标签:环境 block 地方 eee 有一个 git sla 总结 box
转自:https://durant35.github.io/2017/10/29/VM_Stacks/
Linux 中有几种栈?各种栈的内存位置?
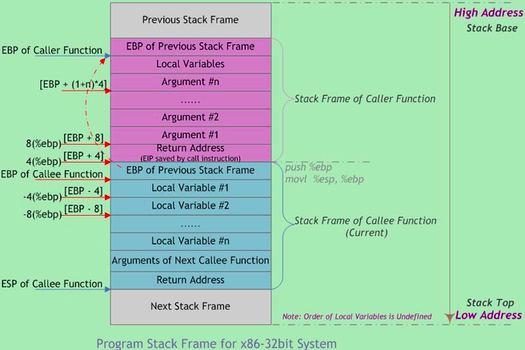
EBP 和 栈指针 ESP 界定,EBP指向当前栈帧底部 (高地址),在当前栈帧内位置固定;ESP指向当前栈帧顶部 (低地址);ESP会随着数据的入栈和出栈而移动,因此函数中对大部分数据的访问都基于EBP进行。进程虚拟地址空间中的栈区,正指的是我们所说的进程栈。进程栈是属于用户态栈,和进程虚拟地址空间 (Virtual Address Space) 密切相关。
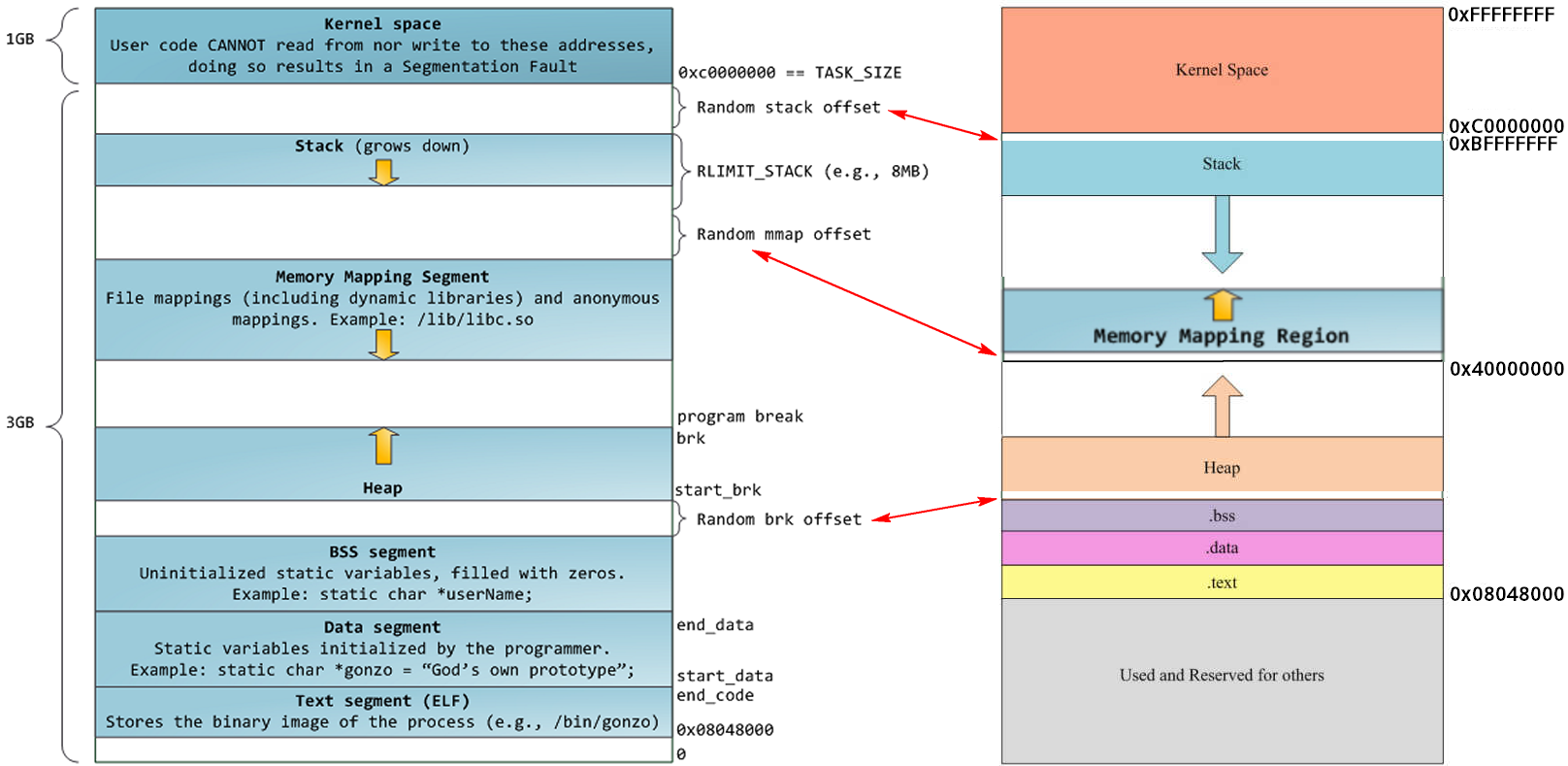
RLIMIT_STACK (一般为 8M),我们可以通过 ulimit 来查看或更改 RLIMIT_STACK 的值 (stack size):
1
|
gary@xxx:~$ ulimit -a
|
RLIMIT_STACK,那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制; 从 Linux 内核的角度来说,其实它并没有线程的概念,Linux 把所有线程都当做进程来实现,它将线程和进程不加区分的统一到了 task_struct 中;线程仅仅被视为一个与其他进程共享某些资源的进程,而是否共享地址空间几乎是进程和 Linux 中所谓线程的唯一区别。线程创建的时候,加上了 CLONE_VM 标记,这样线程的内存描述符将直接指向父进程的内存描述符。
VM_STACK_FLAGS 标记。
task_struct 中,应该是使用 pthread_attr_t 中的 stackaddr 来初始化 task_struct->thread->sp(sp 指向 struct pt_regs 对象,该结构体用于保存用户进程或者线程的寄存器现场)task_struct 的很多字段,其中包括所有的 vma,因此如果愿意,其它线程也还是可以访问到的,于是一定要注意!esp 为 0x7ffc8000FF00,此时父进程主动休眠了;esp 为初始值 0x7ffc80000000,则线程 A1 一但出现函数调用,必然会破坏父进程 A 已入栈的数据;esp 为 0x7ffc8000FF00,那线程 A1 进行一些函数调用后,栈指针 esp 增加到 0x7ffc8000FFFF,然后线程 A1 休眠;调度器再次换成父进程 A 执行,那这个时候父进程的栈指针是应该为 0x7ffc8000FF00 还是 0x7ffc8000FFFF 呢?在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈。
进程内核栈在进程创建的时候,通过 slab 分配器 从
thread_info_cache缓存池中分配出来,大小为THREAD_SIZE,一般来说是一个页大小 4K;
所有进程运行的时候,都可能通过系统调用陷入内核态继续执行:假设第一个进程 A 陷入内核态执行的时候,需要等待读取网卡的数据,主动调用 schedule() 让出 CPU;此时调度器唤醒了另一个进程 B,碰巧进程 B 也需要系统调用进入内核态;那问题就来了,如果内核栈只有一个,那进程 B 进入内核态的时候产生的压栈操作,必然会破坏掉进程 A 已有的内核栈数据,一但进程 A 的内核栈数据被破坏,很可能导致进程 A 的内核态无法正确返回到对应的用户态了。
