标签:数组 art comm pen 识别 单列 加载 java 技术
Hibernate是一个开放源代码的ORM(Object Relational Mapping,对象关系映射)框架,他对JDBC进行了轻量级的对象封装,使得Java开发人员可以使用面向对象的编程思想来操作数据库。
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- 添加Hibernate依赖 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>3.6.10.Final</version>
</dependency>
<!-- 添加Log4J依赖 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.6.4</version>
</dependency>
<!-- 添加javassist -->
<dependency>
<groupId>javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.12.0.GA</version>
</dependency>
<!-- mysql数据库的驱动包 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
</dependencies>
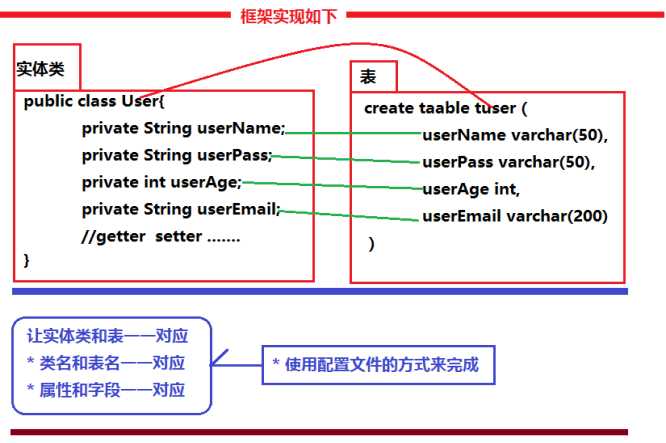
- 使用配置文件实现配置关系;
- ① 创建一个xml格式的配置文件
- 映射配置文件的名称和位置没有严格要求,建议在实体类所在的包内进行常见,命名规则是:实体类名称.hbm.xml 例如:User.hbm.xml
-② 配置的是XML格式的,在配置中首先要引入XML的约束,
③ 配置实体类和映射表的映射关系
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <!— 1.配置类和表的对应 class标签 name属性:实体类的全名称 table属性:数据库表名称 (表还没有创建,我们让hibernate帮我们自动生成) --> <class name="org.atwyl.entity.User" table="t_user"> <!— 2.配置实体类的id和表里面的id对应 hibernate要求实体类有一个属性具有唯一值 hibernate要求表里面有一个字段是唯一值 --> <!-- id:标签 name属性:实体类里面id属性的名称 column属性:生产的表字段的名称 --> <id name="uid" column="uid"> <!-- 设置增长的策略(主键生成的方式) native:表的uid是主键自增 --> <generator class="native"></generator> </id> <!-- 配置其他的属性和表的对应 name:实体类属性的名称,要和实体类里面的名称保持一致 column:表的字段的名称 name和column可以一样也可以不一样,为了方便记忆,我们保持一致 --> <property name="username" column="username"></property> <property name="password" column="password"></property> <property name="address" column="address"></property> </class> </hibernate-mapping>
<?xml version=‘1.0‘ encoding=‘utf-8‘?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> <property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property> <property name="hibernate.connection.url">jdbc:mysql://127.0.0.1:3306/myschool</property> <property name="hibernate.connection.username">root</property> <property name="hibernate.connection.password">971128</property> <!-- 2、配置hibernate的信息,可选的 --> <!-- 输出底层的SQL语句 --> <property name="hibernate.show_sql">true</property> <!-- 底层SQL语句进行格式化 --> <property name="hibernate.format_sql">true</property> <!-- 希望hibernate帮我们自动创建表 update:如果表已有,它就更新表,如果没有表,则创建表 --> <property name="hibernate.hbm2ddl.auto">update</property> <!-- 表示数据库的方言 在MySQL中,我们要实现分页,关键字:limit,这个关键字只能使用在MySQL里面 在Oracle数据库中,分页就没有limit,Oracle是rownum 让hibernate框架,来识别我们不同数据库里面不同的SQL语句 --> <property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect</property> <!-- 3、把映射文件放到核心配置文件中:必须的 --> <mapping resource="entity/Student.hbm.xml"/> <mapping class="entity.Teacher"/> <!-- <property name="connection.username"/> --> <!-- <property name="connection.password"/> --> <!-- DB schema will be updated if needed --> <!-- <property name="hbm2ddl.auto">update</property> --> </session-factory> </hibernate-configuration>
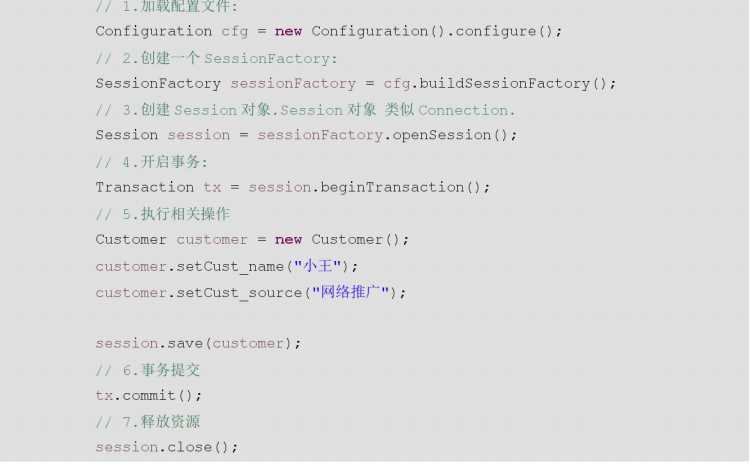
- ① 创建SessionFactory对象的过程中,它会做一些事情
- - 根据核心配置文件中,有数据库的配置,有映射文件的部分,它会到数据库里面根据映射关系把表进行创建,前提是,必须有入下配置
- -
- ① 在hibernate操作中,建议一个项目创建一个SessionFactory对象。
3 基于以上的问题,我们来创建工具类
- ① 可以写静态代码块来实现(静态代码块,在类加载的时候执行,只会执行一次)

