标签:需要 智能 详细信息 net 工作流 汇总 并且 优化 逻辑
一 、Durid介绍Apache Druid是一个高性能的实时分析数据库。它是为快速查询和摄取的工作流而设计的。Druid的优势在于即时数据可见性,即时查询,运营分析和处理高并发方面。
Druid不是关系数据库,需要的是数据源,而不是表。与关系数据库相同的是,这些是表示为列的数据的逻辑分组。与关系数据库不同的是没有连接的概念。因此,Netflix需要确保每个数据源中都包含Netflix要过滤或分组依据的任何列。数据源中主要有三类列-时间,维度和指标。
Druid的一切都取决于时间。每个数据源都有一个timestamp列,它是主要的分区机制。维度是可用于过滤,查询或分组依据的值。指标是可以汇总的值。
通过消除执行联接的能力,并假设数据由时间戳作为键,Druid可以对存储,分配和查询数据的方式进行一些优化,从而使Netflix能够将数据源扩展到数万亿行,并且仍然可以实现查询响应时间在十毫秒内。
为了达到这种级别的可伸缩性,Druid将存储的数据分为多个时间块。时间块的持续时间是可配置的。可以根据您的数据和用例选择适当的持续时间。
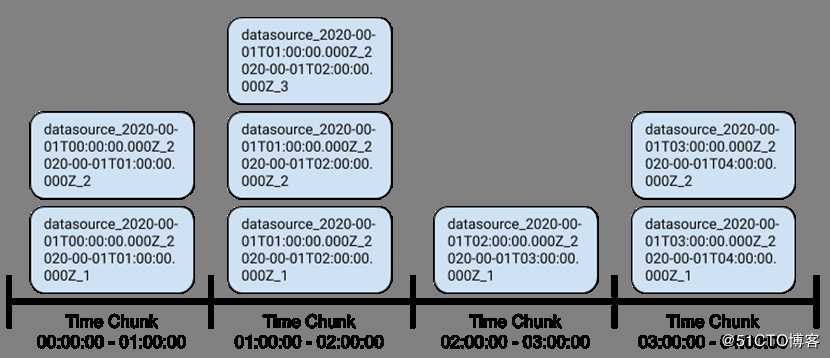
Netflix使用来自回放设备的实时日志作为事件源,Netflix可以得出测量值,以了解和量化用户设备如何无缝地处理浏览和回放。

一旦有了这些度量,就将它们输入数据库。每项措施均标有关于所用设备种类的匿名详细信息,例如,设备是智能电视,iPad还是Android手机。这使Netflix能够根据各个方面对设备进行分类并查看数据。反过来,这又使系统能够隔离仅影响特定人群的问题,例如应用程序的版本,特定类型的设备或特定国家/地区。以通过仪表板或临时查询立即使用此聚合数据进行查询。还会连续检查指标是否有警报信号,例如新版本是否正在影响某些用户或设备的播放或浏览。这些检查用于警告负责的团队,他们可以尽快解决该问题。
在软件更新期间,Netflix为部分用户启用新版本,并使用这些实时指标来比较新版本与以前版本的性能。指标中的任何回归都会使Netflix发出中止更新的信号,并使那些将新版本恢复为先前版本的用户恢复原状。
由于该数据每秒可处理超过200万个事件,因此将其放入可以快速查询的数据库是非常艰巨的。Netflix需要足够的维数以使数据在隔离问题中很有用,因此,Netflix每天产生超过1150亿行。
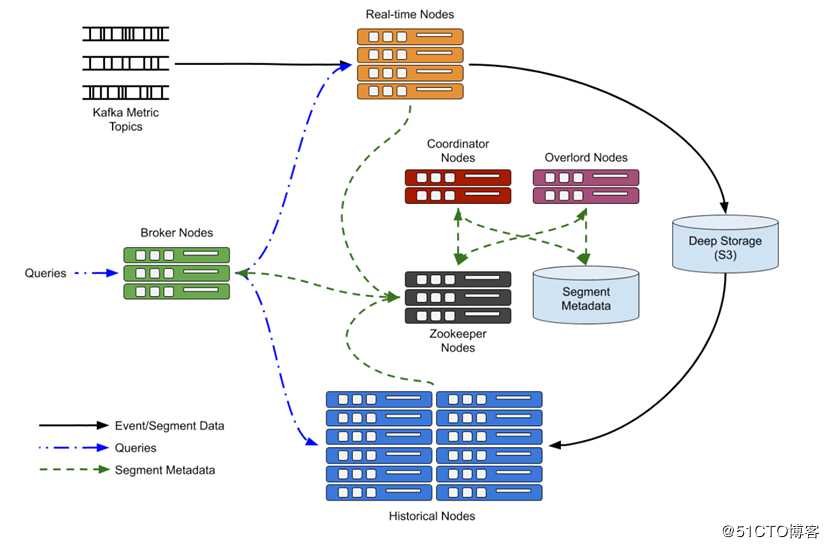
数据摄取
插入到该数据库是实时发生的。不是从数据集中插入单个记录,而是从Kafka流中读取事件(在Netflix的情况下为指标)。每个数据源使用1个主题。在Druid中,Netflix使用Kafka索引编制任务,该任务创建了多个在实时节点(中间管理者)之间分布的索引编制工作器。
这些索引器中的每一个都订阅该主题并从流中读取其事件共享。索引器根据摄入规范从事件消息中提取值,并将创建的行累积在内存中。一旦创建了行,就可以对其进行查询。到达索引器仍在填充一个段的时间块的查询将由索引器本身提供。由于索引编制任务实际上执行两项工作,即摄取和现场查询,因此及时将数据发送到“历史节点”以更优化的方式将查询工作分担给历史节点非常重要。
