标签:cte 完全 png roots roo ted header 表示 种类型
原文链接:http://tecdat.cn/?p=12272
使用ARIMA模型,您可以使用序列过去的值预测时间序列。在本文中,我们从头开始构建了一个最佳ARIMA模型,并将其扩展到Seasonal ARIMA(SARIMA)和SARIMAX模型。
时间序列是在定期的时间间隔内记录度量的序列。
根据频率,时间序列可以是每年(例如:年度预算),每季度(例如:支出),每周(例如:销售数量),每天(例如天气),每小时(例如:股票价格),分钟(例如:来电提示中的呼入电话),甚至是几秒钟(例如:网络流量)。
因为预测时间序列(如需求和销售)通常具有巨大的商业价值。
在大多数制造公司中,它驱动基本的业务计划,采购和生产活动。预测中的任何错误都会在整个供应链或与此相关的任何业务环境中蔓延。因此,准确地进行预测很重要,以节省成本,这对于成功至关重要。
不仅在制造业中,时间序列预测背后的技术和概念还适用于任何业务。
现在,预测时间序列可以大致分为两种类型。
如果仅使用时间序列的先前值来预测其未来值,则称为 单变量时间序列预测。
如果您使用序列以外的其他预测变量(也称为外生变量)进行预测,则称为 多变量时间序列预测。
这篇文章重点介绍一种称为ARIMA 建模的特殊类型的预测方法 。
ARIMA是一种预测算法,其基于以下思想:时间序列的过去值中的信息可以单独用于预测未来值。
那么ARIMA模型到底是什么?
ARIMA是一类模型,可以根据自身的过去值(即自身的滞后和滞后的预测误差)“解释”给定的时间序列,因此可以使用方程式预测未来价值。
任何具有模式且不是随机白噪声的“非季节性”时间序列都可以使用ARIMA模型进行建模。
ARIMA模型的特征在于3个项:p,d,q
p是AR项
q是MA项
d是使时间序列平稳所需的差分数
如果时间序列具有季节性模式,则需要添加季节性条件,该时间序列将变成SARIMA(“季节性ARIMA”的缩写)。一旦完成ARIMA。
那么,“AR项的顺序”到底意味着什么?在我们去那里之前,我们先来看一下“ d”。
建立ARIMA模型的第一步是 使时间序列平稳。
为什么?
因为ARIMA中的“自动回归”一词意味着它是一个 线性回归模型 ,使用自己的滞后作为预测因子。如您所知,线性回归模型在预测变量不相关且彼此独立时最有效。
那么如何使一序列稳定呢?
最常见的方法是加以差分。即,从当前值中减去先前的值。
因此,d的值是使序列平稳所需的最小差分数。如果时间序列已经固定,则d = 0。
接下来,什么是“ p”和“ q”?
“ p”是“自回归”(AR)术语的顺序。它指的是要用作预测变量的Y的滞后次数。而“ q”是“移动平均”(MA)项的顺序。它是指应输入ARIMA模型的滞后预测误差的数量。
那么什么是AR和MA模型?AR和MA模型的实际数学公式是什么?
仅AR模型是Yt仅取决于其自身滞后的模型。也就是说,Yt是“ Yt滞后”的函数。
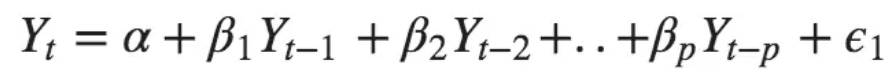
![]() ?
?
同样,纯 移动平均线(仅MA)模型 是Yt仅取决于滞后预测误差的模型。
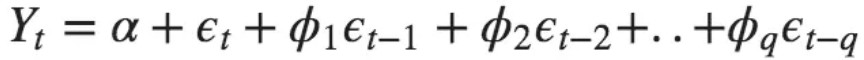
![]() ?
?
误差项是各个滞后的自回归模型的误差。误差Et和E(t-1)是来自以下方程式的误差:
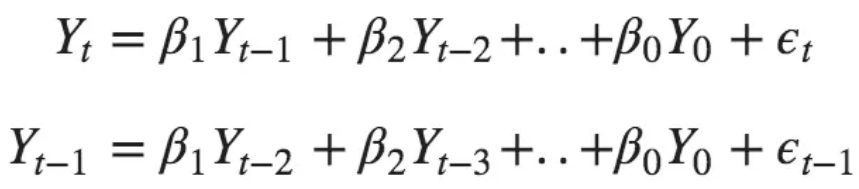
![]() ?
?
那分别是AR和MA模型。
那么ARIMA模型的方程是什么样的呢?
ARIMA模型是这样的模型,其中时间序列至少差分一次以使其稳定,然后将AR和MA项组合在一起。因此,等式变为:
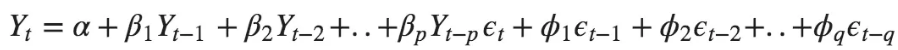
![]() ?
?
因此,目的是识别p,d和q的值。
进行差分的目的是使时间序列平稳。
但是您需要注意不要使系列过分差分。因为,超差分序列可能仍然是静止的,这反过来将影响模型参数。
那么如何确定正确的差分顺序呢?
