标签:原因 推荐 gre 根据 height 生成 图片 常用 data
客户端+服务器+存储引擎
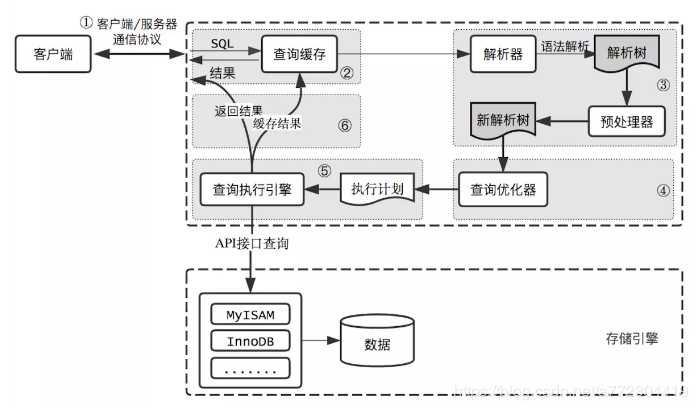
查看存储引擎: show engines.我的电脑里默认的是InnoDB;
InnoDB和MyISAM索引采用的是B+树, MEMORY采用的是Hash索引.
MySql中最常用的的存储引擎是InnoDB和MyISAM.
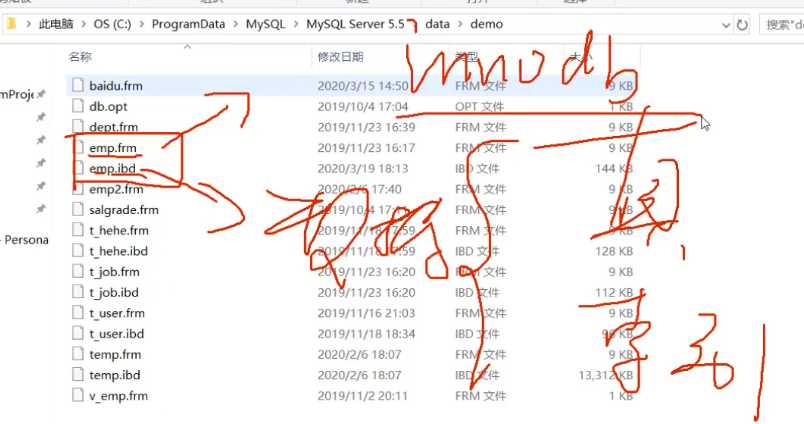
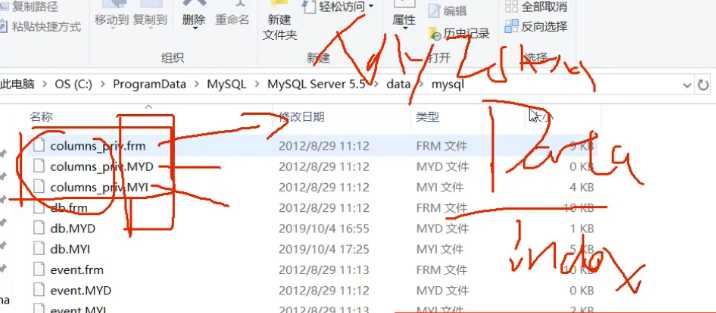
前者在磁盘中会落2个文件,分别是.frm和.ibd..frm代表form files,代表格式文件..ibd中包含真实数据和索引数据.
而myISAM中会落3个文件,分别是.frm,.MYD和.MYI,其中后面两种格式代表真实数据和索引数据.
内存和磁盘交互:
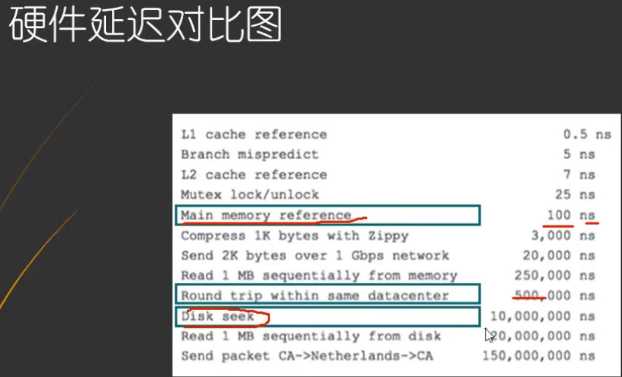
磁盘预读:预读的长度一般是页的整数倍.页是存储器(包括内存和磁盘)的逻辑块,通常为4KB,内存和磁盘以页来为单位交换数据.InnoDB默认一次预读16KB的数据.
为什么要创建索引:
如果没有索引,查找数据是全表扫描,而如果有索引的话,会按照B+树的结构去查找数据.
创建索引是个什么过程?
就是把数据组织成数据结构的过程.
存储在文件系统中,存储形式和存储引擎有关,索引文件的结构包括hash,二叉树,B树和B+树.
hash表:是数组+链表的结构.
hash作为索引存在的问题 :
1.哈希函数不容易选择
2.hash存储需要将所有的数据文件添加到内存(why?待后知后觉),浪费内存空间.
3.等值查询用hash比较快,但是实际中范围查询更多,hash不太合适.
以上问题使得hash没有作为大部分存储引擎(查找数据是与磁盘进行交互)的数据结构.而MEMORY存储引擎是在内存中进行的,使用它的时候就接受它占内存的问题了,另外在内存中查找速度很快.
