标签:sys 含义 退出 装包 上下文 日志 windows 怎么 service
最近的项目需要用到Redis数据库和MySQL,恶补学习。
Redis的使用手册可以看:
https://www.runoob.com/redis/redis-tutorial.html
Redis(Remote Dictionary Server ),即远程字典服务,其名字的来由也是这几个单词的首字母相加。是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis数据库是非关系型数据库的代表之一,即NoSQL,NoSQL并不是 no SQL,而是not only SQL,不仅仅是SQL的意思。
Redis数据库的运行速度非常惊人,在官方的测试中,读的速度是110000次/s,写的速度是81000次/s 。
为什么Redis的运行速度这么快,原因在于:
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1); 2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的; 3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗; 4、使用多路I/O复用模型,非阻塞IO; 5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
而在这样的速度下,Redis却是单线程运行达到的。很多人会认为多线程的速度一定大于单线程,其实这是一个误区,单线程和多线程谁更快实际上是要看具体情况进行分析。
多线程的运行需要CPU进行上下文的切换,而上下文切换是需要时间的,当线程很多的时候,进行上下文切换反而会成为消耗时间比较多的操作。而Redis是大部分操作是基于内存的,CPU并不是Redis的瓶颈,Redis的瓶颈是机器的内存或者网络带宽,所以避免上下文切换浪费不必要的时间,直到今天也是采用的单线程的方案。
注意:redis 单线程指的是网络请求模块使用了一个线程,即一个线程处理所有网络请求,其他模块仍用了多个线程。
这里还有一则轶事,是Redis默认端口号的来由。
我们都知道Redis的默认端口号是6379,其来由是Merz在九宫格手机上的数字顺序(去知乎偷了图片,原问题链接为:https://www.zhihu.com/question/20084750)

6-M 3-e 7-r 9-z
后来 Antirez 重新定义了 "MERZ" ,形容”具有很高的技术价值,包含技艺、耐心和劳动,但仍然保持简单本质“。
到了给 Redis 选择一个数字作为默认端口号时,Antirez 没有多想,把 "MERZ" 在手机键盘上对应的数字 6379 拿来用了。
$ sudo apt update
然后一键安装
$ sudo apt install redis-server
稍等一会就可以安装好了,redis的安装包很小
安装好之后我们启动redis
$ sudo service redis start
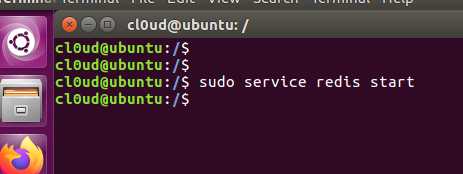
可以看到输入了之后回车好像没有什么反应,那怎么看是否启动了呢,可以使用
$ ps -ef | grep "redis"
看到显示redis进程正在运行当中
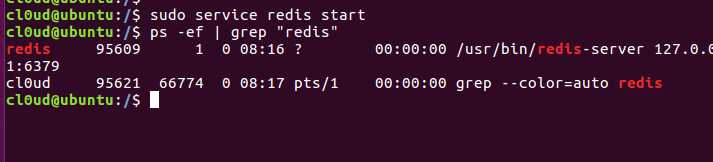
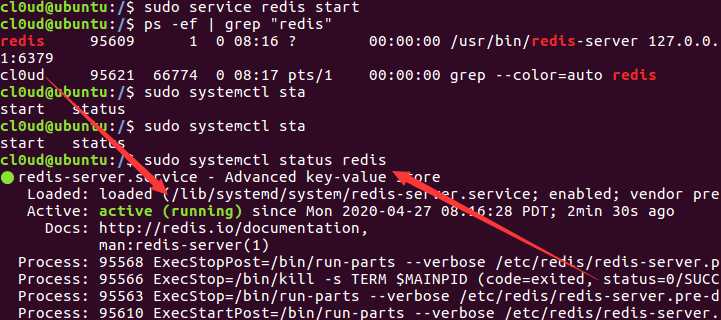
也可以这样检查redis运行状态:
$ sudo systemctl status redis
可以看到绿色的running,代表其正在运行
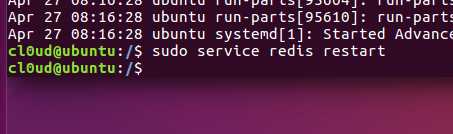
redis的重启使用命令:
$ sudo service redis restart
redis的停止使用命令:
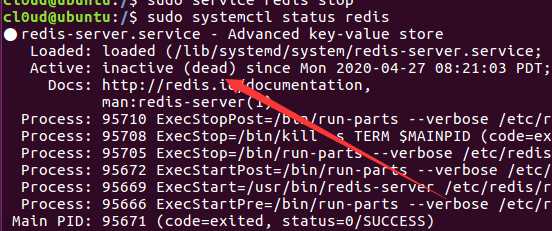
$ sudo service redis stop
这个时候再查看redis是否运行,可以看到已经没有运行了
接着我们在redis运行的时候,同时运行客户端进行连接
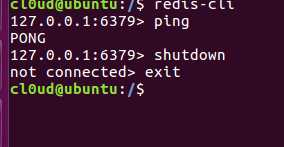
$ redis-cli
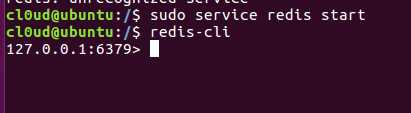
可以看到本地连接成功
使用PING-PONG进行测试与服务器的连接是否仍然生效,或者用于测量延迟值,如果服务器运作正常的话,会返回一个 PONG 。
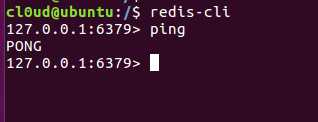
可以看到我们的服务器是运行正常的
断开客户端使用命令
shutdown
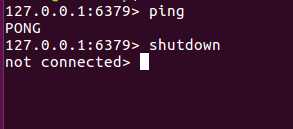
最后退出,使用命令
exit
有空再写Redis里的五种基本类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
标签:sys 含义 退出 装包 上下文 日志 windows 怎么 service
原文地址:https://www.cnblogs.com/Cl0ud/p/12787398.html