标签:style blog http io color ar 使用 for sp
11.1 直接寻址表
当关键字的全域U很小,可采用直接寻址的方式。假设动态集合S的元素都取自全域U={0, 1, ..., m-1}的一个关键字,并且没有两个元素具有相同的关键字。
为表示动态集合,使用直接寻址表(diret-address table),记为T[0...m-1],其中的每个位置称为槽(slot)。直接寻找表就是按照数组索引,缺点明显。基本操作如下:
1 DIRECT-ADDRESS-SEARCH(T, k) 2 return T[k] 3 4 DIRECT-ADDRESS-INSERT(T, x) 5 T[x.key] = x 6 7 DIRECT-ADDRESS-DELETE(T, x) 8 T[x.key] = NULL
11.1-4 在大数组上以直接寻址的方式实现字典,并保证每个存储对象占用O(1)的空间,SEARCH、DELETE、INSERT的操作时间均为O(1);并且数据结构初始化的时间为O(1)。
思路:不妨设动态几何包含n个关键字,覆盖{0,1...m-1}的全域范围。则辅助数组的大小被限定为n,而大数组则>>m。不难想到可以利用栈来存入关键字,但是这样SEARCH、INSERT、DELETE操作无法达到O(1)。
因此,换个思路,将关键字存储在栈里面,而大数组则保存栈的位置。通过关键字匹配以及栈顶与数组中位置的大小可以确定唯一的元素。
代码实现如下:
1 int T[MAXN]; 2 int stack[MAXM], top=0; 3 4 int Direct_Address_Search(int T[], int k) { 5 if (T[k]>=0 && T[k]<top && stack[T[k]]==k) 6 return T[k]; 7 return -1; 8 } 9 10 void Direct_Address_Insert(int T[], int k) { 11 T[k] = top; 12 stack[top++] = k; 13 } 14 15 void Direct_Address_Delete(int T[], int x) { 16 if (x < 0) 17 return ; 18 --top; 19 T[stack[top]] = x; 20 stack[x] = stack[top]; 21 }
11.2 散列表
散列表即哈希,利用散列函数(hash function)h,由关键字k计算出槽的位置。函数h将关键字的全域U映射到散列表T[0...m-1]的槽位上:
h: U -> {0,1,...,m-1}
这里的散列表的大小m一般要比|U|小得多。当然,这就会引发一个问题:两个关键字可能会映射到一个槽中。我们称这种情形为冲突(collision)。
通过链接法解决冲突
链接法,即把散列到同一槽中的所有元素都放在一个链表中。给定一个能存放n个元素的、具有m个槽位的散列表T,定义T的装载因子(load factor)α为n/m,即一个链的平均存储元素数。
散列方法的平均性能依赖于所选取的散列函数h,将所有的关键字集合等可能地散列到m个槽中的任何一个,且与其他元素被散列到什么位置上无关。我们称这个散列为简单均匀散列(simple uniform hashing)。
对于j=0,1,...,m-1,列表T[j]的长度用n_j表示,于是有n = n_0 + n_1 + ... + n_(m-1),并且n_j的期望值为E[n_j] = α = n/m。
定理11.1 在简单均匀散列的假设下,对于用链接法解决冲突的散列表,一次不成功查找的平均时间为Θ(1+α)。
定理11.2 在简单均匀散列的假设下,对于用链接法解决冲突的散列表,一次不成功查找的平均时间为Θ(1+α)。
这也意味着如果散列表中槽数至少与表中的元素数成正比,则有n=O(m),从而α = n/m = O(m)/m = O(1)。所以,查找操作平均需要O(1)的时间,当链表采用双向链表时,插入操作在最坏情况下需要O(1)的时间,删除操作在最坏情况下也需要O(1)的时间。因而,全部的字典操作可以再O(1)的时间内完成。
11.2-1 n个关键字散列到长度为m的数组T中,假设采用均匀散列,期望的冲突数是多少?