Druid可以在摄取数据时对其进行汇总,以最大程度地减少需要存储的原始数据量。汇总是一种汇总或预聚合的形式。在某些情况下,汇总数据可以大大减少需要存储的数据大小,从而可能使行数减少几个数量级。但是,减少存储量确实需要付出一定的代价:Netflix无法查询单个事件,而只能以预定义的查询粒度进行查询。对于Netflix的用例,Netflix选择了1分钟的查询粒度。
在提取期间,如果任何行具有相同的维度,并且它们的时间戳在同一分钟内(Netflix的查询粒度),则这些行将被汇总。这意味着通过将所有度量标准值加在一起并增加一个计数器来合并行,因此Netflix知道有多少事件促成了该行的值。这种汇总形式可以显着减少数据库中的行数,从而加快查询速度,因为这样Netflix就可以减少要操作和聚合的行。
一旦累积的行数达到某个阈值,或者该段已打开太长时间,则将这些行写入段文件中并卸载到深度存储中。然后,索引器通知协调器该段已准备好,以便协调器可以告诉一个或多个历史节点进行加载。一旦将该段成功加载到“历史”节点中,就可以从索引器中将其卸载,并且历史记录节点现在将为该数据提供任何查询。
数据处理
随着维数基数的增加,在同一分钟内发生相同事件的可能性降低。管理基数并因此进行汇总,是获得良好查询性能的强大杠杆。为了达到所需的摄取速率,Netflix运行了许多索引器实例。即使汇总在索引任务中合并了相同的行,在相同的索引任务实例中获取全部相同的行的机会也非常低。为了解决这个问题并实现最佳的汇总,Netflix计划在给定时间块的所有段都已移交给历史节点之后运行任务。此计划的压缩任务从深度存储中获取所有分段以进行时间块化,并执行映射/还原作业以重新创建分段并实现完美的汇总。然后,由“历史记录”节点加载并发布新的细分,以替换并取代原始的,较少汇总的细分。通过使用此额外的压缩任务,Netflix看到行数提高了2倍。知道何时收到给定时间块的所有事件并不是一件容易的事。可能有关于Kafka主题的迟到数据,或者索引器可能会花一些时间将这些片段移交给Historical Node。
查询方式
Druid支持两种查询语言:Druid SQL和本机查询。在后台,Druid SQL查询被转换为本地查询。本机查询作为JSON提交到REST端点,这是Netflix使用的主要机制。
对集群的大多数查询是由自定义内部工具(例如仪表板和警报系统)生成的。
为了加快采用Druid的查询速度并实现对现有工具的重用,Netflix添加了一个转换层,该层接受Atlas查询,将其重写为Druid查询,发布查询并将结果重新格式化为Atlas结果。这个抽象层使现有工具可以按原样使用,并且不会为用户访问Netflix的Druid数据存储中的数据创建任何额外的学习曲线。
**更多精彩内容可以专注我们的在线课堂
微信搜索公众号:jfrogchina 获取课程通知**
标签:需要 智能 详细信息 net 工作流 汇总 并且 优化 逻辑
原文地址:https://blog.51cto.com/jfrogchina/2491717