Session
特点:
- ① save(),update(),saveOrUpdate() 方法:用于增加和修改对象
- ② delete() 方法:用于删除对象
- ③ get()和load() 方法:根据主键查询
- ④ createQuery() 和 createSQLQuery():用于数据库操作对象
- ⑤ createCriteria() 方法:条件查询
- Session不能公用,只能自己用
1.什么是主键生成策略?
-实体类里面有一个唯一的属性,我们的表的主键有自增的,还有不是自增的 , 还有可能是UUID,这个叫生成的策略。
2.在Hibernate里面主键的生成策略提供了很多种方法:
|
名称 |
描述 |
|
increment |
对主键值,采取自动顺序增长的方式生成新的主键,值默认从1开始。 |
|
UUID |
原理UUID使用128位UUID算法生成主键,能够保证网络环境下的主键唯一性,也就能够保证在不同数据库及不同服务器下主键的唯一性。所以适用于所有数据库。 |
|
Hilo |
通过hi/lo 算法(Hilo使用高低位算法生成主键,高低位算法使用一个高位值和一个低位值,然后把算法得到的两个值拼接起来)实现的主键生成机制,需要额外的数据库表保存主键生成历史状态。 |
|
sequence |
sequence实际是就是一张单行单列的表, 调用数据库中底层存在的sequence生成主键,需要底层数据库的支持序列,因此他是依赖于数据库的。Oracle数据库可以。 |
|
identity |
根据底层数据库,来支持自动增长,不同的数据库用不同的主键增长方式。 |
|
native |
根据数据库的类型,自动在sequence 、identity和,hilo进行切换。实现自动切换的依据:根据Hibernate配置文件中的方言来判断是Oracle还是Mysql、SqlServer,然后针对数据库的类型抉择 sequence还是identity作为主键生成策略。 |
|
assigned |
用于手工分配主键生成器,一旦指定为这个了,Hibernate就不在自动为程序做主键生成器了。没有指定<generator>标签时,默认就是assigned主键的生成方式 |
|
foreign |
只适用基于共享主键的一对一关联映射的时候使用。即一个对象的主键是参照的另一张表的主键生成的。 |
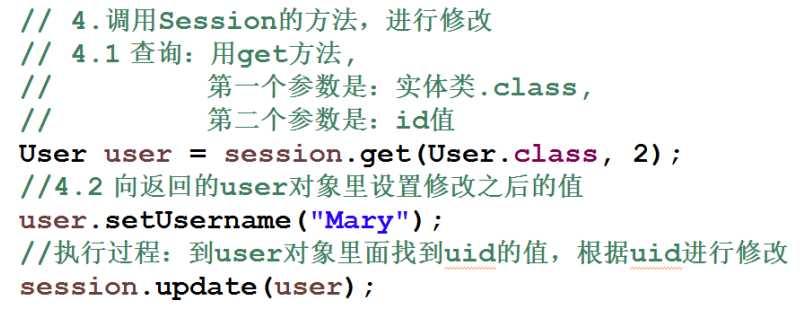
// 1.调用工具类得到SessionFactory SessionFactory sessionFactory = HibernateUtils.getSessionFactory(); // 2.获取Session Session session = sessionFactory.openSession(); // 3.开启事务 Transaction tx = session.beginTransaction(); // 4.调用Session的方法,根据id查询 // get方法,第一个参数是:实体类.class,第二个参数:id值 User user = session.get(User.class, 1); System.out.println("查询结果:" + user.getAddress() + " --- " + user.getUsername()); // 5.提交事务 tx.commit(); // 6.关闭 session.close(); sessionFactory.close();

