标签:读数 image and 代码 cut 页面 lru算法 测试 推断
在sqlserver中,几年之前就注意到一个现象:sqlserver中对一个大表创建索引或者rebuild索引的过程中,会引起内存剧烈的动荡,究其原因为何,这种现象到底正不正常,是不是sqlserver内存管理存在缺陷?
另外,最近刚好想到跟MySQL对比一下类似操作引起的内存变化,测试MySQL会不会有类似问题,这里就简单写个代码验证一下这个问题。
数据库是一个非常依赖内存资源的软件系统,通过缓存数据(索引)到内存中,来改善数据物理访问的性能问题,
但是内存往往又不是无限大,或者足以容纳所有相关数据的容量,因此就存在内存页面的淘汰问题。
内存页的淘汰算法,多数是遵循LRU算法,LRU是Least Recently Used的缩写,也即遵循“最近做少使用”的原则,选择最近最久未使用的页面予以淘汰。
这个算法表面上看起来没什么问题,如果有注意观察过在一台相对稳定的服务器上,给大表创建索引的过程,就会发现,整个过程中,buffer pool会发生剧烈的动荡,创建索引的表会迅速侵入内存,挤走内存中原本的缓存。
由于SQLServer作为商业数据库,有关于它的页面淘汰算法的研究较少,仅仅是指导一个大概是遵循LRU的原则的,但是有没有在LRU的基础上进行改进或者优化,就不得而知,
但是SQLServer究竟有没有对该问题做改进或者优化?这里从一个索引的创建来管中窥豹,从侧面验证一下这个算法。
这里需要借助SQLServer中的一个变量值:Page life expectancy,
相信稍微熟悉SQLServer一点的人应该都知道这个参数代表的意义:内存页面的平均滞留时间,如果内存页面不断地被置换出去,这个值将会维持不变或者变得更小,因为新载入内存的页面在内存中停留的时间是较短的。
不知道有没有人注意过,在一台内存相对稳定的服务器上,对大表(1000W+)创建索引的时候,Page life expectancy这个变量值会急转直下,这说明了什么?
大表创建索引粗略讲是读数据,然后写数据(索引树)的过程,这个过程中必然将相关的表读入内存,那么读入内存之后,他有没有淘汰内存中已有的数据?|
如果有,这明显是不合理的,创建索引只是创建索引,目的不是把内存中已有的热数据挤走,但是它还真的给内存中已有的热数据给挤走了。
反观MySQL(Innodb引擎),Redis等数据库,都是基于优化的LRU或者LFU的原则淘汰页面。
MySQL甚至可以人为地去调整这个LFU算法的一些参数值(innodb_old_blocks_pct,innodb_old_blocks_time),来达到优化内存淘汰的目的。
MySQL中虽然没有类似于PLE的参数,但是可以从其他参数来间接推断,如果发生同样的操作,相关的表会不会挤走内存中的热数据.