正确的差分顺序是获得近似平稳序列的最小差分,该序列围绕定义的平均值漫游,并且ACF曲线相当快地达到零。
如果自相关对于许多之后(10个或更多)为正,则该序列需要进一步求差。
在这种情况下,你不能真正确定两个差分阶数之间的差,然后选择在差分序列中给出最小标准偏差的阶次。
让我们来看一个例子。
首先,我将使用adfuller()statsmodels包中的Augmented Dickey Fuller测试()检查该系列是否稳定。
为什么?
因为,仅当序列非平稳时才需要进行区分。否则,不需要差分,即d = 0。
ADF检验的零假设是时间序列是非平稳的。因此,如果检验的p值小于显着性水平(0.05),则拒绝原假设,并推断时间序列确实是平稳的。
因此,在我们的情况下,如果P值> 0.05,我们将继续寻找差分的顺序。
from statsmodels.tsa.stattools import adfuller
from numpy import log
result = adfuller(df.value.dropna())
print(‘ADF Statistic: %f‘ % result[0])
print(‘p-value: %f‘ % result[1])ADF Statistic: -2.464240
p-value: 0.124419由于P值大于显着性水平,因此让我们对序列进行差分,看看自相关图的样子。
import numpy as np, pandas as pd
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import matplotlib.pyplot as plt
plt.rcParams.update({‘figure.figsize‘:(9,7), ‘figure.dpi‘:120})
# Import data
df = pd.read_csv(‘wwwusage.csv‘, names=[‘value‘], header=0)
# Original Series
fig, axes = plt.subplots(3, 2, sharex=True)
axes[0, 0].plot(df.value); axes[0, 0].set_title(‘Original Series‘)
plot_acf(df.value, ax=axes[0, 1])
# 1st Differencing
axes[1, 0].plot(df.value.diff()); axes[1, 0].set_title(‘1st Order Differencing‘)
plot_acf(df.value.diff().dropna(), ax=axes[1, 1])
# 2nd Differencing
axes[2, 0].plot(df.value.diff().diff()); axes[2, 0].set_title(‘2nd Order Differencing‘)
plot_acf(df.value.diff().diff().dropna(), ax=axes[2, 1])
plt.show()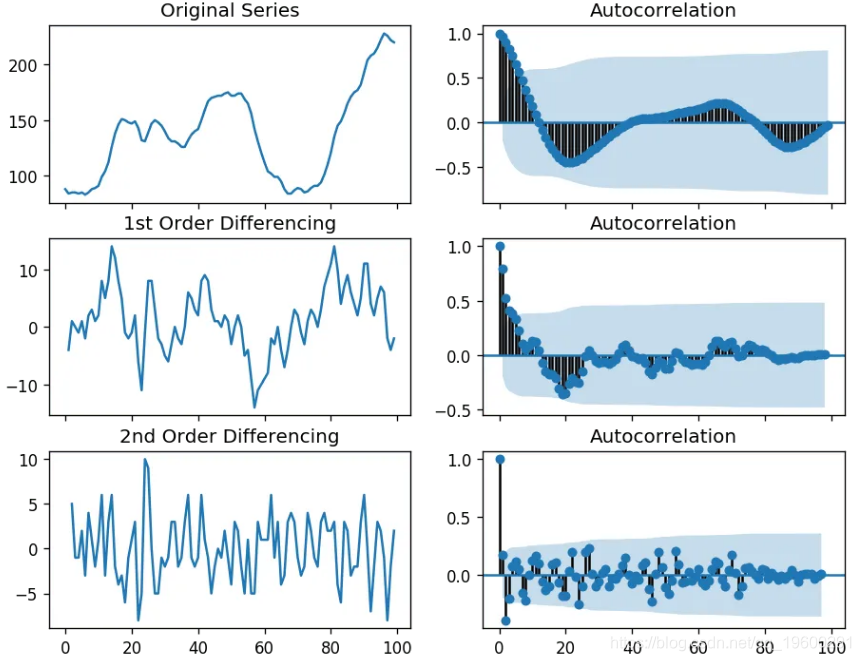
![]() ?
?
对于以上序列,时间序列达到平稳,具有两个不同的阶数。但是,在查看第二次差分的自相关图时,滞后会很快进入负值区域,这表明该序列可能已经过差分。
因此,即使该序列不是完全平稳的(平稳性较弱),我也将暂时将差分的阶数固定为1。
## Adf Test
ndiffs(y, test=‘adf‘) # 2
# KPSS test
ndiffs(y, test=‘kpss‘) # 0
# PP test:
ndiffs(y, test=‘pp‘) # 22 0 2下一步是确定模型是否需要任何AR条款。您可以通过检查偏自相关(PACF)图来找出所需的AR项数。
排除部分滞后的影响后,可以将部分自相关想象为序列与其滞后之间的相关性。因此,PACF的传递传达了滞后与序列之间的纯相关性。这样,您将知道在AR术语中是否需要该滞后。
如何找到AR项的阶数?