解 E[h(k)=h(l), k!=l] = n*(n-1)/2 * 1/m = n(n-1)/2m。
11.2-3 O(1+α/2)
11.2-4
伪代码如下:
1 #define MAXN 1005 2 #define MAXM 105 3 4 typedef struct Slot_t { 5 bool free; 6 int val; 7 Slot_t *prev, *next; 8 } Slot_t; 9 10 Slot_t T[MAXN]; 11 Slot_t *free; 12 13 int hash(int val) { 14 return (val+1)%MAXM; 15 } 16 17 void init_Slot() { 18 for (int i=0; i<MAXN-1; ++i) { 19 T[i].free = true; 20 if (i) 21 T[i].prev = &T[i-1]; 22 T[i].next = &T[i+1]; 23 } 24 T[0].prev = NULL; 25 T[MAXN-1].free = true; 26 T[MAXN-1].prev = &T[MAXN-2]; 27 T[MAXN-1].next = NULL; 28 free = T[0]; 29 } 30 31 Slot_t *Direct_Address_Search(Slot_t T[], int val) { 32 int key = hash(val); 33 Slot_t *p = &T[key]; 34 35 while ( p!=NULL && !p->free ) { 36 if (p->val == val) 37 return p; 38 p = p->next; 39 } 40 return NULL; 41 } 42 43 void Direct_Address_Insert(Slot_t T[], int val) { 44 if (free == NULL) 45 return ; 46 int key = hash(val); 47 Slot_t *p; 48 49 if (T[key].free) { 50 T[key].val = val; 51 T[key].free = false; 52 // cut the T[key] from the free list 53 if (T[key].prev != NULL) 54 T[key].prev->next = T[key].next; 55 if (T[key].next != NULL) 56 T[key].next->prev = T[key].prev; 57 T[key].prev = T[key].next = NULL; 58 } else { 59 if (hash(T[key].val) != key) { 60 memcpy(free, T[key], sizeof(Slot_t)); 61 T[key].val = val; 62 T[key].prev = T[key].next = NULL; 63 } else { 64 T[free].free = false; 65 T[free].val = val; 66 T[free].prev = &T[key]; 67 T[free].next = T[key].next; 68 if (T[key].next != NULL) 69 T[key].next->prev = &T[free]; 70 T[key].next = &T[free]; 71 } 72 free = free->next; 73 } 74 } 75 76 void Direct_Address_Delete(Slot_t T[], int val) { 77 int key = hash(val); 78 Slot_t *p = Direct_Address_Search(val), *q; 79 80 if (p == NULL) 81 return ; 82 if (p == &T[key]) { 83 if (p->next == NULL) { 84 p->free = true; 85 p->next = free; 86 free = p; 87 } else { 88 // copy p->next to p 89 q = p->next; 90 memcpy(p, p->next, sizeof(Slot_t)); 91 p->prev = NULL; 92 // delete p->next 93 if (p->next != NULL) 94 p->next->prev = p; 95 q->free = true; 96 q->next = free; 97 free = q; 98 } 99 } else { 100 p->free = true; 101 p->prev->next = p->next; 102 if (p->next != NULL) 103 p->next->prev = p->prev; 104 p->next = free; 105 free = p->next; 106 } 107 }
11.2-6
解:已知n = L_0 + L_1 + ... + L_(m-1), max{L_0, L_1, L_(m-1)} = L。求均匀随机选择某一元素的期望。
E[1/n * Sigma(1..n, (L_hash(xi)+1)/2)] = 1/2n * [ Sigma(i=0..(m-1), L_i*L_i) + n] < 1/n * [Sigma(i=0..(m-1), L_i*L_i) + mL] < L/n * [Sigma(i=0..(m-1), L_i) + m] = L/n * (n+m) = L*(1+m/n) = L*(1+1/α) = O(L*(1+1/α))