线程和进程创建的时候都调用 dup_task_struct() 来创建 task 相关结构体,而内核栈也是在此函数中 alloc_thread_info_node() 出来的,因此虽然线程和进程共享一个地址空间
mm_struct,但是并不共享一个内核栈(本来线程就是 CPU 调度的基本单位)。
current当前进程
current来获得当前进程。
内核开发者设计了一种能找到运行在相关 CPU 上的当前进程的机制;因为
current的引用会频繁发生,因此这种机制必须是快速的。
thread_info结构体,该结构体中则记录了对应进程的描述符task_struct。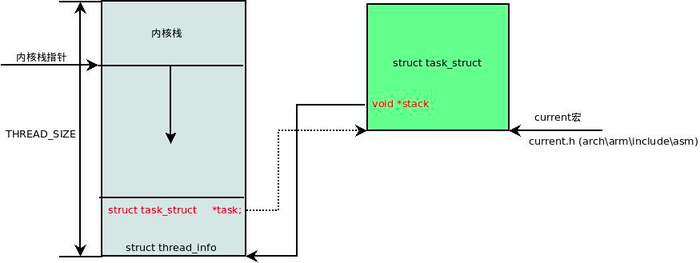
1
|
union thread_union {
|
esp,然后通过 esp 来获取 thread_info;thread_info 后,直接取出它的 task 成员就成功得到了task_struct,也就是如下 current 宏的实现方法:
1
|
register unsigned long current_stack_pointer asm ("sp");
|
thread_union 结构体是从thread_info_cache 的 Slab 缓存池中申请出来的,而 thread_info_cache 在 kmem_cache_create 创建的时候,保证了地址是 THREAD_SIZE对齐的;THREAD_SIZE 对齐,即可获得 thread_union 的地址,也就获得了 thread_info 的地址:直接将 esp 的地址与上 ~(THREAD_SIZE - 1)进程陷入内核态的时候,需要内核栈来支持内核函数调用;中断也是如此,当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。
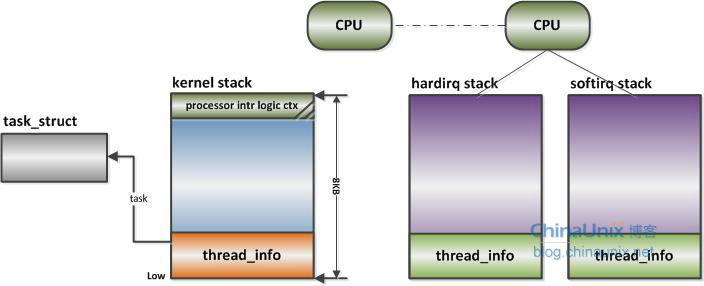
x86 上中断栈就是独立于内核栈的,独立的中断栈所在内存空间的分配发生在
arch/x86/kernel/irq_32.c的 irq_ctx_init() 函数中(如果是多处理器系统,那么每个处理器都会有一个独立的中断栈)。
- 函数使用 __alloc_pages() 在低端内存区分配 2 个物理页面,也就是 8KB 大小的空间。
- 这个函数还会为 softirq 分配一个同样大小的独立堆栈,如此说来,softirq 将不会在 hardirq 的中断栈上执行,而是在自己的上下文中执行。
这个问题其实不对,ARM 架构就没有独立的中断栈。
本文标题:虚拟内存[02] Linux 中的各种栈:进程栈 线程栈 内核栈 中断栈
文章作者:Gary
发布时间:2017-10-29, 22:01:00
最后更新:2020-03-28, 12:37:22
虚拟内存[02] Linux 中的各种栈:进程栈 线程栈 内核栈 中断栈【转】
标签:环境 block 地方 eee 有一个 git sla 总结 box
原文地址:https://www.cnblogs.com/sky-heaven/p/12788807.html