平稳序列中的任何自相关都可以通过添加足够的AR项进行校正。因此,我们最初将AR项的阶数等于跨过PACF图中显着性区间的滞后阶数。
# PACF plot of 1st differenced series
plt.show()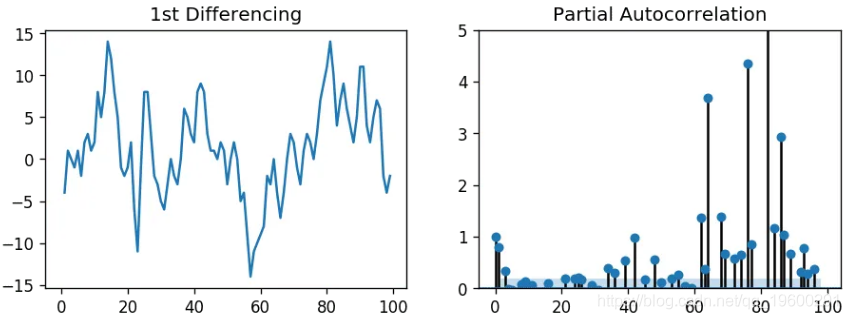
![]() ?
?
AR阶数
可以观察到,PACF滞后1非常重要,因为它远高于显着性线。滞后2事实也很重要,稍微超过了显着性区间(蓝色区域)。
就像我们在PACF图上查看AR项的阶数一样,您也可以在ACF图上查看MA项的阶数。MA从技术上讲是滞后预测的误差。
ACF指示要删除平稳序列中的任何自相关需要多少个MA项。
让我们看一下差分序列的自相关图。
fig, axes = plt.subplots(1, 2, sharex=True)
axes[0].plot(df.value.diff()); axes[0].set_title(‘1st Differencing‘)
axes[1].set(ylim=(0,1.2))
plot_acf(df.value.diff().dropna(), ax=axes[1])
plt.show()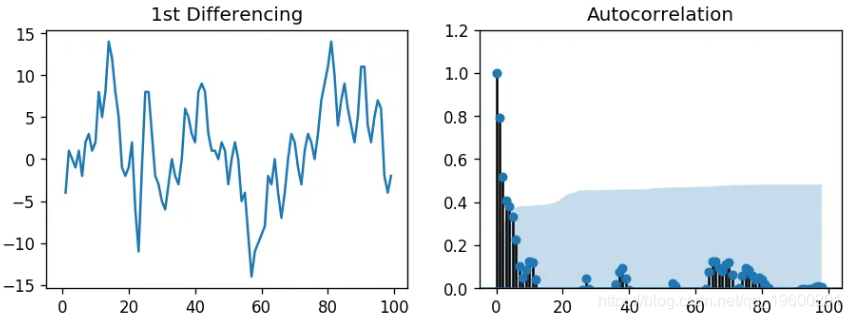
![]() ?
?
MA阶数
几个滞后远高于界限。因此,让我们暂时将q固定为2。
该如何处理?
如果您的系列有少许差异,通常添加一个或多个其他AR即可。同样,如果略有差异,请尝试添加其他MA项。
现在,已经确定了p,d和q的值,已经具备了拟合ARIMA模型的所有条件。
ARIMA Model Results
==============================================================================
Dep. Variable: D.value No. Observations: 99
Model: ARIMA(1, 1, 2) Log Likelihood -253.790
Method: css-mle S.D. of innovations 3.119
Date: Wed, 06 Feb 2019 AIC 517.579
Time: 23:32:56 BIC 530.555
Sample: 1 HQIC 522.829
=================================================================================
coef std err z P>|z| [0.025 0.975]
---------------------------------------------------------------------------------
const 1.1202 1.290 0.868 0.387 -1.409 3.649
ar.L1.D.value 0.6351 0.257 2.469 0.015 0.131 1.139
ma.L1.D.value 0.5287 0.355 1.489 0.140 -0.167 1.224
ma.L2.D.value -0.0010 0.321 -0.003 0.998 -0.631 0.629
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.5746 +0.0000j 1.5746 0.0000
MA.1 -1.8850 +0.0000j 1.8850 0.5000
MA.2 545.3515 +0.0000j 545.3515 0.0000
-----------------------------------------------------------------------------该模型摘要揭示了很多信息。中间的表是系数表,其中“ coef”下的值是相应项的权重。
请注意,这里的MA2项的系数接近零 。理想情况下,各个X的值应小于0.05。
因此,让我们在没有MA2术语的情况下重建模型。
ARIMA Model Results
==============================================================================
Dep. Variable: D.value No. Observations: 99
Model: ARIMA(1, 1, 1) Log Likelihood -253.790
Method: css-mle S.D. of innovations 3.119
Date: Sat, 09 Feb 2019 AIC 515.579
Time: 12:16:06 BIC 525.960
Sample: 1 HQIC 519.779
=================================================================================
coef std err z P>|z| [0.025 0.975]
---------------------------------------------------------------------------------
const 1.1205 1.286 0.871 0.386 -1.400 3.641
ar.L1.D.value 0.6344 0.087 7.317 0.000 0.464 0.804
ma.L1.D.value 0.5297 0.089 5.932 0.000 0.355 0.705
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.5764 +0.0000j 1.5764 0.0000
MA.1 -1.8879 +0.0000j 1.8879 0.5000
-----------------------------------------------------------------------------AIC模型已减少,这很好。AR1和MA1项的P值已提高并且非常显着(<< 0.05)。
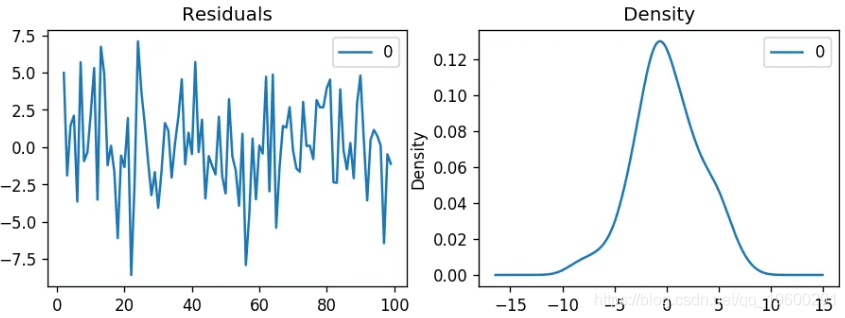
让我们绘制残差 。
![]() ?