数据一般都存到我们的数据库里面,其实数据库本来就是一个文件系统,要操作文件,要用Java的IO流的方式来操作,但是如果文件里面有很多的内容,我们的效率会受到影响,我们可以使用如下方式进行解决效率的问题:
- ① 我们可以把数据存到存到系统的内存里面,不需要使用流的方式,可以直接读取内存中的数据
- ② 把数据存入内存中,提供读取效率会更高
- 我们把数据存入内存中,使读取的效率更高,这就是缓存。
- ① 一级缓存
- (1)hibernate的以及缓存,默认就是开启的
- (2)hibernate中的以及缓存,有使用范围,是session的范围,就是从session创建到关闭session之间的一个范围。
- (3)hibernate的一级缓存中,存储的数据必须是持久态的,其他两个状态不会存储到缓存中。
- ② 二级缓存
- (1)目前已经很少使用了,替代的技术:Redis
- (2)二级缓存默认是关闭的,需要配置才能完成
- (3)二级缓存的范围,是sessionFactory的范围,一个项目只有一个sessionFactory,所二级缓存是一个项目的范围的。
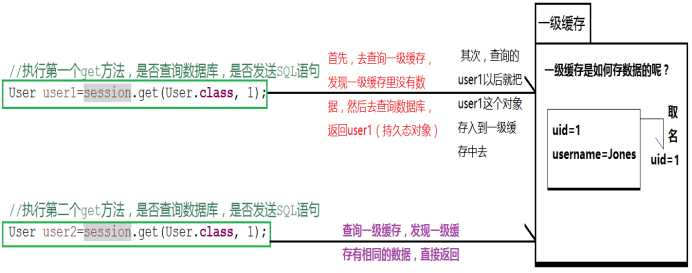
- (1) 根据uid=1进行查询,返回对象
- (2)在同一个session中,我再根据uid=1查询,返回的还是一个对象
通过断点调试,我们发现第一个get请求,发送了SQL语句,第二个get请求 , 没有发送SQL语句,而且两个对象的内存地址完全一样,说明两个对象是同一个对象,第二个对象没有与数据库打交道,而是直接从内存中取出数据,查询的是一级缓存中的内容,这就是一级缓存的存在的体现。

