标签:nal treenode 插入 自己 next style 指定位置 一个 new
HashMap的put方法执行过程可以通过下图来理解(摘自某大厂的博客,推荐从参考文献的链接去查看原文),自己有兴趣可以去对比源码更清楚地研究学习。
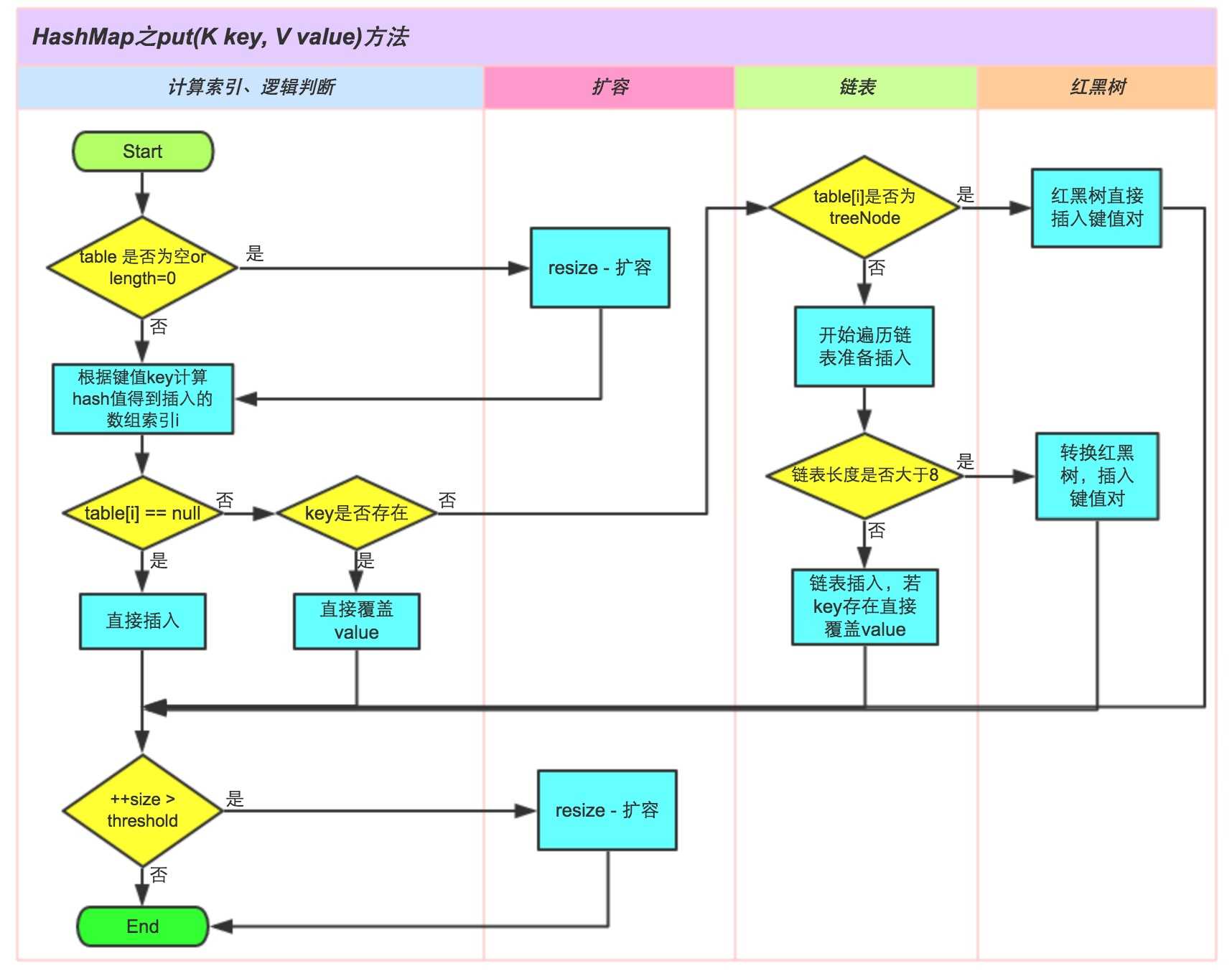
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hashCode值进而求得元素的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥;否则,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value;否则,转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对;否则,转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作;否则,进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
Java 8 中,HashMap的实现相比于Java 7做了很大的改变,但是,从Java 8 到 Java 13 ,其实现并未改变,下面分析 Java 13中 HashMap Put函数源码:
/**
* 链表转为红黑树的临界值
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 红黑树退化为链表的临界值
*/
static final int UNTREEIFY_THRESHOLD = 6;
// 构造函数 put
public V put(K key, V value) {
// 对key的hashCode()做hash
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 步骤①:tab为空则创建
if ((tab = table) == null || (n = tab.length) == 0) // 如果table为null或者没有元素,则扩容
n = (tab = resize()).length;
// 步骤②:计算index,并对null做处理
// 如果首结点值为空,则创建一个新的首结点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else { // 出现哈希碰撞,开始处理
Node<K,V> e; K k;
// 步骤③:节点key存在,直接覆盖value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; // 判断元素相等的标准:p与新元素有相同的哈希值和key值
// 步骤④:判断该链为红黑树
// 如果首结点的类型是红黑树类型,则按照红黑树方法添加该元素
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 步骤⑤:判断该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { // 如果遍历到末尾时,先在尾部追加该元素结点
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // 当遍历的结点数目大于8时,则采取树化结构
treeifyBin(tab, hash);
break;
}
// 如果找到与新元素具有相同的hash和key值的结点,则停止遍历。此时e已经记录了该结点
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;// p指向下一个节点
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 如果允许修改节点,则修改
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); //节点被访问的回调函数,可根据需要覆盖
return oldValue; // 返回旧值
}
}
++modCount; //如果执行到了这里,说明插入了一个新的节点,所以会修改modCount,以及返回null
//步骤⑥:超过最大容量时进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict); // 这个是空函数,可根据需要覆盖
return null;
}
分析:
1 数组tab为null或为空?若是,则resize();
2计算key的hash值i,若tab[i]==null,新建节点;否则,转入3
3 判断首节点处理hash冲突的方式是链表还是红黑树(check第一个节点类型),分别处理。
例如,使用链表处理时,利用Node类的next变量来实现链表,把最新的元素放到链表头,旧的数据则被最新元素的next变量引用。
桶的树形化 treeifyBin()
//将桶内所有的 链表节点 替换成 红黑树节点
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//如果当前哈希表为空,或者哈希表中元素的个数小于树形化阈值,就去新建/扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//如果哈希表中的元素个数超过了 树形化阈值,进行树形化
// e 是哈希表中指定位置桶里的链表节点,从第一个开始
TreeNode<K,V> hd = null, tl = null; //红黑树的头、尾节点
do {
//新建一个树形节点,内容和当前链表节点 e 一致
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null) //确定树头节点
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
//让桶的第一个元素指向新建的红黑树头结点,以后这个桶里的元素就是红黑树而不是链表了
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
return new TreeNode<>(p.hash, p.key, p.value, next);
}
https://zhuanlan.zhihu.com/p/21673805
标签:nal treenode 插入 自己 next style 指定位置 一个 new
原文地址:https://www.cnblogs.com/east7/p/12797601.html