?
残差密度
残差似乎很好,均值接近零且方差均匀。让我们使用绘制实际值和拟合值 。
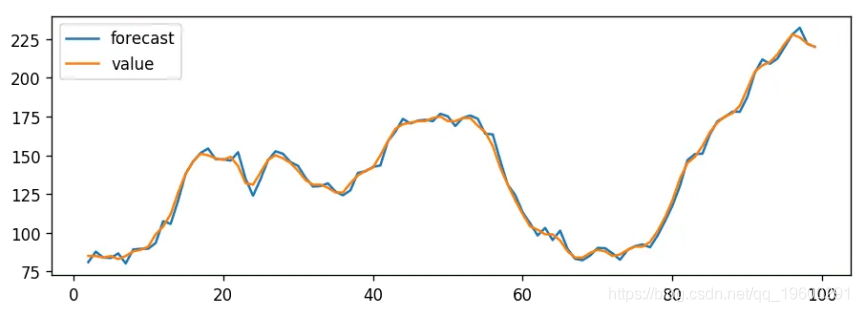
![]() ?
?
实际vs拟合
设置 dynamic=False 样本内时,滞后值用于预测。
也就是说,模型被训练到上一个值进行下一个预测。
因此,我们似乎有一个不错的ARIMA模型。但是那是最好的吗?
目前不能这么说,因为我们还没有真正预测未来,而是将预测与实际绩效进行了比较。
因此, 现在需要的真正验证是超时交叉验证。
在“交叉验证”中,可以倒退几步,并预测将来的步伐。然后,您将预测值与实际值进行比较。
要进行超时的交叉验证,您需要创建训练和测试数据集,方法是将时间序列按大约75:25的比例或基于序列时间频率的合理比例分成两个连续的部分。
为什么不随机采样训练数据?
这是因为时间序列的顺序序列应完整无缺,以便用于预测。
现在,您可以在训练数据集上构建ARIMA模型,对其进行预测和绘制。
# Plot
plt.figure(figsize=(12,5), dpi=100)
plt.plot(train, label=‘training‘)
plt.plot(test, label=‘actual‘)
plt.plot(fc_series, label=‘forecast‘)
plt.fill_between(lower_series.index, lower_series, upper_series,
color=‘k‘, alpha=.15)
plt.title(‘Forecast vs Actuals‘)
plt.legend(loc=‘upper left‘, fontsize=8)
plt.show()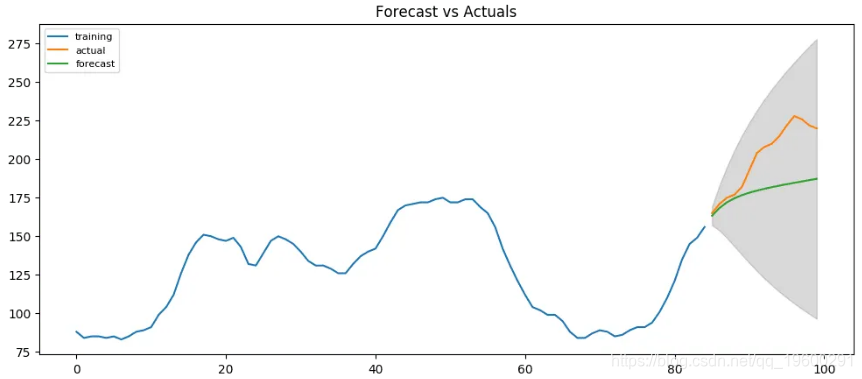
![]() ?
?