在hibernate中,可以通过代码来操作管理事务,通过代码来操作管理事务
如通过:“Transaction tx=session.beginTransaction();”开启一个事务;持久化操作后;
通过 ”tx.commit();” 提交事务;如果事务出现异常,有通过 “tx.rollback();”操作来撤销事务(回滚事务)。
除了在代码中对事务开启,提交和回滚操作外,还可以在hibernate的配置文件中对事务进行配置。在配置文件中,可以设置事务的隔离级别。其具体的配置方法是在hibernate的核心配置文件:hibernate.cfg.xml文件中的<session-factory>标签元素中进行的,配置方法如下:
到这里我们已经设置了事务的隔离级别,那么我们在真正进行事务管理的时候,需要考虑其事务应用的场景,也就是说我们的事务控制不应该是在dao层实现的,应该在service层实现,并在Service中调用多个DAO实现一个业务逻辑操作。
try { // 开启事务 // 提交事务 } catch (Exception e) { // 回滚事务 }finally{ // 关闭操作 } SessionFactory sessionFactory=null; Session session =null; Transaction tx=null; try { // 1.调用工具类得到SessionFactory sessionFactory = HibernateUtils.getSessionFactory(); // 2.获取Session session = sessionFactory.openSession(); // 3.开启事务 tx = session.beginTransaction(); // 4.调用Session的方法 User user=new User(); user.setUsername("商鞅"); user.setAddress("大秦帝国"); user.setPassword("123123"); session.save(user); // 5.提交事务 tx.commit();// 此处会提交的数据库 } catch (Exception e) { // 回滚事务 tx.rollback(); e.printStackTrace(); } finally { // 6.关闭 session.close(); sessionFactory.close(); }
在我们的代码中,有个Session这个对象,这个对象是单线程的,单线程的意思是,只能自己用不能别人共用,在我们实际开发中,我们的Session要保证单线程的;现在有个问题,如果说我们的项目是我自己来用,我们如何写都无所谓,但是我们实际开发我们的项目是很多人一起用,这个时候,Session就很难保证单线程的对象。我们如何保证他绝对是一个单线程对象呢?
我们可以让Session跟我们本地的线程绑定,这样就可以保证Session的单线程:
在hibernate5中自身提供了三种管理session对象的方法:
- ? Session对象的生命周期与本地线程绑定
- ? Session对象的生命周期与JTA事务绑定
- ? Hibernate委托程序管理Session对象的生命周期
在Hibernate核心配置文件中 , hibernate.current_session_context_class 属性用于指定 Session的管理方式,可选值包括:
- ? thread:Session对象的生命周期与本地程序绑定
- ? jta : Session 对象的生命周期与JTA事务绑定
- ? managed : Hibernate 委托程序来管理Session对象的生命周期
- ? 在 hibernate.cfg.xml中进行如下配置:
- 
- ? hibernate提供sessionFactory.getCurrentSession()创建一个Session和ThreadLocal绑定方法,在HibernateUtils工具类中更改getCurrentSession方法:
public static Session getCurrentSession(){ return sessionFactory.getCurrentSession(); }
- 而且Hibernate中提供的这个与线程绑定的session可以不用关闭,当前线程结束后,就会自动关闭了。
到这里我们已经对Hibernate的事务管理有了基本的了解,但是之前我们做的CRUD的操作其实还没有查询多条记录。
- ① 在hibernate的核心配置文件先进行配置
- 
- ② 调用SessionFactory里面的一个方法可以得到
- 
- ③ 测试
Transaction tx=null; Session session =null; try { // 1.获取Session session = HibernateUtils.getCurrentSession(); // 2.开启事务 tx = session.beginTransaction(); // 3.调用Session的方法 User user=new User(); user.setUsername("元始天尊"); user.setAddress("昆仑玉清境"); user.setPassword("123123"); session.save(user); // 4.提交事务 tx.commit();// 此处会提交的数据库 } catch (Exception e) { // 回滚事务 tx.rollback(); e.printStackTrace(); } finally { // 5.关闭 session.close(); }
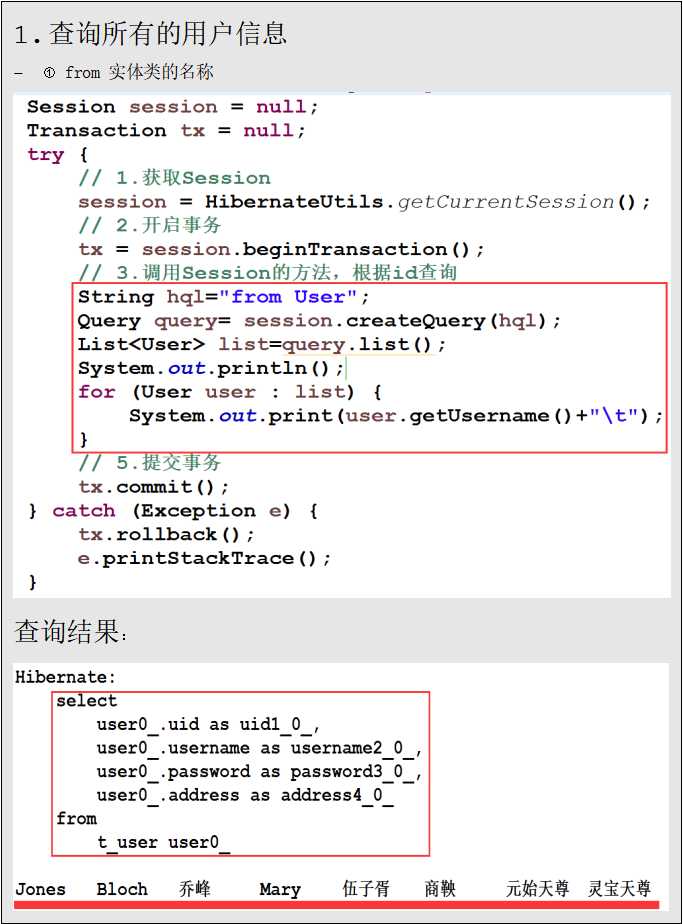
Query代表面向对象的一个Hibernate查询操作,在Hibernate中,通常使用session.createQuery()方法接受一个HQL语句,然后调用Query的list()或uniqueResult()方法执行查询。所谓HQL是(Hibernate Query Language)缩写,其语法很像SQL语句,但他是完全面向对象的。
在Hibernate中使用Query对象的步骤,具体所示:
- ① 获得Hibernate的Session对象;
- ② 编写HQL语句
- ③ 调用session.createQuery创建查询对象。
- ④ 如果HQL语句包含了参数,则调用Query的setXxx设置参数。
- ⑤ 调用Query对象的list方法或者uniqueResult()方法执行查询。
- 了解了使用Query对象的步骤以后,接下来,通过具体的示例演示Query对象的查询操作:
Criteria是一个完全面向对象,可扩展的条件查询API,通过它完全不需要考虑数据库底层如何实现,以及SQL语句如何编写,他是Hibernate框架的核心查询对象。Criteria查询,又称QBC查询(Query By Criteria),他是Hibernate的另一种对象检索方式。
org.hibernate.criterion.Criterion是Hibernate提供的一个面向对象查询条件接口,一个单独的查询就是Criterion接口的一个实例,用于限制Criteria对象的查询,在Hibernate中Criterion对象的创建通常是通过Restrictions工厂类完成的,它提供了条件查询的方法。
通常,使用Criteria对象查询数据的主要步骤,具体步骤如下:
- ① 获得Hibernate的Session对象。
- ② 通过Session获得Criteria对象。
- ③ 使用Restrictions的静态方法创建Criterion条件对象。Restrictions类中提供了一系列用于设定查询条件的静态的方法,这些静态方法都返回Criterion实例,每个Criterion实例代表一个查询条件。
- ④ 想Criteria对象中添加Criterion查询条件,Criteria的add()方法用于加入查询条件。
- ⑤ 执行Criteria的list()方法或者uniqueResult()获得结果。
了解了Criteria对象使用的步骤后,接下来,通过具体的实例来演示Criteria对象的查询操作。

