标签:lov 请求 参与 角色 config ada 硬件 数据存储 ast
1、Master-Slave主从结构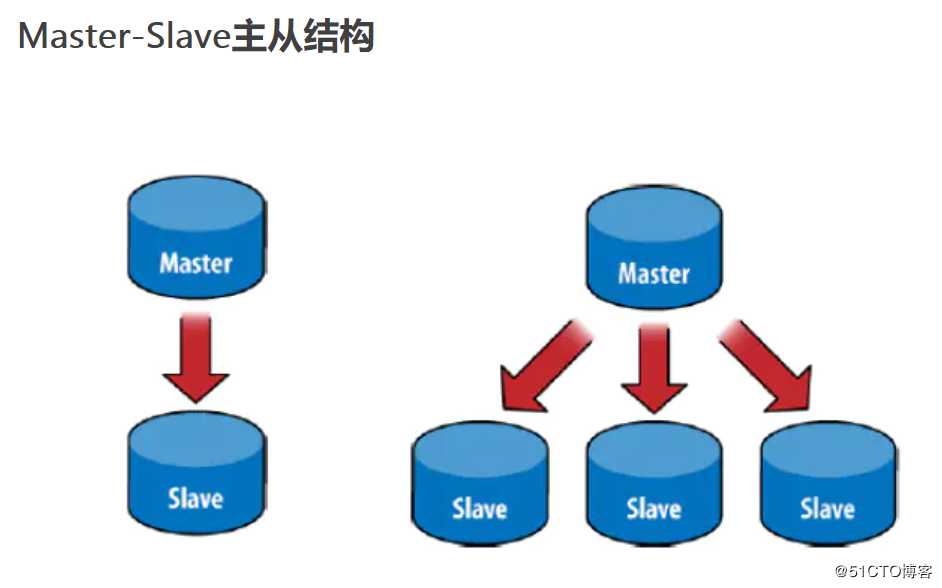
2、Relica Set副本集方式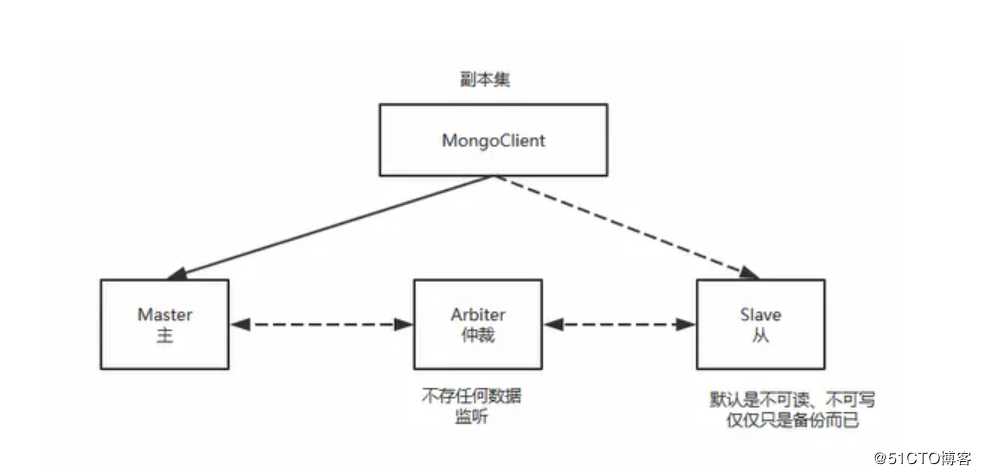
Mongodb的Replica Set即副本集方式主要有两个目的,一个是数据冗余做故障恢复使用,当发生硬件故障或者其它原因造成的宕机时,可以使用副本进行恢复。
另一个是做读写分离,读的请求分流到副本上,减轻主(Primary)的读压力。
(1)主节点(Primary)
接收所有的写请求,然后把修改同步到所有Secondary。一个Replica Set只能有一个Primary节点,当Primary挂掉后,其他Secondary或者Arbiter节点会重新选举出来一个主节点。默认读请求也是发到Primary节点处理的,需要转发到Secondary需要客户端修改一下连接配置。
(2)副本节点(Secondary)
与主节点保持同样的数据集。当主节点挂掉的时候,参与选主。
(3)仲裁者(Arbiter)
不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter跑起来几乎没什么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器上。
注意,一个自动failover的Replica Set节点数必须为奇数,目的是选主投票的时候要有一个大多数才能进行选主决策。
(4)选主过程
其中Secondary宕机,不受影响,若Primary宕机,会进行重新选主
MongoDB的Sharding架构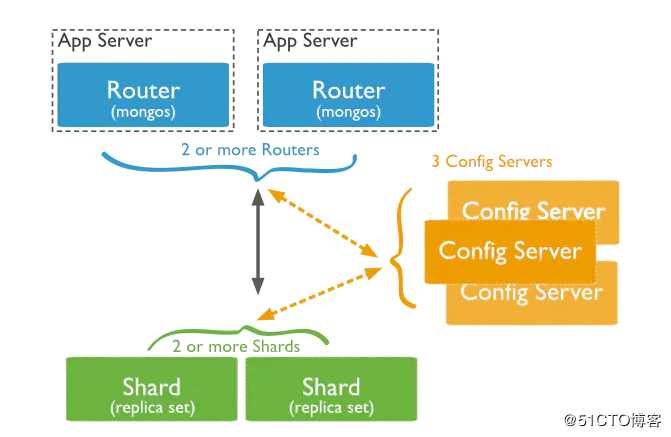
(1)数据分片(Shards)
用来保存数据,保证数据的高可用性和一致性
(2)查询路由(Query Routers)
路由就是mongos的实例,客户端直接连接mongos,由mongos把读写请求路由到指定的Shard上去
(3)配置服务器(Config servers)
保存集群的元数据(metadata),包含各个Shard的路由规则
标签:lov 请求 参与 角色 config ada 硬件 数据存储 ast
原文地址:https://blog.51cto.com/11676712/2490074