从图表中,ARIMA(1,1,1)模型似乎给出了方向正确的预测。实际观察值在95%置信带内。
但是每个预测的预测始终低于实际。这意味着,通过在我们的预测中添加一个小的常数,精度一定会提高。因此,肯定有改进的余地。
所以,我要做的是将微分的阶数增加到2,即进行设置, d=2 然后将p迭代地增加到5,然后将q反复增加到5,以查看哪个模型给出的AIC最小,同时还要寻找一个给出更接近实际情况和预测。
在执行此操作时,我会关注模型摘要中AR和MA项的P值。它们应尽可能接近零,理想情况下应小于0.05。
ARIMA Model Results
==============================================================================
Dep. Variable: D2.value No. Observations: 83
Model: ARIMA(3, 2, 1) Log Likelihood -214.248
Method: css-mle S.D. of innovations 3.153
Date: Sat, 09 Feb 2019 AIC 440.497
Time: 12:49:01 BIC 455.010
Sample: 2 HQIC 446.327
==================================================================================
coef std err z P>|z| [0.025 0.975]
----------------------------------------------------------------------------------
const 0.0483 0.084 0.577 0.565 -0.116 0.212
ar.L1.D2.value 1.1386 0.109 10.399 0.000 0.924 1.353
ar.L2.D2.value -0.5923 0.155 -3.827 0.000 -0.896 -0.289
ar.L3.D2.value 0.3079 0.111 2.778 0.007 0.091 0.525
ma.L1.D2.value -1.0000 0.035 -28.799 0.000 -1.068 -0.932
Roots
=============================================================================
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
AR.1 1.1557 -0.0000j 1.1557 -0.0000
AR.2 0.3839 -1.6318j 1.6763 -0.2132
AR.3 0.3839 +1.6318j 1.6763 0.2132
MA.1 1.0000 +0.0000j 1.0000 0.0000
-----------------------------------------------------------------------------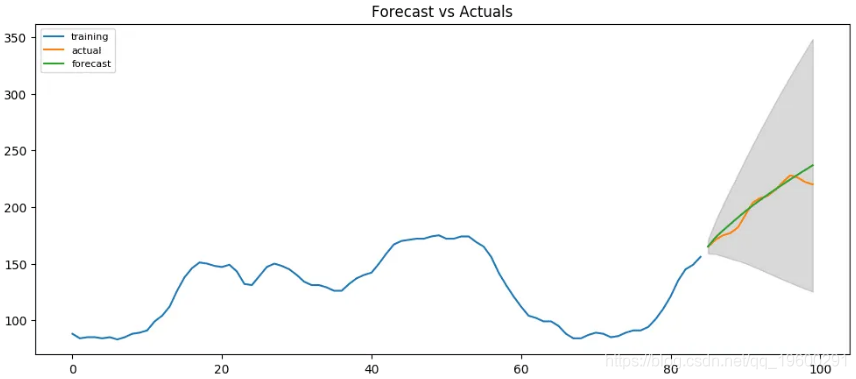
![]() ?
?
AIC已从515减少到440。X项的P值小于<0.05,这很好。
所以总的来说要好得多。
理想情况下,应该返回多个时间点,例如返回1、2、3和4个季度,并查看一年中各个时间点的预测效果如何。
用来判断预测的常用准确性指标是:
通常,如果要比较两个不同系列的预测,则可以使用MAPE,Correlation和Min-Max Error。
因为只有上述三个是百分比误差,所以误差在0到1之间变化。因此,无论序列的规模如何,您都可以判断预测的质量如何。
其他误差度量是数量。这意味着,平均值为1000的系列的RMSE为100,平均值为10的系列的RMSE为5。因此,不能真正使用它们来比较两个不同比例时间序列的预测。
forecast_accuracy(fc, test.values)
#> {‘mape‘: 0.02250131357314834,
#> ‘me‘: 3.230783108990054,
#> ‘mae‘: 4.548322194530069,
#> ‘mpe‘: 0.016421001932706705,
#> ‘rmse‘: 6.373238534601827,
#> ‘acf1‘: 0.5105506325288692,
#> ‘corr‘: 0.9674576513924394,
#> ‘minmax‘: 0.02163154777672227}大约2.2%的MAPE表示该模型在预测接下来的15个观测值时的准确性约为97.8%。
但是在工业情况下,将给您提供很多时间序列来进行预测,并且定期重复进行预测活动。
因此,我们需要一种使最佳模型选择过程自动化的方法。
使用逐步方法来搜索p,d,q参数的多个组合,并选择具有最小AIC的最佳模型。
print(model.summary())
#> Fit ARIMA: order=(1, 2, 1); AIC=525.586, BIC=535.926, Fit time=0.060 seconds
#> Fit ARIMA: order=(0, 2, 0); AIC=533.474, BIC=538.644, Fit time=0.005 seconds
#> Fit ARIMA: order=(1, 2, 0); AIC=532.437, BIC=540.192, Fit time=0.035 seconds