二叉树,红黑树存在的问题:
树中元素存储的是数据值,树在物理结构上是数组进行存放的,可能逻辑结构上很近的数据(比如父子)在物理结构上会相差很远(比如当树很大时).因此,每次读取磁盘页的数据很多是用不上的.可能需要进行很多次的IO交互才能够找到要找的数据.
都会因为树的深度太深而造成io次数变多(指的是内存和磁盘交互的次数),影响读取的效率.
提升IO效率的两个方法:
1.减少IO的次数
2.减少IO的大小
eg:不推荐使用select(*)的原因,是因为它会把磁盘中全表的数据都拉到内存(mysql的服务)中,然后在内存中去进行筛选,筛选完毕后给到客户端中.
B树:
树中节点存储的是数据块.
图中紫色的代表键值,它可能是记录的主键.
树的阶数(degree)等于它可以最多存储指针的个数(数据的个数比指针个数少1).
比如下面的这个示意图,它最多能够存3个指针,两个data,它的degree是3.
假如当前磁盘块的大小为16KB,每个data占1KB的内存,忽略键值和指针,一个磁盘块中可以存16个data,即阶为17.那么三层树可以存储的数据量16+17*16+17*17*16=16*(1+17+17*17)=4912条数据.从这里可以看出来影响存储数据多少的因素是data的大小,而这个时候B+树就比较合适了.
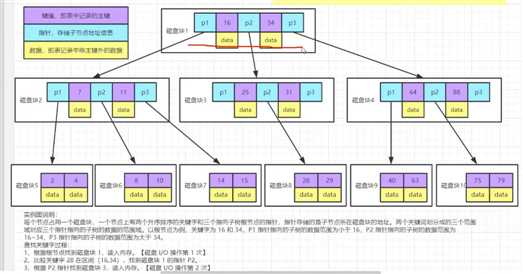
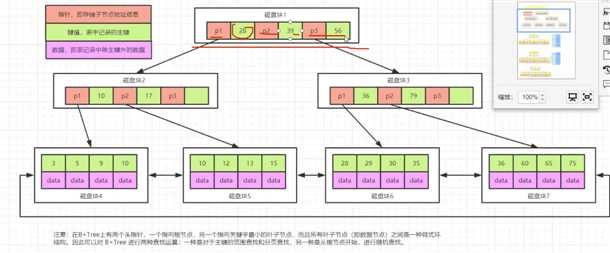
B+树:
同样的3层树,如果前两层只存储键值和指针的话,那么对应存储的指针数就会大大增加,假如前两层每个磁盘可以存储1600个指针,第三层仍然是存储16个数据,那么三层树总共可以存储的数据量=1600*1600*16 = 40960000,差不多数据容量增加了1万倍.
注意这里为什么特别在意树的层数呢?因为树的层数越深,查找树的次数就越多(最坏情况,单枝退化成了链表).
B+树中有两种查找方式:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找.
InnoDB,叶子节点中放置的是数据,对应.ibd,<-> 聚簇/聚集索引.
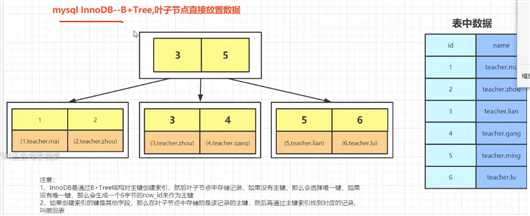
注意:
1.InnoDB对主键创建索引,也就是把主键作为B+树中的Key,如果没有主键,会选择唯一键,如果没有唯一键,会生成一个6字节的row_id(不可见)来作为主键(都是为了保证key的唯一性).
2.如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后再通过主键索引找到对应的记录,这个过程叫做回表.
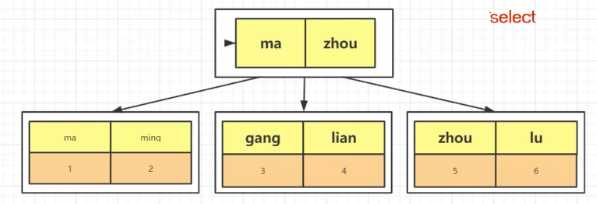
比如下图中又对表中的name建立了索引(称为二级索引/辅助索引),如果要执行select * from table where name = "ma",根据"ma"找到了主键1,这个时候还需要根据主键回到表中查找所有的列.而如果select id from table where name = "ma"的话,则不会触发回表.
MyISAM中叶子节点冲存储的是地址,然后根据地址去查找数据.所以存储文件是.MYI,.MYD. <->非聚簇索引.
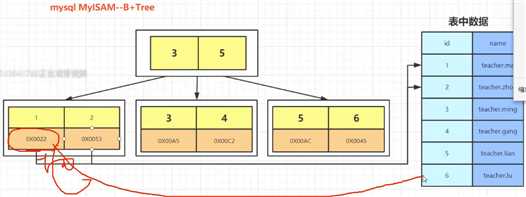
MySQL的B+树三层还是四层,取决于数据量的多少.
主键自增:
分布式不推荐(分布式中有自己的主键生成策略),
非分布式推荐.
主键自增,能够保证后面插入的数据在建立索引时从添加到树的结尾.如果主键是乱序的话,在创建索引时,会插入到中间位置.如果中间位置满了,会导致页分裂,会造成维护上很麻烦.(添加到结尾,如果数据满了也会造成页分裂,但没有中间插入的那种情况严重).
索引优化相关:
1.尽量用int来存储索引,它只占4个字节,而varchar会占用比较多的字节.
2.
标签:原因 推荐 gre 根据 height 生成 图片 常用 data
原文地址:https://www.cnblogs.com/Stephen-Qin/p/12769136.html