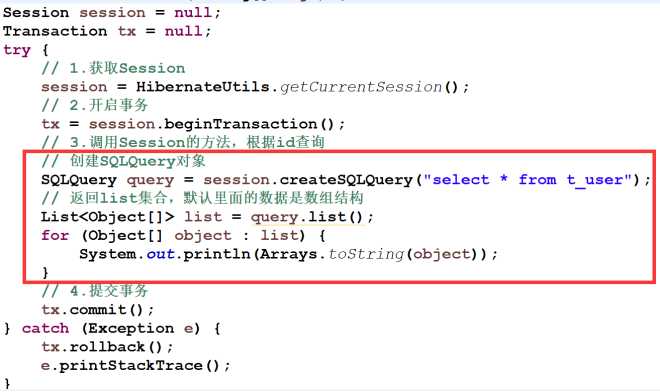
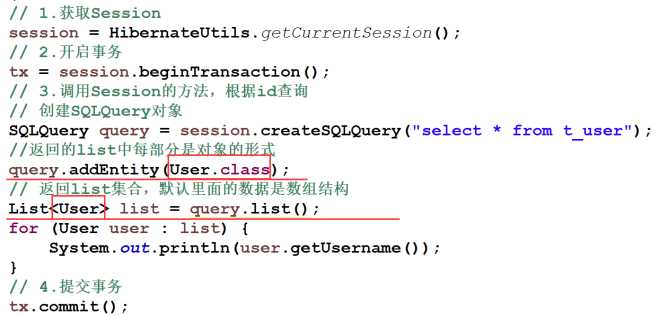
SQLQuery这个方法就比较简单了,这个借口用于接收一个SQL语句进行查询,然后调用list()方法或者uniqueResult()方法进行查询。但是SQL语句不会直接封装到实体对象中,我们需要手动写代码才可以封装到实体中。
把数组转换成集合对象:
- ① 设置addEntity指定某个类
- ② 泛型集合可以直接指定对象类型
- ① 一对多(客户联系人)
- ② 多对多(用户和角色)
- ① 一对多映射配置
- ② 一对多级联保存
- ③ 一对多级联删除
- ④ inverse属性
- ① 多对多映射配置
- ② 多对多级联保存(重点)
- ③ 多对对级联删除
- ④ 维护第三张表
- ① 商品的类型和商品的关系,一个分类里面可以有多个商品,一个商品,只能属于一个分类。
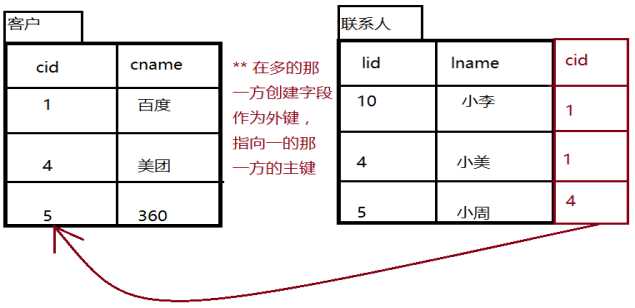
- ② 客户和联系人,是一对多的关系(公司和员工的关系)
- 客户:与公司有业务往来,如:百度,腾讯
- 联系人:公司里面的员工,比如:百度里面有很多的员工,联系员工
- 一个客户里面有多个联系人,一个联系人,只能属于一个客户。
- ③ 一对多建表:通过建立主外键关系来实现
- 
- ① 订单和商品的关系,一个订单里面有多个商品,一个商品可以属于多个订单。
- ② 用户和角色多对多的关系
- 用户:小马,小周,小雷
- 角色:司机,保安、经理,总监,总经理
- 比如:小马可以是经理,也可以是司机;小周可以是总监,也可以是保安
- 一个用户可以有多个角色,一个角色可以有多个用户
- ③ 多对多建表,创建第三张表来维护多对多的关系
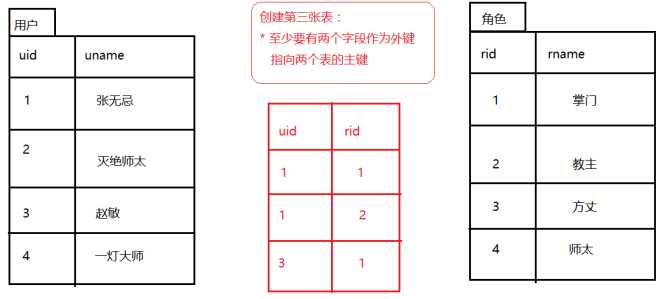
- ① 在中国,一夫一妻制。(合法的:一个男人只能有一个妻子,一个女人只能有一个丈夫)
客户和联系人:
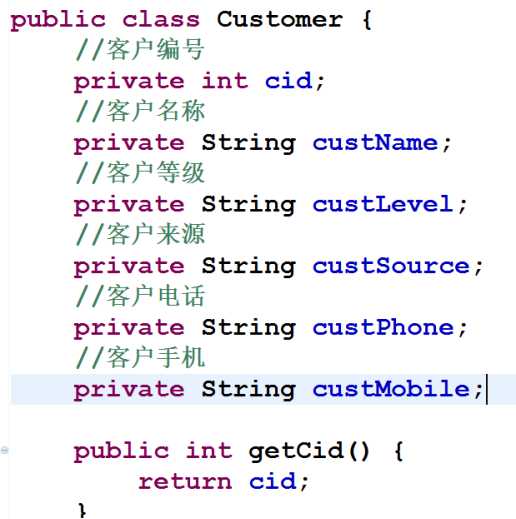
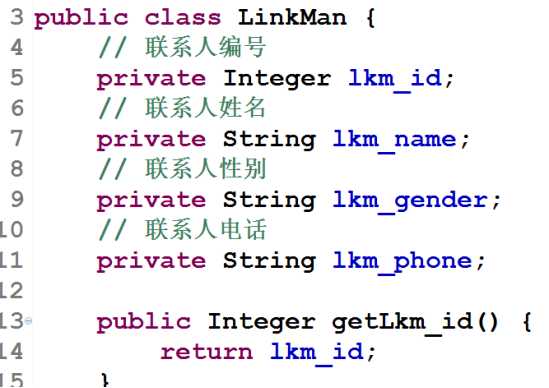
2.让两个实体类之间互相表示
- ① 在客户实体类里面表示多个联系人(一个客户有多个联系人)
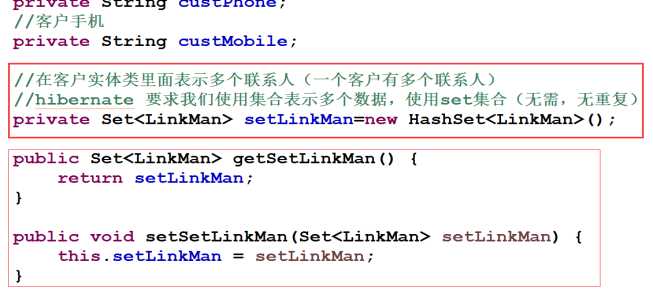

