标签:硬盘 语句 str 探索 还需 变化 模拟 加载 不能
优化sql,最重要就是优化sql索引
索引相当于字典的目录,利用字典目录查找汉字的过程相当于利用sql索引查找某条记录的过程,有了索引就能很快地定位到某条记录,加快查询速率。
进行多表连接查询、子查询等操作的时候,写出的sql语句又无法减少服务器执行的时间,这样就会导致等待返回结果的时间太长,因此导致查询速度很低。
加快查询速率
编写:select
select dinstinct (属性) from (列表)[left\join] (列表) on (属性=属性) where (过滤条件) group by (分组属性) having(分组过滤条件) order by(排序条件)limit(限制条件)
解析过程:执行顺序
from (列表) on (属性=属性) join(列表)where (过滤条件) group by (分组属性) having(分组过滤条件) select distinct order by(排序条件)limit(限制条件)
索引就是帮助MySql高效获取数据的一种【数据结构】,mysql中一般使用的是【B+树】
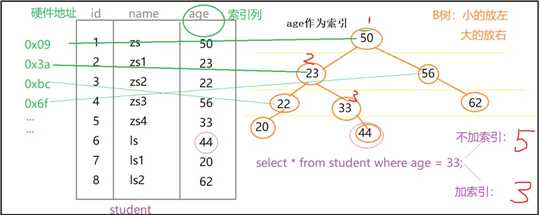
子元素比父元素小的,放在左侧;子元素比父元素大的,放在右侧,如上图所示
以
select * from student where age=33
查询语句为例。当我们不加索引的时候,会从上到下扫描源表,当扫描到第5行的时候,找到了我们想要找到了元素,一共是查询了5次。当添加了索引以后,就直接在树形结构中进行查找,33比50小,就从左侧查询到了23,33大于23,就又查询到了右侧,这下找到了33,整个索引结束,一共进行了3次查找。是不是很方便,假如我们此时需要查找age=62,你再想想“添加索引”前后,查找次数的变化情况。
索引的弊端
1.当数据量很大的时候,索引也会很大(当然相比于源表来说,还是相当小的),也需要存放在内存/硬盘中(通常存放在硬盘中),占据一定的内存空间/物理空间。
2.索引并不适用于所有情况:a.少量数据;b.频繁进行改动的字段,不适合做索引;c.很少使用的字段,不需要加索引;
3.索引会提高数据查询效率,但是会降低“增、删、改”的效率。当不使用索引的时候,我们进行数据的增删改,只需要操作源表即可,但是当我们添加索引后,不仅需要修改源表,也需要再次修改索引,很麻烦。尽管是这样,添加索引还是很划算的,因为我们大多数使用的就是查询,“查询”对于程序的性能影响是很大的
索引的优势
1.提高查询效率(降低了IO使用率)。当创建了索引后,查询次数减少了。
2.降低CPU使用率。比如说【…order by age desc】这样一个操作,当不加索引,会把源表加载到内存中做一个排序操作,极大的消耗了资源。但是使用了索引以后,第一索引本身就小一些,第二索引本身就是排好序的,左边数据最小,右边数据最大。
1)索引分类
单值索引:
create index dept_index on tb(dept);
唯一索引:
reate unique index name_index on tb(name);
复合索引
create index dept_name_index on tb(dept,name);
① 单值索引
利用表中的某一个字段创建单值索引。一张表中往往有多个字段,也就是说每一列其实都可以创建一个索引,这个根据我们实际需求来进行创建。还需要注意的一点就是,一张表可以创建多个“单值索引”。
假如某一张表既有age字段,又有name字段,我们可以分别对age、name创建一个单值索引,这样一张表就有了两个单值索引。
② 唯一索引
也是利用表中的某一个字段创建单值索引,与单值索引不同的是:创建唯一索引的字段中的数据,不能有重复值。像age肯定有很多人的年龄相同,像name肯定有些人是重名的,因此都不适合创建“唯一索引”。像编号id、学号sid,对于每个人都不一样,因此可以用于创建唯一索引。
③ 复合索引
多个列共同构成的索引。比如说我们创建这样一个“复合索引”(name,age),先利用name进行索引查询,当name相同的时候,我们利用age再进行一次筛选。注意:复合索引的字段并不是非要都用完,当我们利用name字段索引出我们想要的结果以后,就不需要再使用age进行再次筛选了。
人为优化:需要我们使用explain分析SQL的执行计划。该执行计划可以模拟SQL优化器执行SQL语句,可以帮助我们了解到自己编写SQL的好坏。
SQL优化器自动优化:最开始讲述MySQL执行原理的时候,我们已经知道MySQL有一个优化器,当你写了一个SQL语句的时候,SQL优化器如果认为你写的SQL语句不够好,就会自动写一个好一些的等价SQL去执行。
SQL优化器自动优化功能【会干扰】我们的人为优化功能。当我们查看了SQL执行计划以后,如果写的不好,我们会去优化自己的SQL。当我们以为自己优化的很好的时候,最终的执行计划,并不是按照我们优化好的SQL语句来执行的,而是有时候将我们优化好的SQL改变了,去执行。
SQL优化是一种概率问题,有时候系统会按照我们优化好的SQL去执行结果(优化器觉得你写的差不多,就不会动你的SQL)。有时候优化器仍然会修改我们优化好的SQL,然后再去执行。
1)查看执行计划
语法:explain + SQL语句
eg:explain select * from tb;
2)“执行计划”中需要知道的几个“关键字”
id :编号
select_type :查询类型
table :表
type :类型
possible_keys :预测用到的索引
key :实际使用的索引
key_len :实际使用索引的长度
ref :表之间的引用
rows :通过索引查询到的数据量
Extra :额外的信息
内容来源【数据森麟公共号】
标签:硬盘 语句 str 探索 还需 变化 模拟 加载 不能
原文地址:https://www.cnblogs.com/jiaxinHuang/p/12768778.html