#> Fit ARIMA: order=(0, 2, 1); AIC=525.893, BIC=533.648, Fit time=0.040 seconds
#> Fit ARIMA: order=(2, 2, 1); AIC=515.248, BIC=528.173, Fit time=0.105 seconds
#> Fit ARIMA: order=(2, 2, 0); AIC=513.459, BIC=523.798, Fit time=0.063 seconds
#> Fit ARIMA: order=(3, 2, 1); AIC=512.552, BIC=528.062, Fit time=0.272 seconds
#> Fit ARIMA: order=(3, 2, 0); AIC=515.284, BIC=528.209, Fit time=0.042 seconds
#> Fit ARIMA: order=(3, 2, 2); AIC=514.514, BIC=532.609, Fit time=0.234 seconds
#> Total fit time: 0.865 seconds
#> ARIMA Model Results
#> ==============================================================================
#> Dep. Variable: D2.y No. Observations: 98
#> Model: ARIMA(3, 2, 1) Log Likelihood -250.276
#> Method: css-mle S.D. of innovations 3.069
#> Date: Sat, 09 Feb 2019 AIC 512.552
#> Time: 12:57:22 BIC 528.062
#> Sample: 2 HQIC 518.825
#>
#> ==============================================================================
#> coef std err z P>|z| [0.025 0.975]
#> ------------------------------------------------------------------------------
#> const 0.0234 0.058 0.404 0.687 -0.090 0.137
#> ar.L1.D2.y 1.1586 0.097 11.965 0.000 0.969 1.348
#> ar.L2.D2.y -0.6640 0.136 -4.890 0.000 -0.930 -0.398
#> ar.L3.D2.y 0.3453 0.096 3.588 0.001 0.157 0.534
#> ma.L1.D2.y -1.0000 0.028 -36.302 0.000 -1.054 -0.946
#> Roots
#> =============================================================================
#> Real Imaginary Modulus Frequency
#> -----------------------------------------------------------------------------
#> AR.1 1.1703 -0.0000j 1.1703 -0.0000
#> AR.2 0.3763 -1.5274j 1.5731 -0.2116
#> AR.3 0.3763 +1.5274j 1.5731 0.2116
#> MA.1 1.0000 +0.0000j 1.0000 0.0000
#> -----------------------------------------------------------------------------让我们查看残差图。
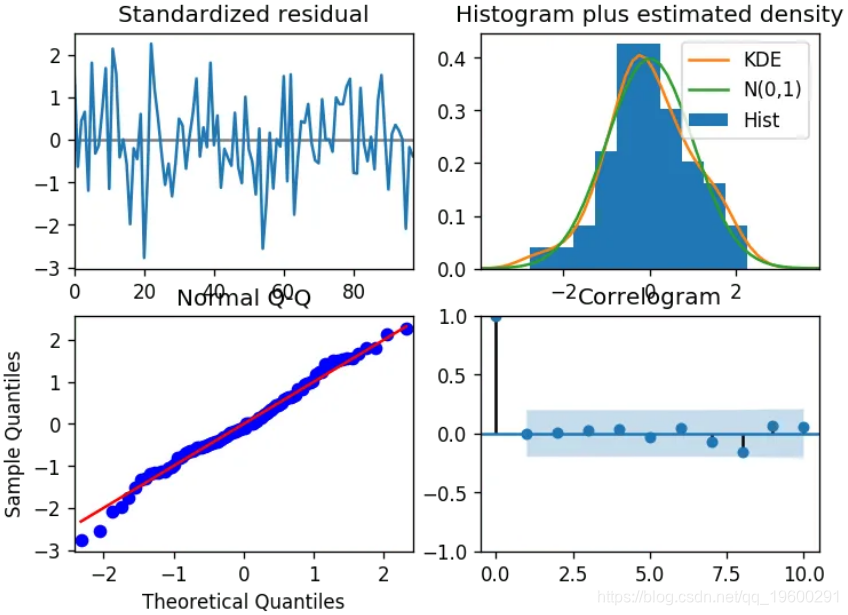
![]() ?
?
残差图
那么如何解释诊断?
左上方: 残余误差似乎在零均值附近波动,并且具有均匀的方差。
右上方: 密度图建议均值为零的正态分布。
左下: 所有圆点应与红线完全一致。任何明显的偏差都意味着分布偏斜。
右下: Correlogram(又名ACF)图显示残差误差不是自相关的。任何自相关都将暗示残留误差中存在某种模式,该模式未在模型中进行解释。因此,您将需要为模型寻找更多的X(预测变量)。
总体而言,这似乎很合适。让我们预测一下。
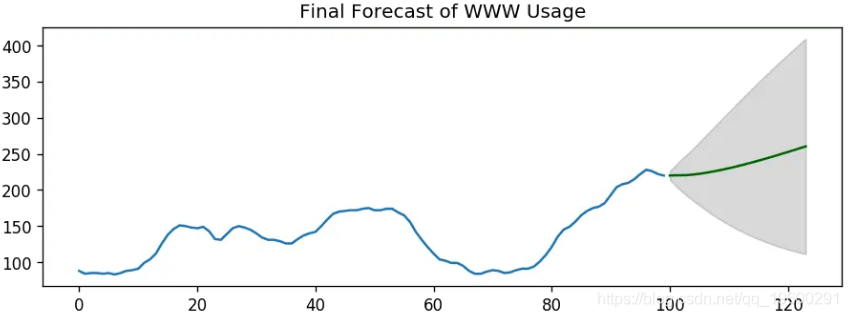
![]() ?
?
普通ARIMA模型的问题在于它不支持季节性。
如果您的时间序列定义了季节性,那么,请使用季节性差异的SARIMA。
季节性差异与常规差异相似,但是您可以从上一季节中减去该值,而不是减去连续项。
因此,该模型将表示为SARIMA(p,d,q)x(P,D,Q),其中P,D和Q分别是SAR,季节性差异的阶数和SMA项,并且 ‘x‘ 是时间的频率系列。
如果您的模型具有明确定义的季节性模式,则对给定的频率“ x”强制执行D = 1。
这是有关构建SARIMA模型的一些实用建议:
通常,将模型参数设置为D不得超过1。并且总的差异‘d + D‘永远不会超过2。如果模型具有季节性成分,请尝试仅保留SAR或SMA项。
让我们在药物销售数据集上建立一个SARIMA模型 。
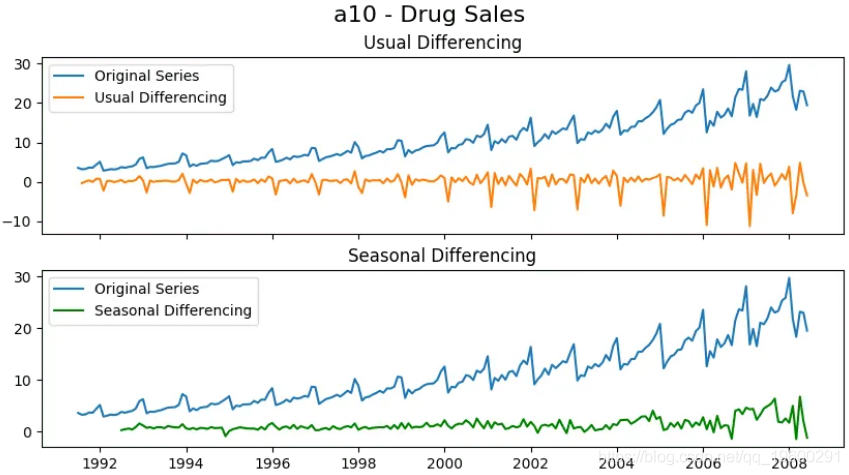
![]() ?