11.3 散列函数
除法散列与乘法散列本质上属于启发式方法,而全域散列则利用了随机技术来提供可证明的良好性能。
好的散列函数的特点
好的散列函数应(近似地)满足简单均匀散列假设:每个关键字都被等可能地散列到m个槽位中的任何一个,并与其他关键字已散列到哪个槽位无关。
除法散列法
在用来设计散列函数的除法散列法中,通过取k除以m个余数,将关键字k映射到m个槽位中的某一个上,即散列函数为:
h(k) = k mod m
一个不太接近2的整数幂的素数,常常是m个一个较好的选择。
乘法散列法
构造散列函数的乘法散列法包含两个步骤:第一步,用关键字k乘上常数A(0<A<1),并提取kA的小数部分。第二步,用m乘以这个值,再向下取整。总之,散列函数为:
h(k) = floor(m(kA mod 1))
这里kA mod 1是取kA的小数部分,即kA - ceil(kA)。
11.3-1
由于需要在长度为n的链表中搜索,因此先计算源串的hash(key),再用这个值不断与链表中元素的hash(key)值进行比较,若相等则返回该节点指针。
11.3-2
11.3-3
11.3-4
1 int hash(int key) { 2 double A = (sqrt(5.0)-1)/2; 3 double tmp = key*A; 4 return (int) ( m*(tmp - (int)tmp) ); 5 }
11.4 开放寻址法
在开放寻址法(open addressing)中,所有的元素存放在散列表里。也就是说,每个表象或包含动态集合的一个元素,或包含NIL。当查找某个元素时,要系统地检查所有的表项,直到找到所需的元素,或者最终查明该元素不在表中。不像链接法,这里既没有链表,也没有元素存在散列表外。因此在开放寻址法中,散列表可能被填满。为了使用开放寻址法插入一个元素,需要连续地检查散列表,或称为探查(probe)。有三种主要的探查方法:
线性探查
给定一个普通的散列函数h‘:U -> {0, 1, ..., m-1}, 称之为辅助散列函数(auxiliary hash),线性探查(linear probing)方法采用的散列函数为:
h(k, i) = (h‘(k) + i) mod m, i = 0, 1, ..., m-1
给定一个关键字k,首先探查T[h‘(k)],即由辅助散列函数所给出的槽位。再探查槽T[h‘(k)+1],以此类推,直至槽T[m-1].然后,又绕到T[0], T[1], T[0], ..., 直到最后探查到T[h‘(k)-1]。在线性探查方法中,初始探查位置决定了整个序列,故只有m种不同的探查序列。
线性探查方法比较容易实现,但它存在一个问题,称为一次群集(primary cluster)。随着连续被占用的槽不断增加,平均查找时间也随之不断增加。群集现象很容易出现,这是因为当一个空槽前有i个满的槽时,该空槽为下一个将被占用的概率是(i+1)/m。连续被占用的槽就会越来越长,因而平均查找时间也会越来越大。
二次探查
二次探查(quadratic probing)采用如下形式的散列函数: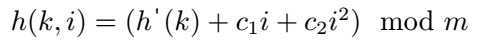
其中h’是一个辅助散列函数,c1和c2为正的辅助常数。初始的探查位置为T[h‘(k)],后续的探查位置要加上一个偏移量,该偏移量以二次的方式依赖于探查序号i。这种探查方法的效果要比线性探查好得多。此外,如果两个关键字的初始探查位置相同,那么它们的探查序列也是相同的,这是因为h(k1, 0) = h(k2, 0)蕴含着h(k1, i) = h(k2, i)。这一性质可能导致一种轻度的群集,称为二次群集(secondary cluster)。像在线性探查中一样,初始探查位置决定了整个序列,这样也仅有m个不同的探查序列被用到。
双重散列
双重散列(double hashing)是用于开放寻址法的最好方法之一,因为它所产生的排列具有随机选择排列的许多特性。双重散列采用如下形式的散列函数: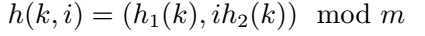
其中h1和h2均为辅助散列函数。初始探查位置为T[h1(k)],后续的探查位置是前一个位置加上偏移量h2(k)摸m。
定理11.6 给定一个装载因子为α=n/m<1的开放寻址散列表,并假设是均匀散列的,则对于一次不成功的查找,其期望的探查次数最多为1/(1-α)。
推论11.7 假设采用的是均匀散列,平均情况下,向一个装载因子为α的开放寻址散列表中插入一个元素至多需要做1/(1-α)次探查。
定理11.8 对于一个装载因子为α<1的开放寻址散列表,一次成功查找中的探查期望数至多为(1/α)ln(1/(1-α))
11.4-1
线性探查 32 88 - - 4 15 28 17 59 31 10
二次探查 22 - 88 17 4 - 28 59 15 31 10
双重散列 22 - 59 17 4 15 28 88 - 31 10
11.4-2
1 HASH-INSERT(T, k) 2 i = 0 3 repeat 4 j = h(k, i) 5 if T[j]==NIL or T[j]==DELETED 6 T[j] = k; 7 return j 8 else i = i + 1 9 until i==m 10 error "hash table overflow" 11 12 HASH_DELETE(T, k) 13 i = HASH_SEARCH(T, k) 14 if i!=NIL 15 T[i] = DELETED
标签:style blog http io color ar 使用 for sp
原文地址:http://www.cnblogs.com/bombe1013/p/4008722.html