这里基于MySQL information_schema.innodb_buffer_pool_stats这张表来作分析,其中这个表有两个字段,pages_made_young, pages_not_made_young ,这两个的变化代表这个新进入内存中的页面冷热变化情况。
同样的道理,如果内存中充斥着大量的热点数据,在对一个大表创建索引的过程中,并不希望因为创建索引而把热点数据挤出内存,究竟是不是这样的,同样在创建索引的过程中,观察一下这两个值的变化情况就可以了。
测试方法
这里通过循环,以5秒为间隔,连续输出sqlserver中的Page life expectancy这个变量的值,以及MySQL中的pages_made_young和pages_not_made_young。
#coding=utf-8 import threading import pymssql import pymysql from time import ctime,sleep import datetime import time mssql_conn_conf = {‘host‘: ‘***.***.***.***‘, ‘port‘: 1433, ‘db‘: ‘master‘} mysql_conn_conf = {‘host‘: ‘***.***.***.***‘, ‘port‘: 3306, ‘user‘: ‘root‘, ‘password‘: ‘***‘, ‘db‘: ‘information_schema‘} def mssql_ple(): conn = pymssql.connect(host=mssql_conn_conf[‘host‘], port=mssql_conn_conf[‘port‘], database=mssql_conn_conf[‘db‘]) cursor = conn.cursor() try: