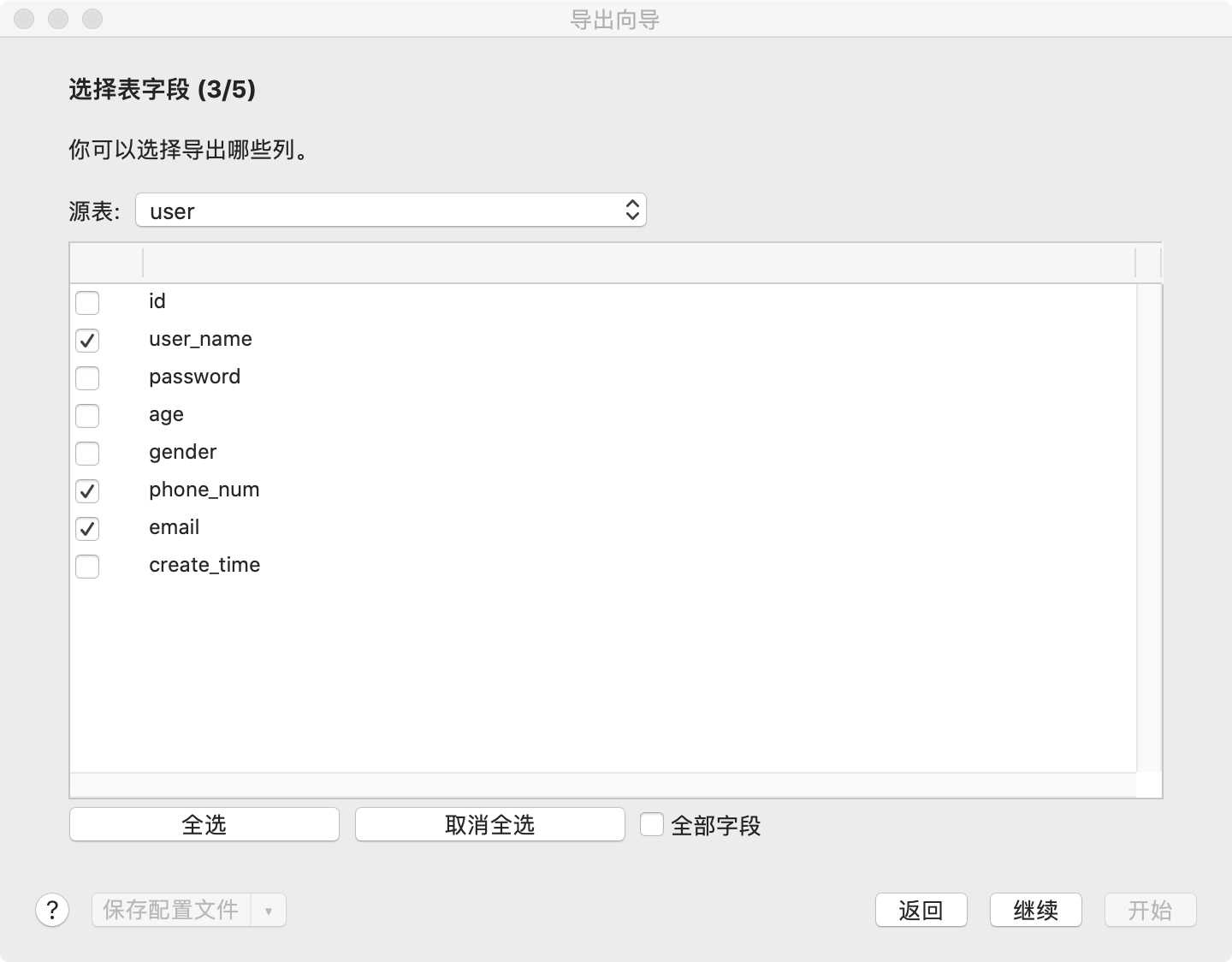
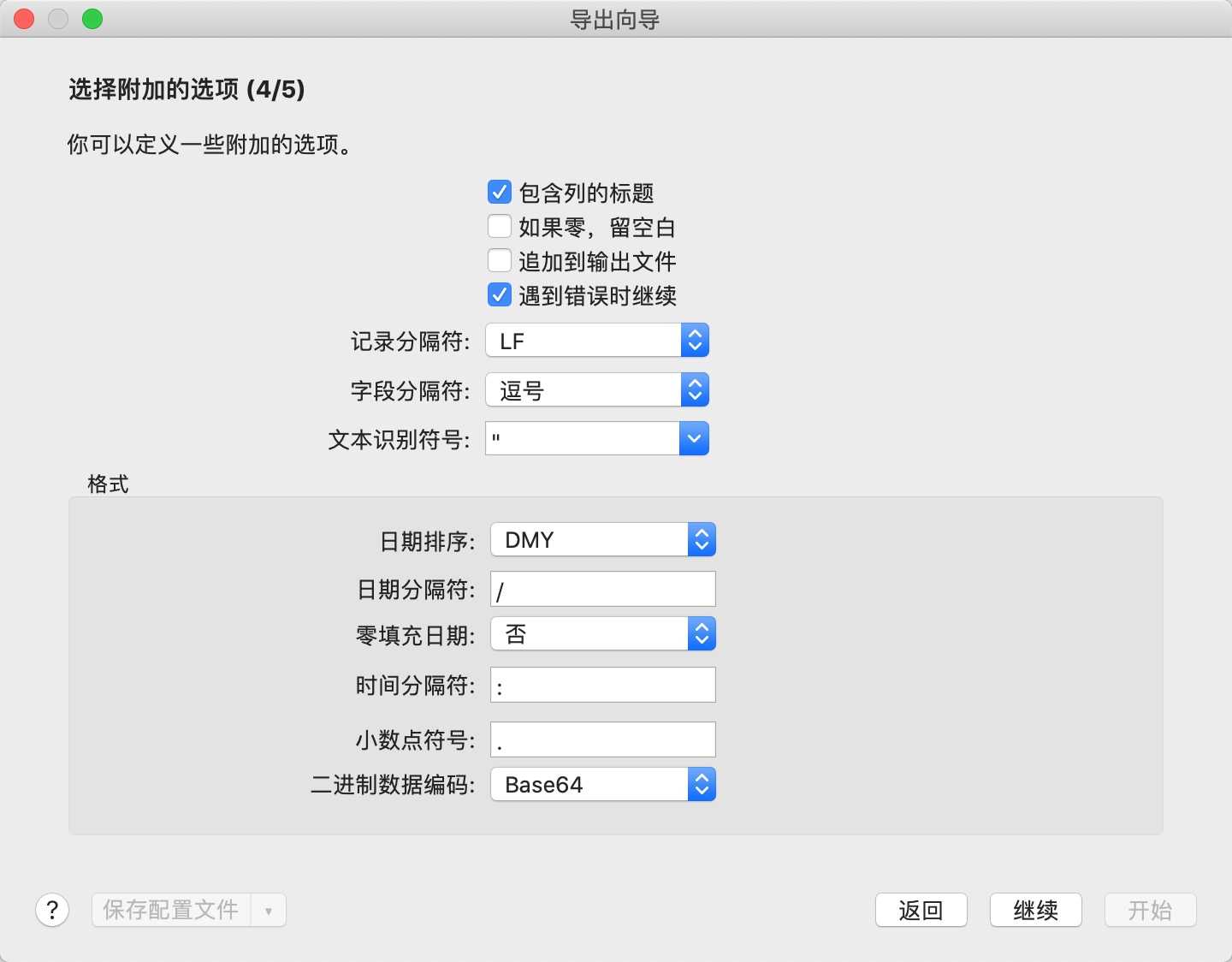
在数据库上右键-运行SQL文件, 选择导出的sql文件,然后按照提示即可
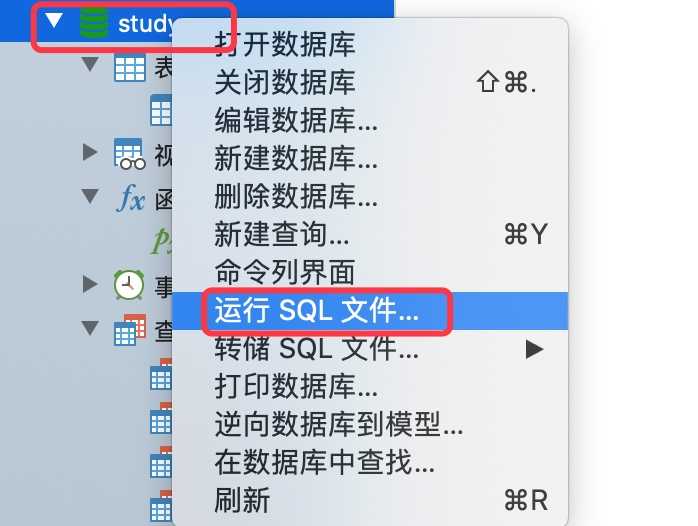
导出借助的是mysql提供的工具mysqldump,在mysql的bin目录下面,所以执行导出操作的时候要先进入到bin目录下面.
我用的是阿里云,所以先远程连接到阿里云,然后进入mysql的bin目录
cd /usr/bin
再执行导出命令,导出整个study库,导出到/usr/目录下面
-- 导出整个库
mysqldump -u root -p study > /usr/study.sql
-- 导出某张表,在库名study后空格,表名user
mysqldump -u root -p study user> /usr/user.sql
导入因为直接用的是命令,需要先把被导入文件user.sql复制到mysql的bin目录下面,然后登录进入mysql
mysql -u root -p -- 登录到数据库
use study; -- 切换到要导入表的库
source user.sql; -- 导入user表
标签:举例 报错 可视化 大型数据库 数字类型 第一个 key 目录 sel
原文地址:https://www.cnblogs.com/victorm/p/mysql-shu-ju-lei-xing.html