?
在应用通常的差异(滞后1)之后,季节性峰值是完整的。鉴于此,应在季节性差异后进行纠正。
让我们建立使用SARIMA模型。为此,您需要设置 seasonal=True,设置m=12 按月序列的频率 并强制执行 D=1。
Fit ARIMA: order=(1, 0, 1) seasonal_order=(0, 1, 1, 12); AIC=534.818, BIC=551.105, Fit time=1.742 seconds
Fit ARIMA: order=(0, 0, 0) seasonal_order=(0, 1, 0, 12); AIC=624.061, BIC=630.576, Fit time=0.028 seconds
Fit ARIMA: order=(1, 0, 0) seasonal_order=(1, 1, 0, 12); AIC=596.004, BIC=609.034, Fit time=0.683 seconds
Fit ARIMA: order=(0, 0, 1) seasonal_order=(0, 1, 1, 12); AIC=611.475, BIC=624.505, Fit time=0.709 seconds
Fit ARIMA: order=(1, 0, 1) seasonal_order=(1, 1, 1, 12); AIC=557.501, BIC=577.046, Fit time=3.687 seconds
(...TRUNCATED...)
Fit ARIMA: order=(3, 0, 0) seasonal_order=(1, 1, 1, 12); AIC=554.570, BIC=577.372, Fit time=2.431 seconds
Fit ARIMA: order=(3, 0, 0) seasonal_order=(0, 1, 0, 12); AIC=554.094, BIC=570.381, Fit time=0.220 seconds
Fit ARIMA: order=(3, 0, 0) seasonal_order=(0, 1, 2, 12); AIC=529.502, BIC=552.305, Fit time=2.120 seconds
Fit ARIMA: order=(3, 0, 0) seasonal_order=(1, 1, 2, 12); AIC=nan, BIC=nan, Fit time=nan seconds
Total fit time: 31.613 seconds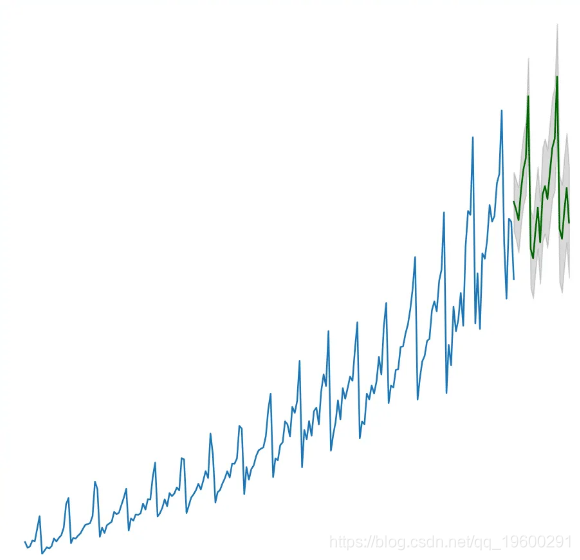
![]() ?
?
该模型估计了AIC,系数的P值看起来很重要。让我们看一下残留的诊断图。
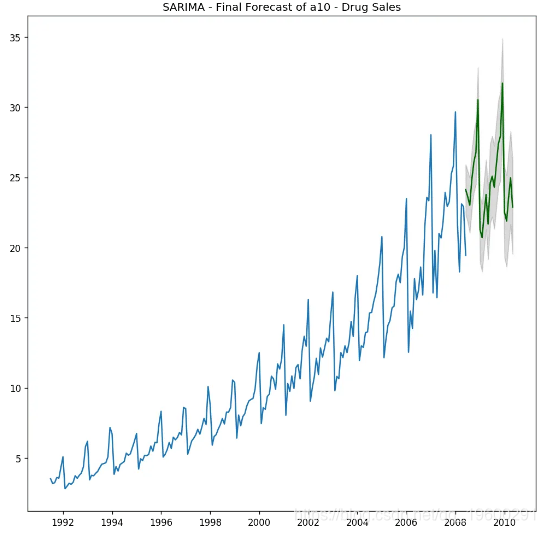
最佳模型 SARIMAX(3, 0, 0)x(0, 1, 1, 12) 的AIC为528.6,P值很重要。
让我们预测未来的24个月。
![]() ?