3.配置映射关系
- ① 一般一个实体类对应一个映射文件
- ② 把映射文件最基本的内容配置完成


- ③ 在映射文件中,配置一对多的关系
在客户的映射文件中,表示所有的联系人,在Customer.hbm.xml添加如下配置:

- 在联系人的映射文件中,表示所属客户,在LinkMan.hbm.xml中添加如下配置:
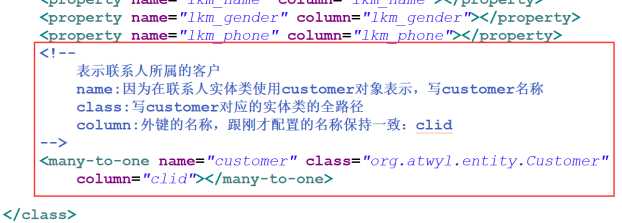
④ 创建核心配置文件,把映射文件引入到核心配置文件中去,代码如下:

- ⑤ 把核心配置文件里面的数据库的配置改一下,新建一个数据库,清晰明了:

- ⑥ 测试:在工具类里面写一个空的main方法,直接运行,查看数据库:
级联操作:
- 例如有两张表:部门表和雇员表,一个部门有很多的雇员,例如我添加一个部门的同时就添加了该部门下的若干雇员,这就是级联保存,涉及到两张表或者多张表。
- 再例如,我添加了一个客户,同时为这个客户添加了若干个联系人,这是级联保存。
- 例如,有两张表:部门表和雇员表,当我删除某个部门的同时,该部门下所有的雇员都会被删除,这就是级联删除。
- 再例如:我删除一个客户,我把该客户下所有的联系人都删除,这是级联删除。
SessionFactory sessionFactory = null; Session session = null; Transaction tx = null; try { // 1.调用工具类得到SessionFactory sessionFactory = HibernateUtils.getSessionFactory(); // 2.获取Session session = sessionFactory.openSession(); // 3.开启事务 tx = session.beginTransaction(); // 4.具体操作 Customer customer=new Customer(); customer.setCustLevel("VIP"); customer.setCustMobile("13890908989"); customer.setCustName("李寻欢"); customer.setCustPhone("68687889"); customer.setCustSource("网络"); LinkMan linkMan=new LinkMan(); linkMan.setLkm_gender("男"); linkMan.setLkm_name("司空摘星"); linkMan.setLkm_phone("18790899878"); // 客户里面表示所有联系人,在联系人表示客户 // 建立客户对象和联系人对象之间的关系 // 1.把联系人的对象,放到客户实体类对象的set集合里面 customer.getSetLinkMan().add(linkMan); // 2.把客户对象放入联系人里面去 linkMan.setCustomer(customer); // 3.保存到数据库 session.save(customer); session.save(linkMan); // 5.提交事务 tx.commit(); } catch (Exception e) { tx.rollback(); e.printStackTrace(); } finally { // 6.关闭 session.close(); sessionFactory.close(); }
简化写法
- 根据客户添加联系人
- ① 在客户映射文件中进行配置,在客户映射文件里面有一个set标签,在set标签里面进行配置:加上cascade=””save-update”

