标签:while 失误 key alt for 数据 prefix http tail
最近在做将kafka里面的业务日志写入到hbase 当中,然后要对hbase 里面的数据进行解析然后插入到数据库当中。
为了能节约磁盘空间想对hbase里面的数据进行删除,但是我们设置的rowkey是按照每小时 加日期 然后加hash码的方式组成的。例子如下:
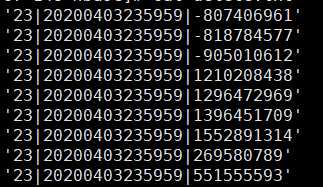
这个地方我们没有办法通过框定一个时间范围对这个rowkey 进行删除。所以我想了一个办法。
(1)我们可以从外面传入2个参数 一个是起始日期 ,一个是结束日期,然后把里面的每个小时的rowkey通过rowkey 前缀过滤的形式将数据拿出来 然后塞入到一个文件当中
然后最后对这个文件进行批量删除。我的脚本如下:
#!/bin/bash tablename=$1 startrow=$2 endrow=$3 if [ $# -eq 0 ];then echo "请输入表名,startRow,endRow,日期的格式如下2017-04-04" exit 0 fi beg_s=`date -d "$startrow" +%s` end_s=`date -d "$endrow" +%s` rowkey="" while [ "$beg_s" -le "$end_s" ];do day=`date -d @$beg_s +"%Y%m%d"`; echo "当前日期:$day" for((i=0;i<24;i++)) do if [ ${#i} -eq 1 ];then rowkey="0"$i"|"$day echo $rowkey echo "scan ‘${tablename}‘,{ROWPREFIXFILTER => ‘${rowkey}‘}" |hbase shell|awk -F ‘ ‘ ‘{print $1‘\t‘}‘> ./file.txt #删除前6行非表中数据 sed -i ‘1,6d‘ file.txt #删除最后一行(空行) sed -i ‘$d‘ file.txt #删除最后一行(总条数) sed -i ‘$d‘ file.txt cat ./file.txt|awk ‘{print $1}‘|while read rowvalue do echo -e "deleteall ‘${tablename}‘,‘${rowvalue}‘" >> ./deleteRowFile.txt done rm ./file.txt else rowkey=$i"|"$day echo $rowkey echo "scan ‘${tablename}‘,{ROWPREFIXFILTER => ‘${rowkey}‘}" |hbase shell|awk -F ‘ ‘ ‘{print $1‘\t‘}‘> ./file.txt #删除前6行非表中数据 sed -i ‘1,6d‘ file.txt #删除最后一行(空行) sed -i ‘$d‘ file.txt #删除最后一行(总条数) sed -i ‘$d‘ file.txt cat ./file.txt|awk ‘{print $1}‘|while read rowvalue do echo -e "deleteall ‘${tablename}‘,‘${rowvalue}‘" >> ./deleteRowFile.txt done rm ./file.txt fi done beg_s=$((beg_s+86400)); done echo "exit" >> ./deleteRowFile.txt
#为避免线上执行失误 ,先检查deleteRowFile.txt中要删除的rowkey是否正确,所以以下两行命令请手动执行
#hbase shell ./deleteRowFile.txt
#rm ./deleteRowFile.txt
这里需要传入3个参数 分别是hbase 的表名称,然后起始时间,结束时间就可以将数据塞入到一个文件当中 最后塞入文件的形式如下
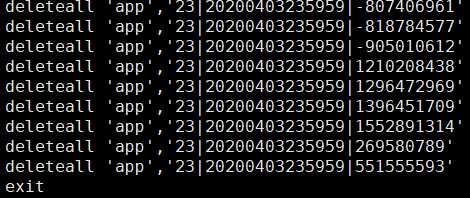
为了防止数据删除错误,我们先检查 一下删除的是否正确,然后执行
hbase shell ./deleteRowFile.txt
最后将这个文件删除掉。
借鉴博客:https://blog.csdn.net/nyistzp/article/details/76922512?utm_source=blogkpcl9
shell脚本删除hbase里面的数据(按照rowkey批量删除hbase的数据)
标签:while 失误 key alt for 数据 prefix http tail
原文地址:https://www.cnblogs.com/gxgd/p/12752678.html