标签:tin The bin 总结 class img ado 搜索 电话
在求解诸如八皇后、全排列等问题时,我们通常使用深度优先搜索dfs在解空间内搜索满足条件的解,dfs的搜索过程可以看做是在一棵搜索树上遍历的过程。例如,求数字[1,2,3]的全排列的搜索树如下:
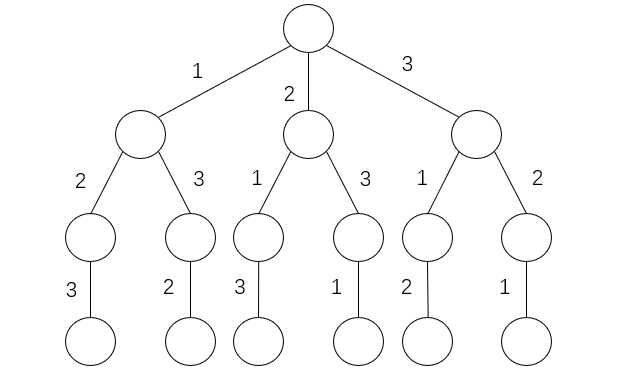
当我们搜索到树的深层向浅层返回的过程就是回溯。
(我认为可以这样理解:从上往下搜索是递归,从下往上返回是回溯。当然,这不一定正确。)
继续拿求[1,2,3]的全排列举例,我们搜索到树的底部得到了一个排列123,这时我们需要返回到上一层继续进行搜索。如果不回溯的话,那么就无法遍历整棵搜索树,也就无法求得全部的解。一般在两种情况下程序需要回溯:
大多回溯问题都遵循一个通用的模板,总体的步骤就是做选择、递归到下一层、撤销选择、回溯。
void backtrack(参数){ // start是做选择的起始位置
if(满足条件){
将当前结果加入答案中;
return;
}
for(选择 in 所有选择){
做选择;
backtrack(参数);
撤销选择;
}
}
更详细一点的表述如下:
void backtrack(start, 其他参数){ // start是做选择的起始位置
if(满足条件){
将当前结果加入答案中;
return;
}
for(int i=start; i<n; i++){
if(满足剪枝条件) continue;
做选择;
backtrack(i, 其他参数);
撤销选择;
}
}
例如,求一个数组的所有子集的代码如下:
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
if(nums.empty()) return {{}};
vector<vector<int>> ans;
vector<int> track;
backtrack(nums, 0, track, ans);
return ans;
}
void backtrack(vector<int> nums, int start, vector<int> track, vector<vector<int>>& ans){
ans.push_back(track);
for(int i=start; i<nums.size(); i++){
track.push_back(nums[i]);
backtrack(nums, i+1, track, ans);
track.pop_back();
}
}
};
可以看出,直接套用模板即可。
不同的回溯题的区别主要在两点:
首先看第一个问题,就是从哪个地方开始做选择,也就是每次递归的时候start如何设置。在全排列这题当中,我们每次递归都从数组第1个数字开始选择,而在子集这题中,我们每次都从上一次选择的位置的下一个位置开始选择。如果在做当前的选择时要考虑之前的选择,那么就要把每次递归的start设为0;如果在做当前选择的时候只考虑当前的选择以及之后的选择,那么就把start设为上一个选择的下一个位置i+1或者i。
上面的结论其实不是很准确,还是要根据不同的情况来调整。这里记录几个与start选择相关的题目:全排列、子集、组合总和和组合总和II。
当题目中要求答案中不能包含重复的解时,通常意味着要加入去重操作。为了便于去重,通常在搜索之前先对数组进行排序。举个例子,在全排列II中,数组中可能包含重复数字,例如[1,1,2],而要求答案中不包含重复的排列。经过分析可以发现,出现重复的原因是因为在同一层递归中出现了相同的数字。所以,为了去重,我们在同一层递归的迭代中,要找到和之前不相同的数字继续搜索。
相关题目:全排列II、子集II、组合总和II。
| 编号 | 题目 | 难度 |
|---|---|---|
| 1 | 全排列 | 中等 |
| 2 | 全排列II | 中等 |
| 3 | 子集 | 中等 |
| 4 | 子集II | 中等 |
| 5 | 组合总和 | 中等 |
| 6 | 组合总和II | 中等 |
| 7 | 字母大小写全排列 | 简单 |
| 8 | 电话号码的字母组合 | 中等 |
| 9 | N皇后 | 困难 |
下面的链接对回溯有更详细的解释:
标签:tin The bin 总结 class img ado 搜索 电话
原文地址:https://www.cnblogs.com/flix/p/12775581.html