- ② 常见客户和联系人对象,只需要把联系人放到客户里面就可以了,最终只需要保存客户就可以了:
//其他步骤同上
Customer customer=new Customer();
customer.setCustLevel("普通客户");
customer.setCustMobile("13890908888");
customer.setCustName("雕爷牛腩");
customer.setCustPhone("68687881");
customer.setCustSource("网络");
LinkMan linkMan=new LinkMan();
linkMan.setLkm_gender("男");
linkMan.setLkm_name("宁采臣");
linkMan.setLkm_phone("18990899878");
// 1.把联系人的对象,放到客户实体类对象的set集合里面
customer.getSetLinkMan().add(linkMan);
// 2.保存到数据库
session.save(customer);
- ① 在客户的映射文件中有个set标签,进行配置

- ② 直接写删除代码即可
- 根据id查询一个对象,调用session里面delete方法进行删除
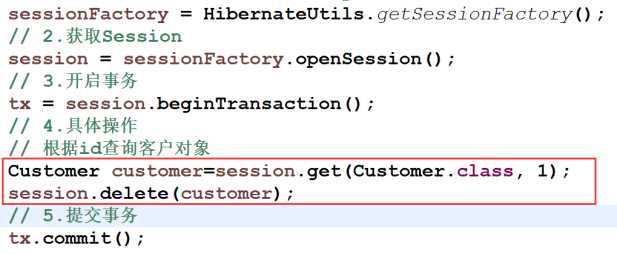
我们查看刚才那个修改,我们发现生成了两个update语句,就是把LinkMan修改了两次,这样以来会使得我们的程序的性能收到影响。
为什么会改两次?
Hibernate双向都维护外键,一的一方维护了外键,多的一方也维护了外键,所以就修改了两次。
解决的方法:可以让其中的一方不维护外键,保证双方有一方维护外键。
- 一对多的里面,我们可以其中的一方放弃外键的维护,一般让一的哪一方放弃维护外键。
- 举例:一个国家有一个主席,国家有很多的人,主席跟很多人之间,是一对多的关系,主席不可能认识国家里所有的人,国家里所有的人,都认识主席。好,我们可以理解为:主席放弃维护外键的关系,把关系交给了多的一方去维护。(这就是让一的一方放弃关系维护)。
- 具体实现:在放弃维护的那一方,也就是一的一方的配置文件,Customer.hbm.xml里面进行配置,在set标签里面使用inverse属性

以用户和角色为例,演示效果
- ① 一个用户里面表示所有的角色,使用set集合,生成get和set方法
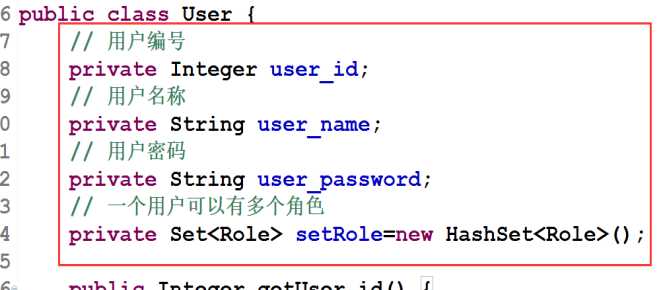
- ② 一个角色中有多个用户,使用set集合,生成get和set方法

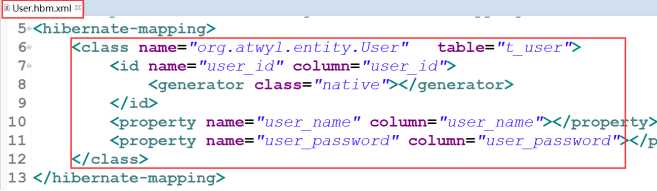
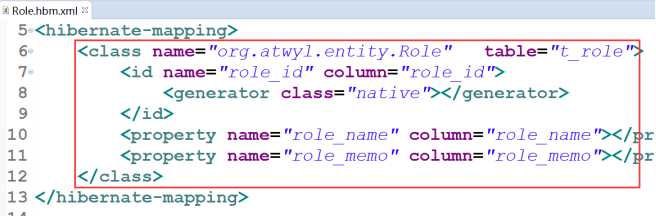
1.配置映射关系
- ① 基本配置
- ② 多对对的关系
(1)在用户里面表示所有的角色,使用set标签
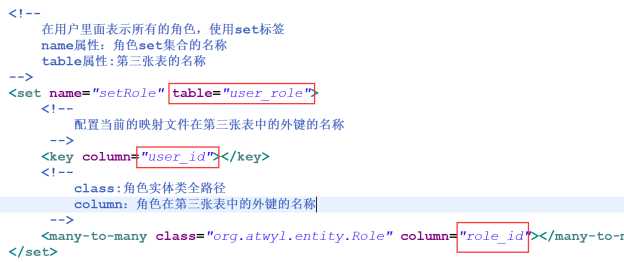
(2)在角色里面表示所有的用户,使用set标签