?
SARIMA –最终预测
我们构建的SARIMA模型很好。
但是为了完整起见,让我们尝试将外部预测变量(也称为“外生变量”)强加到模型中。该模型称为SARIMAX模型。
使用外生变量的唯一要求是您还需要在预测期内知道变量的值。
为了演示,我将对 最近36个月的数据使用经典季节性分解中的季节性指数 。
为什么要季节性指数? SARIMA是否已经在模拟季节性?
你是对的。
而且,我想看看如果我们将最近的季节性模式强加到训练和预测中,模型将如何显示。
其次,这是一个很好的演示目的变量。因此,你可以将其用作模板,并将任何变量插入代码中。季节性指数是一个很好的外生变量,因为它每个频率周期都会重复一次,在这种情况下为12个月。
因此,你将始终知道季节性指数将对未来的预测保持何种价值。
让我们计算季节性指数,以便可以将其作为SARIMAX模型的(外部)预测变量。
外生变量(季节指数)已准备就绪。让我们构建SARIMAX模型。
Fit ARIMA: order=(1, 0, 1) seasonal_order=(0, 1, 1, 12); AIC=536.818, BIC=556.362, Fit time=2.083 seconds
Fit ARIMA: order=(0, 0, 0) seasonal_order=(0, 1, 0, 12); AIC=626.061, BIC=635.834, Fit time=0.033 seconds
Fit ARIMA: order=(1, 0, 0) seasonal_order=(1, 1, 0, 12); AIC=598.004, BIC=614.292, Fit time=0.682 seconds
Fit ARIMA: order=(0, 0, 1) seasonal_order=(0, 1, 1, 12); AIC=613.475, BIC=629.762, Fit time=0.510 seconds
Fit ARIMA: order=(1, 0, 1) seasonal_order=(1, 1, 1, 12); AIC=559.530, BIC=582.332, Fit time=3.129 seconds
(...Truncated...)
Fit ARIMA: order=(3, 0, 0) seasonal_order=(0, 1, 0, 12); AIC=556.094, BIC=575.639, Fit time=0.260 seconds
Fit ARIMA: order=(3, 0, 0) seasonal_order=(0, 1, 2, 12); AIC=531.502, BIC=557.562, Fit time=2.375 seconds
Fit ARIMA: order=(3, 0, 0) seasonal_order=(1, 1, 2, 12); AIC=nan, BIC=nan, Fit time=nan seconds
Total fit time: 30.781 seconds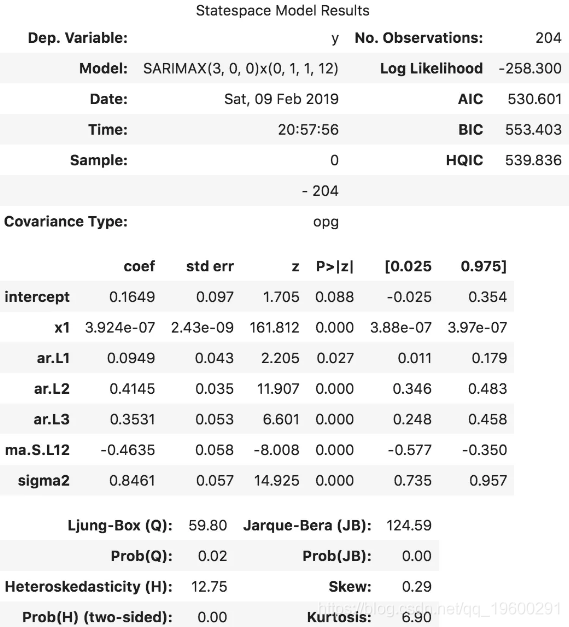
![]() ?
?
因此,我们拥有带有外生项的模型。但是该系数对于来说很小 x1,因此该变量的贡献可以忽略不计。让我们继续预测吧。
我们已有效地将模型中最近3年的最新季节性影响强加给模型。
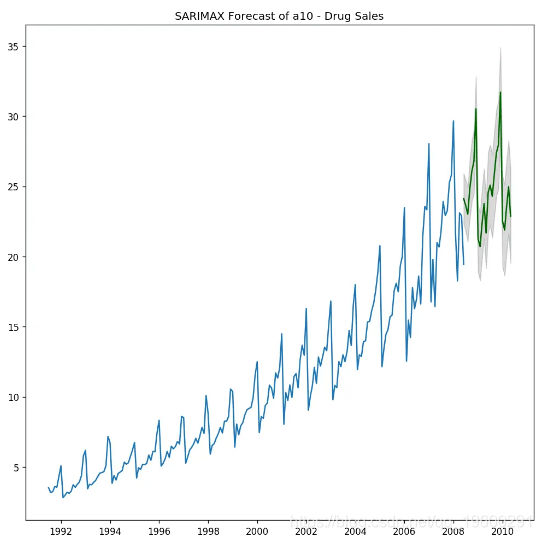
好吧,让我们预测下一个24个月。为此,你需要接下来24个月的季节性指数值。
![]() ?
?
SARIMAX预测
Python中的ARIMA模型、SARIMA模型和SARIMAX模型对时间序列预测
标签:cte 完全 png roots roo ted header 表示 种类型
原文地址:https://www.cnblogs.com/tecdat/p/12762526.html