cursor.execute(" select cntr_value from sys.dm_os_performance_counters where object_name = ‘MSSQL$SQL2014:Buffer Manager‘ and counter_name = ‘Page life expectancy‘ ") row = cursor.fetchone() print(datetime.datetime.now().strftime(‘%Y-%m-%d %H:%M:%S‘)+ ‘------>‘+str(row[0])) except pymssql.Error as e: print("mysql execute error:", e) cursor.close() conn.close() def mysql_memory(): conn = pymysql.connect(host=mysql_conn_conf[‘host‘], port=mysql_conn_conf[‘port‘], database=mysql_conn_conf[‘db‘],user=mysql_conn_conf[‘user‘],password = mysql_conn_conf[‘password‘]) cursor = conn.cursor() try: cursor.execute(‘‘‘ SELECT SUM(pages_made_young) AS total_pages_made_young, SUM(pages_not_made_young) AS total_pages_not_made_young FROM ( SELECT pages_made_young, pages_not_made_young FROM information_schema.innodb_buffer_pool_stats )t; ‘‘‘) row = cursor.fetchone() print(datetime.datetime.now().strftime(‘%Y-%m-%d %H:%M:%S‘)+ ‘------>‘+‘made_young:‘+str(row[0])+‘ not_made_young:‘+str(row[1])) except pymssql.Error as e: print("mysql execute error:", e) cursor.close() conn.close() if __name__ == ‘__main__‘: while 1>0: mysql_memory() time.sleep(5)
SQLServer中的PLE变化测试
其实很容易观察,对于一台没有负载的服务器,因为没有新的内存页面载入内存,它的Page life expectancy值是递增的的,这个变量的单位是秒,间隔一秒,这个值会自动加1。
一旦有新的页面载入内存,如果内存已经被用完,随着内存中已有的页面淘汰出去,这个值是会自动递减的,或者出现断崖式的下降。
这里运行上述脚本,打印出来当前服务器的Page life expectancy值,稍等一段时间后,在某个大表上创建出一个索引,再观察这个值的变化情况,
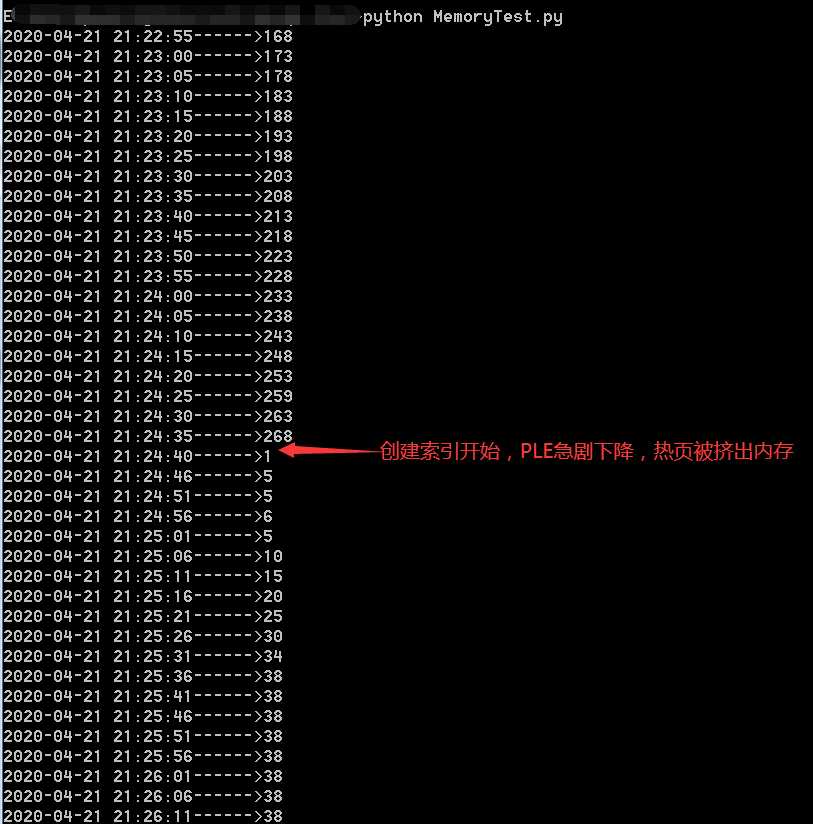
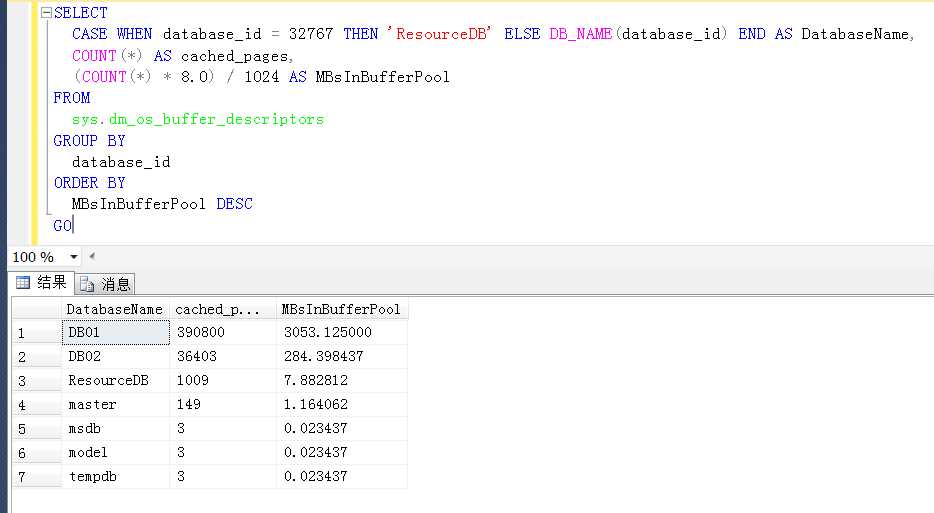
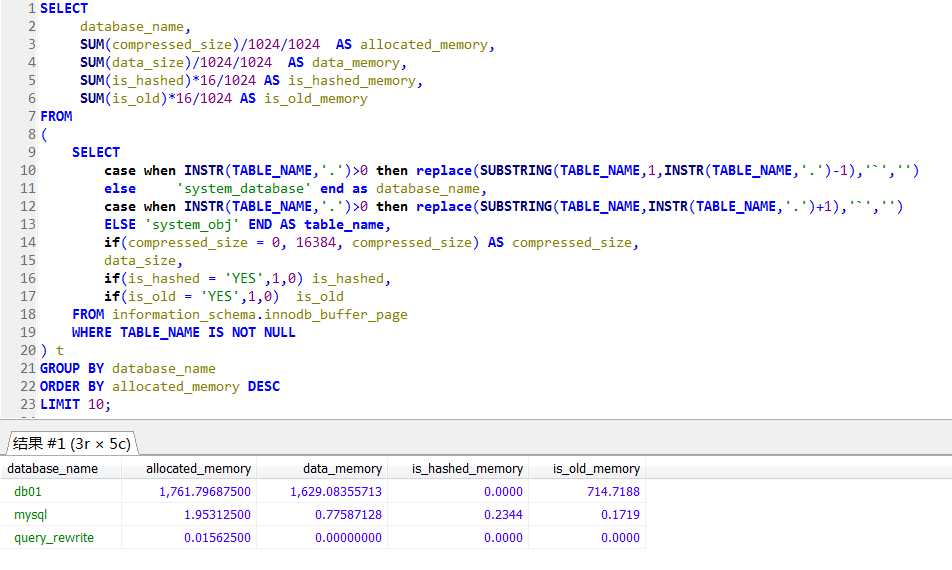
step1,对DB01库上的表进行反复的查询,使其载入内存(最近较多使用),左图是DB01库占用的内存情况,
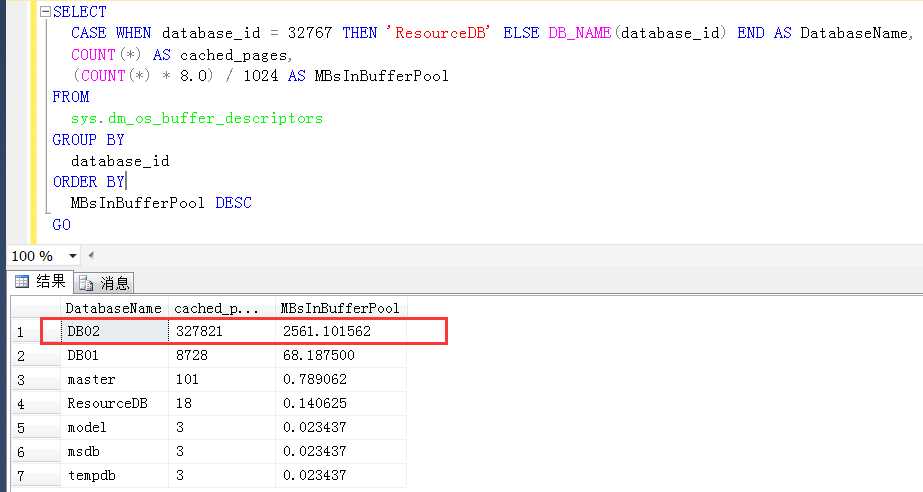
step2,在DB02库上对一张大表创建索引,此过程中中会发现创建索引的表会迅速将已换成的数据挤出内存