4.在核心配置文件中,引入映射文件

1.测试
- ① 我们把t_user表删除,然后进行测试,我们工具类里面有main方法,我们直接运行工具类,然后查看效果:
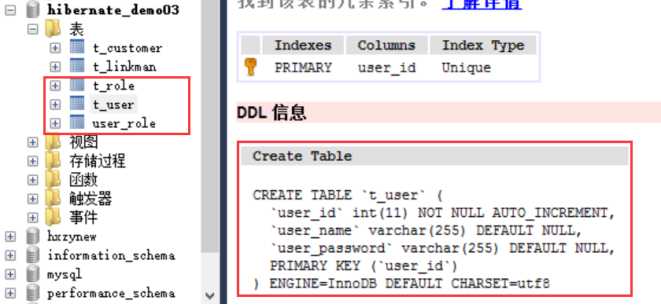
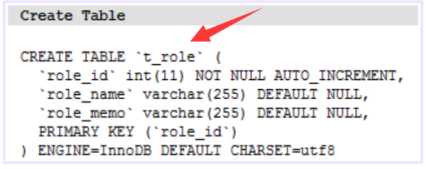
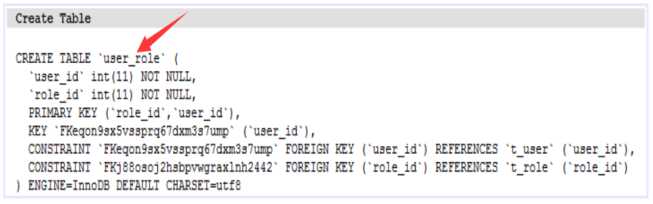
对对多的级联保存
- ① 创建用户和角色的对象,把角色放到用户里面去,最终保存用户即可,代码如下:

// 4.具体操作,多对多的级联保存 // 实例化User对象一 User user1 = new User(); user1.setUser_name("乔灵儿"); user1.setUser_password("123123"); // 实例化User对象二 User user2 = new User(); user2.setUser_name("白莲花"); user2.setUser_password("123123"); // 实例化Role对象一 Role role1 = new Role(); role1.setRole_name("总经理"); role1.setRole_memo("总经理"); // 实例化Role对象二 Role role2 = new Role(); role2.setRole_name("秘书"); role2.setRole_memo("秘书"); // 实例化Role对象三 Role role3 = new Role(); role3.setRole_name("司机"); role3.setRole_memo("司机"); // 建立关系,将角色添加到用户的角色集合中 user1.getSetRole().add(role1);//乔灵儿是总经理 user2.getSetRole().add(role2);//白莲花是秘书 user2.getSetRole().add(role3);//白莲花是司机 // 调用方法进行保存 session.save(user1); session.save(user2); // 5.提交事务 tx.commit();

2.删除用户

- 这样删除会有问题,它会把角色删掉,假如,小明的角色是秘书和司机的角色,删除小明时,会把秘书和司机这两个角色都删掉,但是如果小红是司机和保安,怎么办呢,司机已经被删除了,所以这种删除我们基本不用。
- ① 先根据id查询出用户和角色
- ② 直接把角色放入用户里面去(把角色对象放到用户的set集合里)
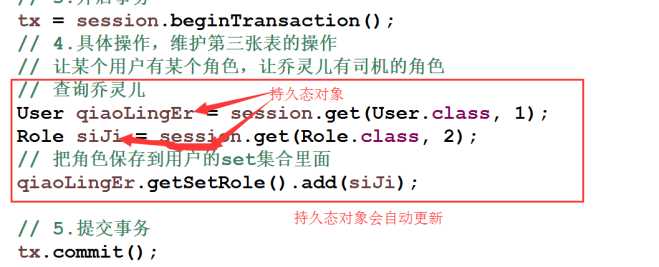
3.让某个用户没有某个角色
- ① 根据id查出用户和用户角色
- ② 从用户角色里面把角色去掉(从set集合里面把角色移除,remove()方法)

标签:数组 art comm pen 识别 单列 加载 java 技术
原文地址:https://www.cnblogs.com/sxw123/p/12749629.html