MySQL中的pages_made_young和page_not_made_young测试
因笔者事前重启过实例,因此made_young的值很小,关键要看,在某个大表上创建索引的过程中是不是会大量的made_young就行了。
这里可以看到,在创建索引开始之后,会出现大量的not_made_young,实际上这种效果是预期的,仅仅是创建索引,而不是顺带让当前这个大表的数据挤走热点数据(并没有大批量的made_young)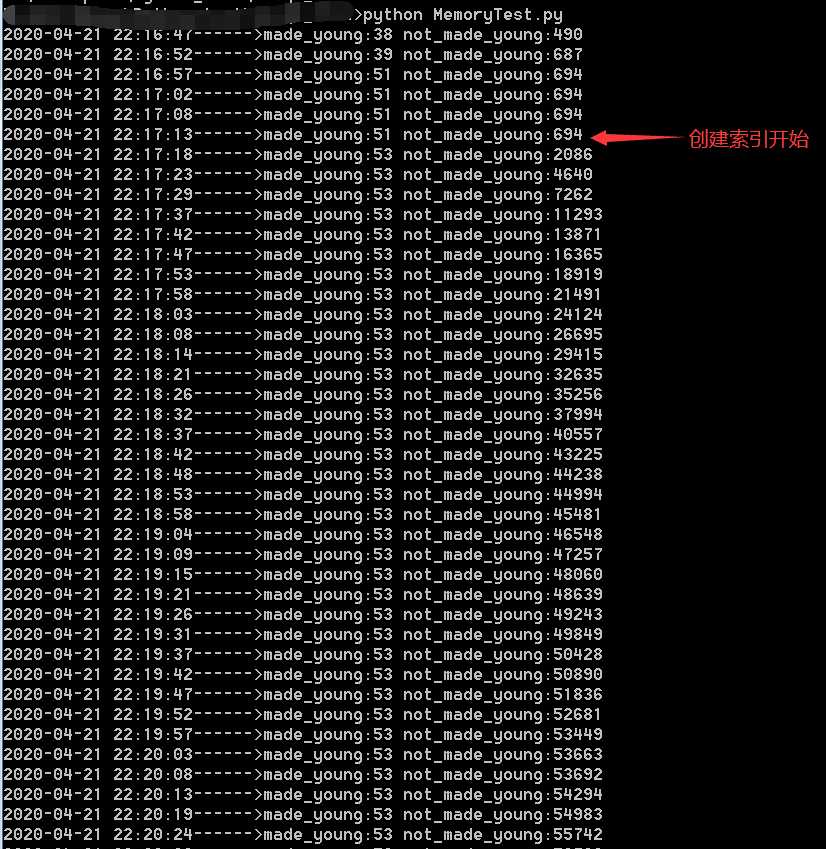
这里也给出在db02上创建索引前后两个库占用的内存情况,虽然db02在其某个大表上创建索引之后占用了一定量的内存,但是这部分内存并非热数据,是随时可以被挤出buffer pool的,因为他们没有page_made_young
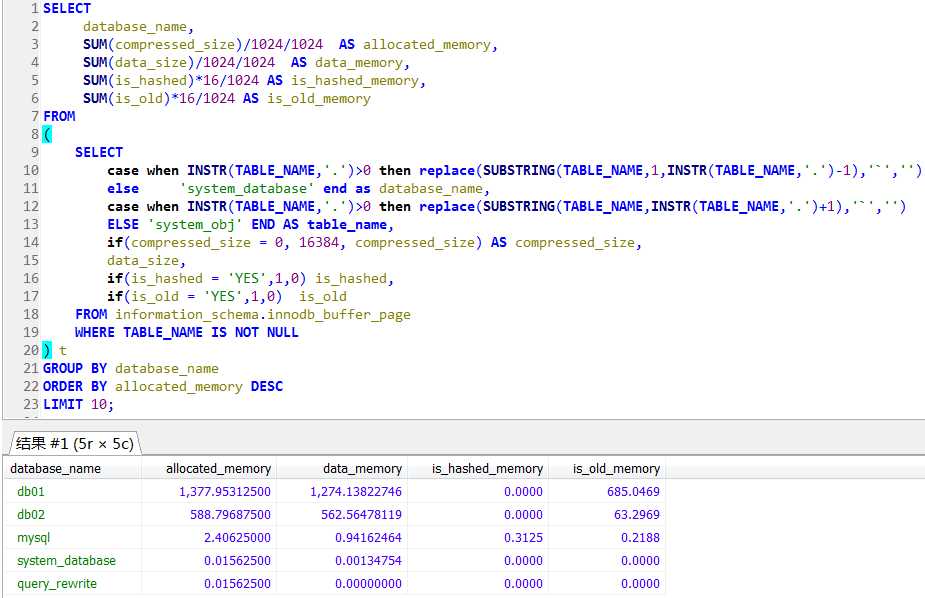
step1,对db01库上的表进行的多次查询,使其载入内存,左图是db01库占用的内存情况,
step2,在db02库上对一张大表创建索引,此过程中中会发现不断地有大量的page_not_made_young,另外原本的db01库的内存并没有被大量的挤出。
总结
以个人浅薄的经历以及测试过程,发现sqlserver的内存管理,与MySQL相比,这一点做的确实不到位,与MySQL相比,其buffer pool管理本身的算法就存在问题,又是一个黑盒,也没有人为可以调整的可能性。
sqlserver再不加油,真的就没人用了……
从创建索引过程中内存变化来看SQL Server与MySQL的内存淘汰算法
标签:读数 image and 代码 cut 页面 lru算法 测试 推断
原文地址:https://www.cnblogs.com/wy123/p/12729298.html